

Python 入门之悦目的 Pythonic(三)类的约定
# 免责声明:
本文内容主要是肥清大神的视频以及自己收集学习内容的整理笔记,目是主要是为了让博主这样的老白能更好的学习编程,如有侵权,请联系博主进行删除。
9. 类的约定
# 面向对象编程<OOP>是一种范式, 使开发人员能够借助称为类的通用蓝图创建虚拟对象
# 面向对象的模型简化了创建程序的过程, 让意大利面条代码都可以用非常结构化的方式编写
# Python 支持多种范式:
* 不必总是使用 OOP, 可以自由选择最适合用例的范式
* 随着项目的发展在编写 Python 代码时从多种范式中进行选择
# Python 中一切都被视为类的实例或对象--它们包含有关实体的数据结构和元信息
9.1. 优化类的大小
# 如果当前类做不止一件事, 那就需要创建不同的类了
9.1.1. SRP
# SRP<Single Responsibility Principle>: 单一职责原则
* 若类具有明确定义的单一职责或工作单元, 并且可以轻松地将其与其他类区分开来, 那么不必太在意代码行数或类的大小
* 在一个文件中编写一个类的代码, 这是最清晰的划分方式
* 在某些情况下, 可能需要在同一个文件中有多个紧密耦合的类
# 感觉这是最难的一个原则
# 目标: 判断用户是否为老年人并输出姓名
class user:
def __init__(self, name: str, age: int) -> None:
self.name = name
self.age = age
def is_old(self):
return self.age > 60
def output_html(self):
print(f'<h1>name: {self.name}</h1>')
def output_json(self):
print(f'{{"name": {self.name}}}')
# 问题分析:
* 输出信息信息的功能部分应该独立出来
* 用于判断是否为老年人可以是一个独立功能
* 输出信息可以独立出来为其他模块所使用
class User:
def __init__(self, name: str, age: int) -> None:
self.name = name
self.age = age
def is_old(self):
return self.age > 60
class PrintOutput:
def output_html(self, user: User) -> None:
print(f'<h1>name: {user.name}</h1>')
def output_json(self, user: User) -> None:
print(f'{{"name": {user.name}}}')
user = User('Bobby', 32)
print(user.is_old())
output = PrintOutput()
output.output_html(user)
output.output_json(user)
9.1.2. 评估每个方法和代码单元的适合性
# 估每个方法和代码单元的适合性, 确保它属于该类的责任范围
9.1.3. DRY
# DRY(Don't Repeat Yourself): 找到重复或复制的代码将其拆分为不同的部分以隔离重叠的代码
9.2. 理想的类结构
# 要写出容易维护的, 可读性高的, Pythonic代码, 就要遵循一些行业内的约定
# Python 约定了类的成员的在类结构中的顺序:
* 类变量
* __ini__
* 特殊的Python方法: 理解类的一些特殊行为
* 魔术方法
* 类方法
* 静态方法
* 在内存中只生成一次
* 私有方法
* 实例方法
# 约定的目的是为了阅读代码的人能够立马顺利的理解, 而不是在类中跳来跳去的找细节
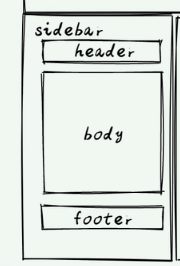
# 编写 sidebar 的代码表现理想类的结构
class SideBar:
DIV: str = 'div'
H1: str = 'h1'
MORE: str = 'more'
MORE_ITEMS_LENGTH: int = 3
SHOULD_COMPRESS_HTML: bool = True
def __init__(
self,
title: str,
menu_items: [str],
more: str = MORE,
more_items_length: int = MORE_ITEMS_LENGTH,
should_compress_html: bool = SHOULD_COMPRESS_HTML,
) -> None:
self.title = title
self.more = more
self.should_compress_html = should_compress_html
self.menu_items = menu_items
def __len__(self):
return len(self.menu_items)
def __repr__(self):
return f'SideBar: {len(self)} menu items'
@classmethod
def _header(cls, title):
return cls._build_header(cls.H1, title)
@classmethod
def _body(cls, menu_items:[str], should_compress_html: bool) -> str:
split_char = cls._get_split_char(should_compress_html)
return split_char.join(
list(cls._build_body(cls.DIV, menu_items))
)
@classmethod
