
date:2018414+2018415 day1+2
一.python基础
#coding=utf-8
#注释
#算数运算 +(加) -(减) *(乘) /(除) //(取整) %(取余)
#比较运算 <(小于) >(大于) ==(等于) !=(不等于)
#逻辑运算 and or not
#查看变量类型 type()
#raw_input 使用raw_input方法去输入时,变量里面存的数据都是字符串类型
#逗号是不换行打印,把所有的变量强制显示在一行
#input 只接受0-9 .的输入(python3还如此?)
二.if、for、while
#if
单分支

双分支

多分支

#for



#break 结束循环,多个嵌套时break只对最近的一层循环起作用 continue 结束本次循环
#while

三.格式化输出
# %d:整型 %s:字符串 %f:浮点型

四.字符串
# \ 续行符
# len(x)=x.__len__()
#从前往后数,0开始;从后往前数,-1开始
#获取多个字符

#字符串拼接

#字符串切割

#字符串查找

#字符串计数+字符串转大小写

#字符串遍历+字符串判断

#在utf-8模式下,中文占3位 其他编码占2位
# print x[::-1] 逆序输出
#字符串替换

#总结 字符串是不能够增加 不能删除 不能修改 不能存储其他类型的数据
五.列表 list [a,d,"ASD"]
#列表具有 增加 删除 修改 查询功能
增加:

插入:

删除:

修改:

#正序、倒序
正序:

倒序:

#获取索引 index()

六.元祖 tuple ()
#元组不能增加 不能修改 不能删除
#元祖嵌套

七.字典 dict {}
#字典是映射关系,一一对应
#字典由key和value组成;两两一对,逗号隔开
#字典可以存储任意长度 任意类型
#字典的key必须是不可变类型(元组 数字 字符串),value任意类型
#字典是无序的,没有下标
#字典所有的操作 都是去操作key
#增加 修改 删除 取value 遍历


八.集合
set是一个无序且不重复的元素集合。
set和dict一样,只是没有value,相当于dict的key集合,由于dict的key是不重复的,且key是不可变对象因此set也有如下特性:
1. 不重复
2. 元素为不可变对象
创建set:
本身使用 {} 进行创建,如果 {}里面没有元素,默认表示 dict类型,也就是创建空元素的set集合,不能用{};
如果要创建一个空元素的set,使用 set();
使用{} 里面可以数值型、字符串、元组, 不可以用字典和集合,里面可以放多个元素.
如果使用 set,因为set需要对里面的元素做遍历循环,做去重操作,做无序排列,所以要求元素必须可遍历,所以里面可以使用字符串、元组、集合、字典
{}里面不能用 list集合、set里面不能用数值型
九.Tips
可更改对象:list dict
不可更改对象:Int String tuple
可变/不可变类型,指的是:内存id不变,type也不变的前提下,value是否是可变的。
不可变:只要改变变量的值,如果变量的地址发生了改变,则认为是不可变 int,str,float,bool,tuple
可变:变量的内部无论发生怎样的改变,地址都不发生改变,则认为是允许改变,(可变) list set dict
&&&&&&&&&&&&&&&&&&&&&&&&xxxxx·xx&&&&&&&&&&&&&&&&&&&&&&&&
date:2018422 day4
一.模块
模块是函数方法的集合,在python中,一个py文件也是模块
python模块有两种:第一种是安装python自带的内置模块,比如time,os,urllib2 路径为c:\python27\lib;
第二种是需要安装的第三方模块,路径为c:\python27\lib\site-packages
①.excel读写
写(cmd→【pip install xlwt】)
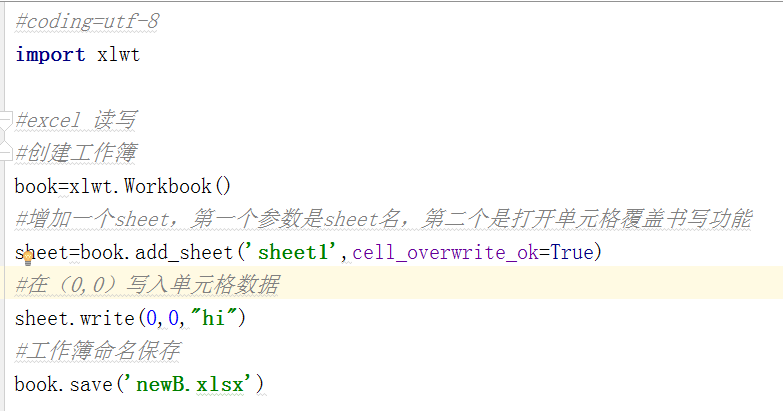
读(cmd→【pip install xlrd】)

