

第七章:集成学习(利用AdaBoost元算法...)
---恢复内容开始---
集成学习其实不能算一个算法,应该算是一种框架,集百家之长。集成算法具体有Bagging与Boosting两种大类。两者区别:
1)Bagging是并行的,它就好比找男朋友,美女选择择偶对象的时候,会问几个闺蜜(几个算法)的建议,最后选择一个综合得分最高的一个作为男朋友。bagging中目前最流行的是随机森林;
Boosting是串行的,它就好比追女友,3个帅哥追同一个美女,第1个帅哥失败->(传授经验:姓名、家庭情况) 第2个帅哥失败->(传授经验:兴趣爱好、性格特点) 第3个帅哥成功。boosting中目前比较流行的是AdaBoosting.
2)Bagging是几个不同的分类器都决策后,对结果进行投票决定(票数多的),或者取平均等等。这里不同的分类器有两种方法产生,第一,用不同的算法,比如一个用决策树,一个用kNN;第二,相同的算法,比如都是决策树,但是训练集不同,也就是说每次从训练集中抽不同的部分给不同的分类器模型去训练。这样又有两种情况,一种是有放回的抽取,一种是无放回的抽取。一般用第二种方法。
Boosting是几个分类器串行训练,Bagging中训练集的权重是相同的,但是Boosting中是不同的。第一个分类器训练后,将错误的训练集中错误的部分进行加大权重。依此类推,其实它就是不断改变将训练集分块(对错分块),改变权重。
下面主要介绍随机森林与AdaBoosting算法。
随机森林(random forest,RF)其具体原理与自写模块看这里。下面主要说一下用sklearn中的随机森林模块:
还是与前几章一样用iris数据集分类举例,(ps:sklearn中不仅有随机森林分类模块RandomForestClassifier,也有回归RandomForestRegressor,调参参不多):


调试时发现,这里的参数n_estimators=150对结果影响很大很大,而且就算是相同的参数,这次运行结果准确率是100%,下一次说不定是95%。下面具体说一下RandomForestClassifier()中的参数。




下面是AdaBoosting的介绍,具体的自写模块与原理看这里,下面用sklearn中的AdaBoosting解决书中病马预测的例子:

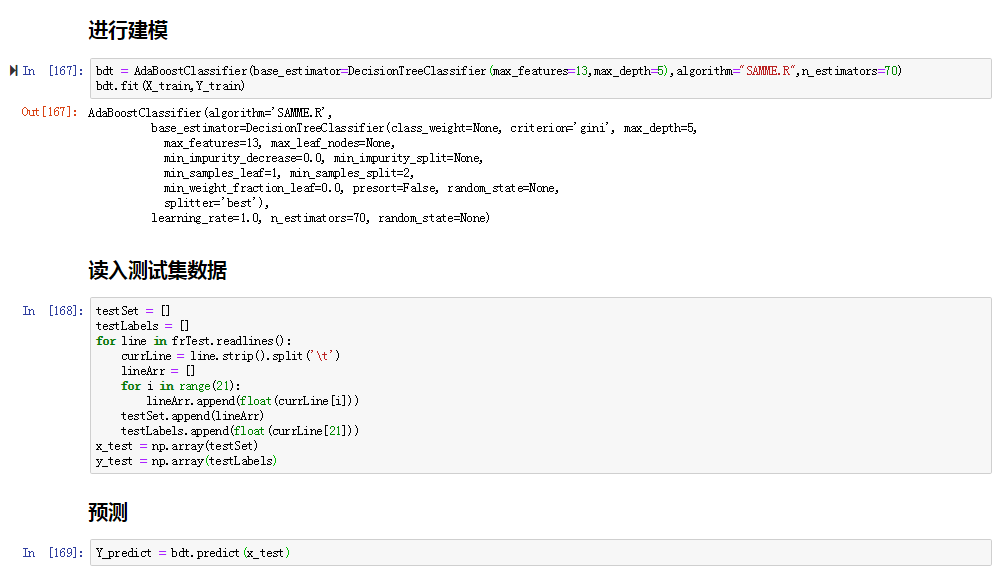
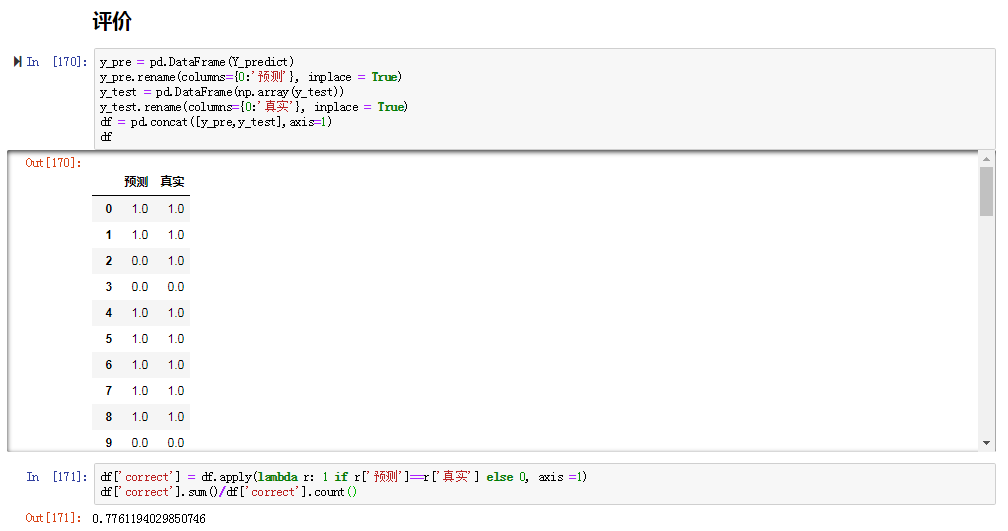
结果与逻辑回归那一章的结果差不多,不过这里参数比较难调。AdaBoostClassifier()函数中有五个参数要调,第一个参数base_estimator如果选择决策数DecisionTreeClassifier,它里面又有好几个参数。具体调参与介绍可以看这里。
补充一下:
书中最后不了一个非均衡分类问题(在分类器训练时,正例数目和反例数目不相等(相差很大)或者发生在正负例分类错误的成本不同的时候。)怎么办?看这里
---恢复内容结束---

 浙公网安备 33010602011771号
浙公网安备 33010602011771号