def _more(cls, more):
return cls._build_more(cls.DIV, more)
@staticmethod
def _build_header(tag_name: str, title: str) -> str:
return f'<{tag_name}>{title}</{tag_name}>'
@staticmethod
def _build_body(tag_name: str, menu_items: [str]) -> str:
for menu_item in menu_items:
yield f'<{tag_name}>{menu_item}</{tag_name}'
@staticmethod
def _build_more(tag_name: str, text: str) -> str:
return f'<{tag_name}>{text}</{tag_name}>'
@staticmethod
def _get_split_char(should_compress_html: bool) -> str:
return '' if should_compress_html else '\n'
def _is_few_items(self):
return len(self) < 10
def build(self) -> str:
header = self._header(self.title)
body = self._body(self.menu_items, self.should_compress_html)
footer = self._more(self.more) if self._is_few_items() else ''
split_char = self._get_split_char(self.should_compress_html)
html = split_char.join([header, body, footer])
return html
side_bar = SideBar('DEMO SIDE BAR', ['a', 'b', 'c',])
print(side_bar.build()) # <h1>DEMO SIDE BAR</h1><div>a</div<div>b</div<div>c</div<div>more</div>
side_bar = SideBar('DEMO SIDE BAR', ['a', 'b', 'c',], should_compress_html=False)
print(side_bar.build()) # <h1>DEMO SIDE BAR</h1>
# <div>a</div>
# <div>b</div>
# <div>c</div>
# <div>more</div>
side_bar = SideBar(
'DEMO SIDE BAR',
['a', 'b', 'c',],
should_compress_html=False,
more_items_length=2
)
print(side_bar.build()) # <h1>DEMO SIDE BAR</h1>
# <div>a</div>
# <div>b</div>
# <div>c</div>
9.3. @Property 装饰器
# 在代码运行期间动态增加函数或方法功能的方式叫装饰器<Decorator>
# 面向对象的设计强调封装
* 把对象内聚的状态私有化
* 仅供类的内部进行操作
* 被封装的属性通常是通过类的 getter 和 setter 方法来实现的
# 在 Python 中, 普遍认为直接访问属性进行读写比创建单独的 getter 和 setter 方法更有意义
# Java 模式
class Square:
def __init__(self):
self._side = None
def get_side(self):
return self._side
def set_side(self, side):
assert side >= 0, '边长不能为负数'
self._side = side
def get_area(self):
return self.get_side() ** 2
square = Square()
square.set_side(6)
print(square.get_area()) # 36
# Python 模式
class Square:
def __init__(self):
self._side = None
@property
def side(self):
return self._side
# 没有此装饰器, 就不能设置 Square().side 的值
@side.setter
def side(self, side):
assert side >= 0, '边长不能为负'
self._side = side
# 执行 del Square().side 时触发
@side.deleter
def side(self):
self._side = 0
@property
def area(self) -> int:
assert self.side >=0, '需要先设置边长'
return self.side ** 2
square = Square()
square.side = 6
print(square.area) # 36
del square.side
print(square.side) # 0
9.4. @staticmethod
# 类的静态方法 staticmethod 定义了一个函数的同时, 使这个函数成为一个类变量
* 聚合业务领域概念
* 在合适的场景下节省内存资源的使用
# 静态方法是一种代码组织与风格
* 当一个模块有很多类, 并且一些辅助函数在逻辑上与给定的类相关联, 而不是与其他类相关联时使用静态方法是最合适的