UTF-8解码(decode)→Unicode→编码gbk
Unicode→编码(decode)gbk
Unicode→编码(decode)UTF-8
②.读写二进制

③.导入
1.导入模块

2.导入模块方法

3.导入多个
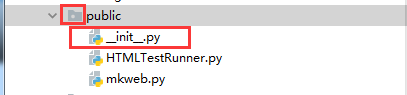
4.自定义模块
当自定义模块想被别人调用时,需在当前目录下创建一个__init__.py(自定义模块能被导入时,文件夹上会有一个空心圆出现,如下图)
不同层级目录的模块导入要从包开始

④.系统模块(如os,time 不需要pip)
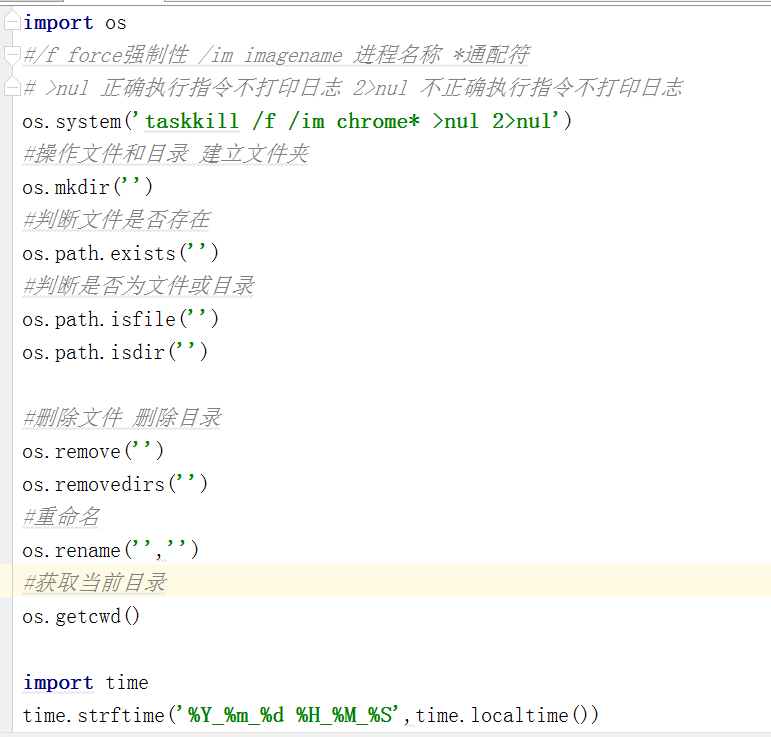
taskkill /f /im chrome* >nul 2>nul
/f force强制性 /im imagename 进程名称 *通配符
>nul 正确执行指令不打印日志 2>nul 不正确执行命令不打印日志
二.异常

************************************************************************************************************************
date:2018421 day3
一.函数定义
def 函数名(首字母大写)
增加程序可读性
#直接写函数名即可调用函数
#参数
①.形参

②.实参

③.缺省参数
如果有默认值,调用的时候没有传递参数,就会使用默认值;如果传递了参数,就使用新的数据
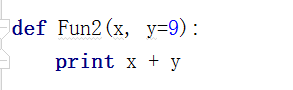
#函数定义了几个参数,调用的时候就要传递几个参数;函数的参数传递是有顺序的(如果按照赋值表达式来传递,就不需要按照顺序,如【 Fun(a=1,b=2)/ Fun(b=2,a=1)】)
#函数必须要return,而不是print
#一个函数可能有多个return;一次return多个值,返回的多个值是以元祖形式返回
#变量作用域 作用范围
①.局部变量
函数内部的变量属于局部变量,作用范围是函数内部。

