统计学习笔记-李连江 让每一个文科生都成为统计高手
李连江 让每一个文科生都成为统计高手
第一部分:数据与量化:信息点与信息库
P4
- 统计-由此及彼(样本到总体),分析-从可见到不可见。
- 样本的属性叫样本统计值(认知手段),总体的属性叫总体参数(认知目的)。
- 概率样本:总体的每个成员有相同的被抽入样本的概率。
P5
- Variable:变项,因人而异的变。
- Relevant:利害相干(应变项依据 )、因果相干(自变项依据)。
P7
-
统计分析是实验的代用品,有些事件无法做实验。
第二部分:单变项分析:由点到线
P8
-
正太分布:1.是正常分布,自然分布 2.正态分布是一种世界观(凡事皆有可能,只是出现概率无限小)
-
方差:与平均值的偏离程度
-
标准差是描述观察值(个体值)之间的变异程度(例如一个人打十次靶子的成绩,这时有一个平均数8,有一个反映他成绩稳定与否的标准差);
-
标准误是描述样本均数的抽样误差(例如十次抽样,每次他成绩平均数(7,8,6,9,5,6,7,7,8,9)的标准差,也就是抽样分布的标准差);
第三部分:双变项分析:由线到面
P12
-
相关分析:正/负相关、曲线相关(工作压力Vs工作表现)、强/弱相关
-
随机相关与系统相关:显著性检验
-
显著度检验的六步:
1.研究假设H1:假设有显著度关系
2.零假设H0
3.根据变量类型选择检验方法
4.决定愿意承担多大的犯一类错误的风险。
一类错误:弃真,H0假设为真放弃H0
二类错误:纳伪,H0假设为假接受H0
5.根据样本计算犯一类错误的风险
6.参照4-5步决定是否放弃零假设P17/18/19/20回归分析是预设因果关系的相关分析:
1.正太分布时平均值是最准的猜测
2.回归分析是根据自变量更准地猜因变量
3.最小二乘回归就是把猜测准确度最大化
未标准化相关系数:保留原单位
标准化相关系数:
4.回归分析的显著性检验与法庭审判类似第四部分:多变项分析:由面到体
P21/22 第1讲 多元回归分析
1.一果多因
2.净(偏)回归系数
3.多元回归系数是合力:要培养空间想象能力
4.判定系数告诉我们合力的威力P22 第2讲 排除似是而非的因素:统计控制
控制就是排除干扰
共线性问题:自变量之间有相关P23/24/25 第3讲 因子分析和量表构造
社会学、政治学绝大多数因变量都不是连续的。
1.不能直言相询只能旁敲侧击
2.因子分析是利用回归分析提高测量精度。有较强的相关性,是可以做因子分析的前提条件。如果数据之间有较强的相关性,我们就可以把它们打包到一起作为一个值。这就是所谓的数据降维。
3.旋转因子与构建量表第五部分:以概率为因变量的回归
P27/28 第1讲 卡方检验
1.卡方值的计算
2.期待值是根据零假设预测的值
3.自由度就是任意度,自由度数量=(行数-1)(列数-1)
H0:观察频数与期望频数没有差别。
![公式]()
应用场景:在医学研究中,我们常需要对两组、多组率或构成比进行比较:如两种治疗方法的有效率、不同地区某种疾病的发病率、人群构成是否相同等。这类问题在统计上属于假设检验的范畴。其所涉及的数据类型为无序分类*数据。
应用举例:卡方检验应用实例解析(一)P29/30/31 对数回归
1.概率无限接近0和1
2.不能简单用线性回归分析概率
3.对数回归以发生比(P/(1-P))的自然对数为因变量P32/33 最大似然估计
1.似然是过去的概率
概率思维背后是一种世界观- 概率指未来的可能性,似然指过去的可能性
- 已经发生的事,并非必然发生
- 没有发生的事,本有可能发生
- 似然是英语的虚拟语气,哲学的可能世界
2.最大似然估计是扮演时候诸葛亮
- 最大似然估计不是推算未来,而是面对已经发生的事,推算哪几个因素对事情的发生是否产生了显著影响;如果产生了显著影响,这影响是正还是负,量有多大。换言之,最大似然估计是找出自变量的净回归系数,这些系数把已经发生的时间的似然性(在过去发生的概率)最大化。
- 与最小二乘回归一样,最大似然估计也是根据样本的情况推测总体的情况
3.衡量是否已经达到最大似然的标尺
- 最大似然估计是闲做个模型草案,然后调整模型内自变量的正负号和绝对值,让模型与数据的合适程度达到最高
- 衡量模型是否已经最适合数据的标尺是最大似然的自然对数的负二倍,后者的分布与卡方值的分布相似
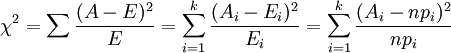
P34 定序与多元定类变项的对数回归
1.定序回归
- 平行线检验
2.多项定类变量的对数回归
第六部分 结构方程模型和双层回归- (暂时没听懂,后续再补)
P35/36 第1讲 结构方程模型是全息路径分析
P37 第2讲双层回归考察环境对个人的影响

 浙公网安备 33010602011771号
浙公网安备 33010602011771号