* 不要用许多<自由函数>"污染"模块是有意义的
* 只是为了表明它们是<相关的>就在代码中混合类和函数定义的风格是很糟糕的
# @staticmethod的特征:
* 简单的没有隐含参数的函数
* 可以作为类或实例的方法调用
* 使用内建的@staticmethod来创建
* 内聚在类之中, 有强烈的归属感, 与类要表达的业务逻辑息息相关
* 相对于使用模块级别的函数来说减少了过多的 import
* 子类不需要重新声明就可以使用父类的静态方法
* 子类可以覆盖父类的静态方法
* 不依赖类或实例的成员变量/方法
* 聚合作用
9.4.1. 对比
# 实例方法
class Product:
def __init__(self, name: str, weight: int) -> None:
self.name = name
self.weight = weight
def is_over_weight(self, thredshold=100):
return self.weight > thredshold
# 静态方法
class ProductOne:
def __init__(self, name: str, weight: int) -> None:
self.name = name
self.weight = weight
@staticmethod
def is_over_weight(weight, thredshold=100):
return weight > thredshold
product = Product('A', 100)
print(product.is_over_weight())
product_one = ProductOne('B', 190)
print(ProductOne.is_over_weight(product_one.weight))
9.4.2. 剖析如何节约内存
9.4.2.1. 实例方法模式
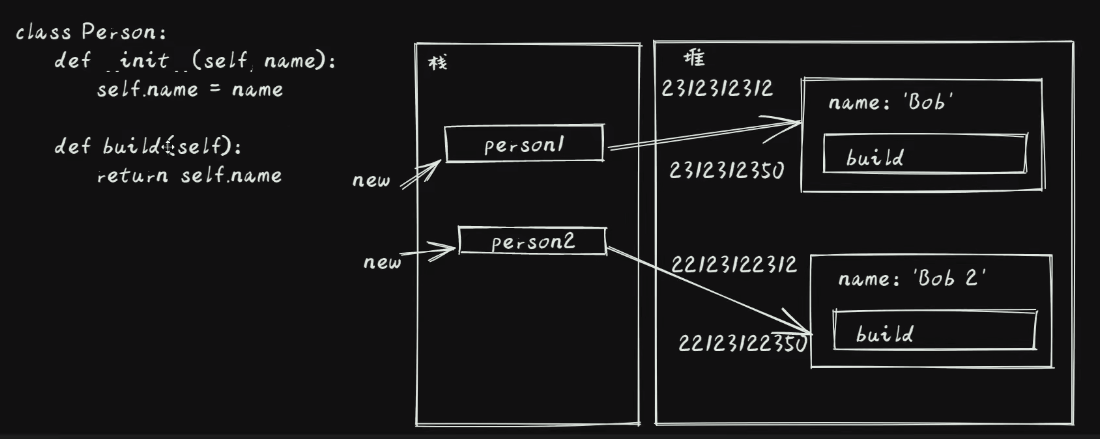
# 实例方法
class Person:
def __init__(self, name: str) -> None:
self.name = name
def build(self, name):
return name
person_class_set = set()
person_method_set = set()
for i in range(5):
person = Person(f'Bob {i}')
person_class_set.add(person)
person_method_set.add(person.build)
def print_id(input_set: set) -> None:
for item in input_set:
print(id(item))
print('--- Person() 地址 ---')
print_id(person_class_set) # 2648494216720
# 2648494216272
# 2648494216912
# 2648494216528
# 2648494215568
print('--- Person().build 地址 ---')
print_id(person_method_set) # 2648494216832
# 2648494216384
# 2648494217024
# 2648494216640
# 2648494216192
9.4.2.2. 静态方法模式
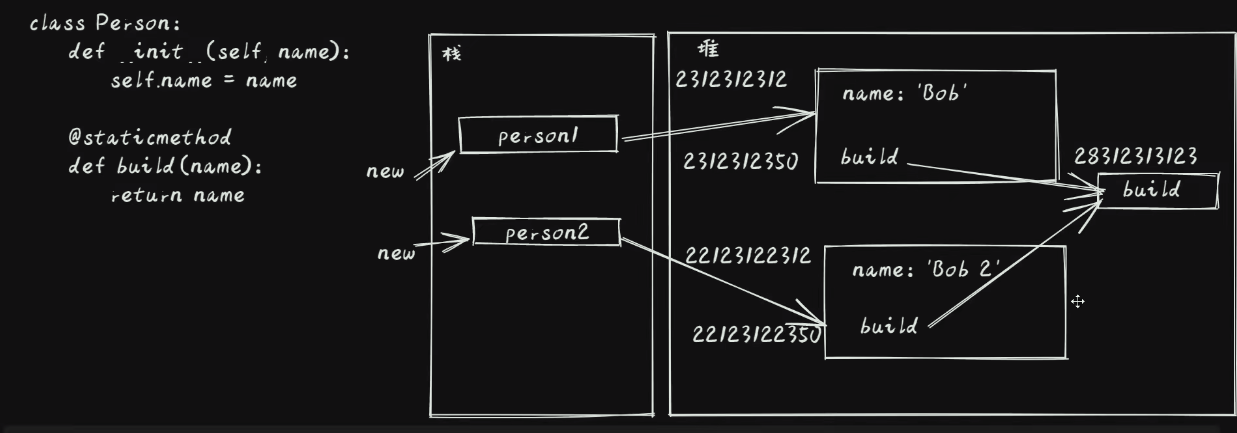
# 静态方法
class PersonOne:
def __init__(self, name: str) -> None:
self.name = name
@staticmethod
def build(name):
return name
person_one_class_set = set()
person_one_method_set = set()
for i in range(5):
person_one = PersonOne(f'Bob {i}')
person_one_class_set.add(person_one)
person_one_method_set.add(person_one.build)
def print_id(input_set: set) -> None:
for item in input_set:
print(id(item))
print('--- PersonOne() 地址 ---')
print_id(person_one_class_set) # 1399985115664
# 1399985115792
# 1399985115408
# 1399985112400
# 1399985115536
print('--- PersonOne().build 地址 ---')
print_id(person_one_method_set) # 1399985073152
9.5. @classmethod
# 类方法的调用
* 实例对象: 实例对象会被忽略, 通过间接转换为其类对象进行调用
* 类对象: 会以参数形式传给类方法
* 作为类方法的第一个参数
* 就是 cls 参数
# 类方法可以优化内存
* 在多个实例中都只有一个内存片段来存储方法实体
* 对大量的对象的场景下是有优势的
# 类方法与静态方法很多相似之处:
* 除了第一个 cls 参数不一样之外, 其他都雷同
# 可以通过子类继承父类进行 override 父类的类方法达到行为修改的目的
# 实际的应用场景:
* 类方法作为工厂方法
* 实例化不同的对象可以简化调用方的使用
* 把初始化逻封装在了工厂方法之内
* 让调用者不需要知道太多的内部的逻辑与知识
* 这是一种好的编程实践体验