②.全局变量

#高级参数
①.可选参数,定义函数不清楚需要多少参数 返回的是元祖数据

②.**接受赋值表达式,返回字典

二.文件读写
1.写文件
#写了文件名,那么文件创建在 脚本的同级目录
#.代表当前目录,那么文件创建在 脚本的同级目录
#..代表上级目录

追加写入

2.读文件

#读取行

#读取多行,不读取换行符

#指定读取某一行

三.文件修改
#首先读取数据,再修改数据,最后写入数据

四.二进制文件读取写入


获取当前文件夹所在路径:
import os
basepath = os.path.dirname(__file__)
拼接路径:
filepath = os.path.join(basepath,"data.txt",filename)
函数体内部的语句在执行时,一旦执行到return时,函数就执行完毕,并将结果返回
列表生成式:
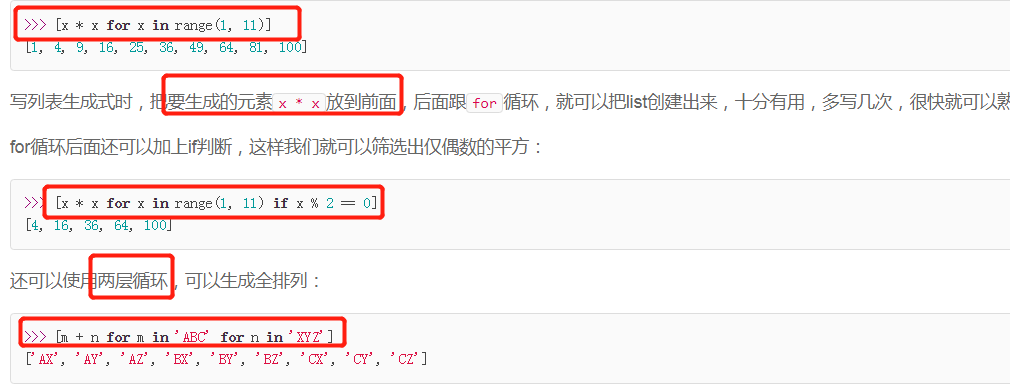
map()函数接收两个参数,一个是函数,一个是Iterable,map将传入的函数依次作用到序列的每个元素,并把结果作为新的Iterator返回。
a=[1,2,3,4,5,6]
list(map(lambda x:x+1,a))
reduce把一个函数作用在一个序列[x1, x2, x3, ...]上,这个函数必须接收两个参数,reduce把结果继续和序列的下一个元素做累积计算
from functools import reduce
reduce(lambda x,y:x+y,[2,3,4],1)
filter()把传入的函数依次作用于每个元素,然后根据返回值是True还是False决定保留还是丢弃该元素。da
a=[1,2,3,4,5,6]
list(filter(lambda x:x>2,a))
sorted()函数就可以对list进行排序
关键字lambda表示匿名函数,冒号前面的x表示函数参数。
匿名函数有个限制,就是只能有一个表达式,不用写return,返回值就是该表达式的结果。
lambda x,y:x+y
在面向对象(OOP)的设计模式中,decorator被称为装饰模式。OOP的装饰模式需要通过继承和组合来实现,而Python除了能支持OOP的decorator外,直接从语法层次支持decorator。Python的decorator可以用函数实现,也可以用类实现。decorator可以增强函数的功能,定义起来虽然有点复杂,但使用起来非常灵活和方便。
Python允许在定义class的时候,定义一个特殊的__slots__变量,来限制该class实例能添加的属性
把一个getter方法变成属性,只需要加上@property就可以了,此时,@property本身又创建了另一个装饰器@score.setter,负责把一个setter方法变成属性赋值
装饰器(decorator)可以给函数动态加上功能。对于类的方法,装饰器一样起作用。Python内置的@property装饰器就是负责把一个方法变成属性调用的
五、爬虫相关
1.爬虫 WHAT
通过程序模拟浏览器请求站点的行为,把站点返回的HTML代码/JSON数据/二进制数据(图片/视频)爬到本地,进而提取自己所需的数据,存放起来使用。
2.爬虫 WAY
获取网络数据的方式:
①.浏览器提交请求→下载网页代码→解析成网页
②.模拟浏览器发送请求(获取网页代码)→提取有用的数据→存放在数据库或文件中 [爬虫所要做的]
发送请求→获取响应内容→解析内容→保存数据
发送请求
使用http库向目标站点发起请求,即发送一个Request
Request包含:请求头、请求体等
Request模块缺陷:不能执行JS和CSS代码
获取响应内容
服务器正常响应,则会得到一个Responce
Response包含:html,json,图片,视屏等
解析内容
解析html数据:正则表达式(RE模块),第三方解析库如Beautifulsoup,pyquery等
解析json数据:json模块
解析二进制数据:以wb的方式写入文件
保存数据
数据库(MySQL,Mongdb,Redis)
3.爬虫 WHY
Request:用户将自己的信息通过浏览器(socket client)发送给服务器(socket sever)
Response:服务器接收请求,分析用户发来的请求信息,然后返回数据
浏览器在接收到Responce后,会解析其内容来显示给用户,而爬虫程序在模拟浏览器发送请求然后接收Response后,是要提取其中有用的数据。
Request{
①.请求方式(常见的):GET/POST
②.请求的URL:url全球统一资源定位符,用来定义互联网上的一个唯一的资源,如一张图片、一个文件、一段视频都可以用url唯一确定
网页加载过程:加载一个网页,通常都是先加载document文档,在解析document文档的时候,遇到链接,则针对超链接发起下载图片的请求
③.请求头(一般爬虫都会加上请求头):
User-agent:请求头中如果没有user-agent客户端配置,服务器可能将你当作一个非法用户host;
cookies:cookies用来保存登录信息
请求头需要注意的参数:
1.Referrer:访问源哪里来的(一些大型网站,会通过Referrer做防盗链策略,所有爬虫也要注意模拟)
2.User-agent:访问的浏览器(要加上否则会被当成爬虫程序)
3.cookie:请求头注意携带
④.请求体
如果是get方式,请求体没有内容(get请求的请求体放在url后面参数中,直接能看到)
如果是post方式,请求体是format data
ps:登录窗口、文件上传等,信息都会被附加到请求体内;登录,输入错误的用户密码,然后提交,就可以看到post,正确登录后页面通常会跳转,无法捕捉到post
⑤.响应Response
1.响应状态码:
202:代表成功
301:代表跳转
404:文件不存在
403:无权限访问
502:服务器错误
2.response header
响应头需要注意的参数:
Set-Cookies:BDSVRTM=0;path=/:可能有多个,是来告诉浏览器,把cookie保存下来
Content-Location:服务端响应头中包含Location返回浏览器之后,浏览器就会重新访问另一个页面
Preview就是网页源代码 JSON数据 如网页html,图片 二进制数据等
}
4.爬虫 总结
爬虫流程:爬取→解析→存储
爬虫所需工具:
请求库:request,selenium
解析库:正则,beautifulsoup,pyquery
存储库:文件,MySQL,Mongdb,Redis
Python数据库操作:
一.mysql操作
1.数据库的连接
前置条件:服务器ip 端口号 用户名 密码 数据库名
安装第三方库:MySQLdb(运行MySQL-python-1.2.5.win32-py2.7.exe)
2.创建数据库
a.连接数据库,创建数据库库名

