巧用Sqlite3加速数据库
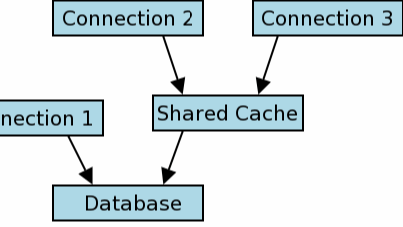 SQLite Share-Cache Mode,内存共享模式,读写分离,提升数据库性能
SQLite Share-Cache Mode,内存共享模式,读写分离,提升数据库性能
当遇到大量高频字段需要更新时候,数据库CPU分分钟飚起来,吓得定时任务都不敢运行了。连上数据库,人工掐表执行下
MariaDB [AAAA]> show global status like 'Question%';
+---------------+---------+
| Variable_name | Value |
+---------------+---------+
| Questions | 5025774 |
+---------------+---------+
1 row in set (0.00 sec)
两数相减,原来还真是查询过多导致。仔细分析了下,查询来源:
- 通过联合字段锁定记录
- 更新记录属性,回写数据库
更新可以批量,不过资源锁定是个问题。有人说直接莽,全拉倒内存,自己一条条匹配,反正内存也不会很慢。但是几万条记录,又不是kv,多字段匹配,每次找到一条数据也是难度很大。带着这个问题,sqlite3 in memory 闪亮登场!
以Django为例,多数据库配置如下:
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 'name',
'USER': 'user',
'PASSWORD': 'password',
'HOST': '127.0.0.1',
'PORT': '3306',
},
'memory': {
'ENGINE': 'django.db.backends.sqlite3',
# :memory: 属于独占,单进程内多线程无法共享
'NAME': 'file:memDB1?mode=memory&cache=shared',
'uri': True,
}
}
内存表无法储存表结构,每次都要初始下,mysql 与 sqlite3 结构并不一样,因此我采用的是先用文件,然后导出sql
sqlite3 db.sqlite3
sqlite> .output tmpl.sql
sqlite> .dump
sqlite> .exit
然后定时任务执行前,初始化表结构
from django.db import connections
@classmethod
def init_cache(cls):
path = '../sql/tmpl.sql'
cache_con = connections['memory']
with cache_con.cursor() as cursor:
with open(path) as fp:
for sql in fp.readlines():
cursor.execute(sql)
@classmethod
def init_table(cls, *args):
for model in args:
objs = model.objects.all()
logger.info("同步表结构: %s 总共: %s 进入cache" % (model, len(objs)))
model.objects.using("memory").bulk_create(objs, batch_size=1000)
上述逻辑,只要在定时任务启动时初始化一次,就可以快照一波指定数据到内存。由于API实例是直接查询数据库,cache只有自身使用,那么读写分离前提就够了。简单逻辑我们可以直接这么写也不卡:
objs = []
for item in data['data']['result']:
flag = item['metric']['disk']
instance = item['metric']['instance']
ip = instance.split(":")[0]
disk = Disk.objects.using("memory").filter(host__ip=ip, flag=flag).first()
if not disk:
logger.warning("硬盘<%s-%s>不在数据库中" % (ip, flag))
continue
value = item['value'][-1]
disk.io_usage = value
objs.append(disk)
Disk.objects.using("default").bulk_update(objs, ("io_usage",), batch_size=500)
从Prometheus中读取硬盘IO使用率,先去cache中锁定model,更新字段,然后合并更新到数据库中。记住,这里一定要指定更新字段,这样cache的作用就只是查主键拼SQL,而不用手动生成,简洁明了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号