b.创建表,插入数据(插入数据要有commit)

c.查询数据、修改数据(修改数据也要commit)

d.删除数据库 drop database db1
e.以函数形式操作数据库

二.oracle操作
1.安装第三方库cx_oracle
运行msi文件(cx_Oracle-5.1.2-11g.win32-py2.7.msi);然后将instantclient_11_1.rar解压,将文件夹内的8个以dll为后缀的文件复制粘贴至X:\Python27\Lib\site-packages内
2.操作数据库(oracle没有database)

三.Tips
1.各种端口号
mysql:3306
oracle:1521
apache:80
ftp:21
telnet:23
tomcat:8080
ssh:22
什么是“堆”,"栈","堆栈","队列",它们的区别
堆、栈、队列之间的区别是?
①堆是在程序运行时,而不是在程序编译时,申请某个大小的内存空间。即动态分配内存,对其访问和对一般内存的访问没有区别。
②栈就是一个桶,后放进去的先拿出来,它下面本来有的东西要等它出来之后才能出来。(后进先出)
③队列只能在队头做删除操作,在队尾做插入操作.而栈只能在栈顶做插入和删除操作。(先进先出)
函数与方法的区别
函数(function)是可以执行的javascript代码块,由javascript程序定义或javascript实现预定义。函数可以带有实际参数或者形式参数,用于指定这个函数执行计算要使用的一个或多个值,而且还可以返回值,以表示计算的结果。【函数名(参)】
方法(method)是通过对象调用的javascript函数。也就是说,方法也是函数,只是比较特殊的函数。假设有一个函数是fn,一个对象是obj,那么就可以定义一个method【对象名.方法名()】
类中的函数称为方法。
函数是一段代码,通过名字来进行调用。它能将一些数据(参数)传递进去进行处理,然后返回一些数据(返回值),也可以没有返回值。
所有传递给函数的数据都是显式传递的。
方法也是一段代码,也通过名字来进行调用,但它跟一个对象相关联。方法和函数大致上是相同的,但有两个主要的不同之处:
- 方法中的数据是隐式传递的;
- 方法可以操作类内部的数据(请记住,对象是类的实例化–类定义了一个数据类型,而对象是该数据类型的一个实例化)
以上只是简略的解释,忽略了作用域之类的问题。
********************************************************************************************************************************************************************
一.面向对象编程
1.定义类,类的继承
ps:与普通函数相比,在类中定义的函数第一个参数必须是类的本身实例变量self,在调用时,该参数不用传值

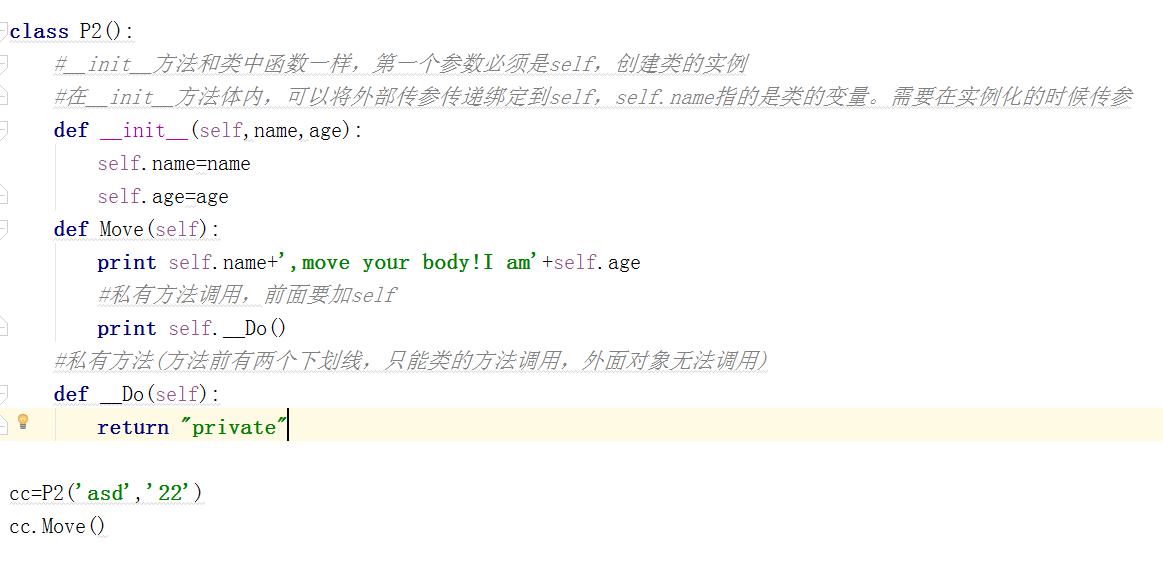
2.__init__方法+私有方法
__init__存在的意义:类中有必须要绑定的属性,可以使用python的内置方法__init__
__init__方法无需调用,创建类的实例时自动调用
__init__方法和类中函数一样,第一个参数必须是self,创建类的实例在__init__方法体内,可以将外部传参传递绑定到self,self.name指的是类的变量。需要在实例化的时候传参。
私有方法(方法前有两个下划线,只能类的方法调用,外面对象无法调用);类中私有方法调用,前面要加self
3.if __name__ == '__main__'
通俗的理解__name__ == '__main__':假如你叫小明.py,在朋友眼中,你是小明(__name__ == '小明');在你自己眼中,你是你自己(__name__ == '__main__')。
if __name__ == '__main__'的意思是:当.py文件被自己直接运行时,if __name__ == '__main__'之下的代码块将被运行;当.py文件以模块形式被导入时,if __name__ == '__main__'之下的代码块不被运行。
如果模块是被导入的,代码块(__name__ == '__main__')下的代码不会被运行;
如果模块是直接运行,代码块(__name__ == '__main__')下的代码会被运行。
参考链接:http://blog.konghy.cn/2017/04/24/python-entry-program/
闭包理解为一种特殊的函数,这种函数由两个函数的嵌套组成,且称之为外函数和内函数,外函数返回值是内函数的引用,此时就构成了闭包。
[Python小记] 通俗的理解闭包 闭包能帮我们做什么?