# 普通实例
import json
class Product:
MULTI = 5
def __init__(self, name: str, weight: int) -> None:
self.name = name
self.weight = weight
def __repr__(self):
return f'Product {self.name} - {self.weight}'
@classmethod
def from_dict(cls, data: dict):
name = data.get('name')
weight = data.get('weight')
actual_weight = weight * cls.MULTI
return Product(name, actual_weight)
@classmethod
def from_json(cls, data: str):
data_dict = json.loads(data)
return cls.from_dict(data_dict)
product = Product.from_dict({'name': 'Toy', 'weight': 5})
print(product)
product = Product.from_json('{"name": "Another Toy", "weight": 6}')
print(product)
# 子类继承
import json
class Product:
MULTI = 5
def __init__(self, name: str, weight: int) -> None:
self.name = name
self.weight = weight
def __repr__(self):
return f'Product {self.name} - {self.weight}'
@staticmethod
def _get_data(data: dict, factor_tuple: tuple = (1, 1)):
name = data.get('name')
weight = data.get('weight')
factor = 0
for i in range(len(factor_tuple)):
factor += factor_tuple[i]
actual_weight = weight * factor
return (name, actual_weight)
@classmethod
def from_dict(cls, data: dict):
name, actual_weight = Product._get_data(data, (cls.MULTI, ))
return cls(name, actual_weight)
@classmethod
def from_json(cls, data: str):
data_dict = json.loads(data)
return cls.from_dict(data_dict)
class AdvanceProduct(Product):
UP_VALUE = 2
def __repr__(self):
return f'Advance Product: {self.name} - {self.weight}'
@classmethod
def from_dict(cls, data: dict):
name, actual_weight = AdvanceProduct._get_data(data, (cls.MULTI, cls.UP_VALUE))
return cls(name, actual_weight)
advance_product = AdvanceProduct.from_dict({'name': 'Toy', 'weight': 8})
print(advance_product)
advance_product_one = AdvanceProduct.from_json(
'{"name": "Toy", "weight": 9}'
)
print(advance_product_one)
# 类方法的地址
import json
class Product:
MULTI = 5
def __init__(self, name: str, weight: int) -> None:
self.name = name
self.weight = weight
def __repr__(self):
return f'Product {self.name} - {self.weight}'
@staticmethod
def _get_data(data: dict, factor_tuple: tuple = (1, 1)):
name = data.get('name')
weight = data.get('weight')
factor = 0
for i in range(len(factor_tuple)):
factor += factor_tuple[i]
actual_weight = weight * factor
return (name, actual_weight)
@classmethod
def from_dict(cls, data: dict):
name, actual_weight = Product._get_data(data, (cls.MULTI, ))
return cls(name, actual_weight)
@classmethod
def from_json(cls, data: str):
data_dict = json.loads(data)
return cls.from_dict(data_dict)
class AdvanceProduct(Product):
UP_VALUE = 2
def __repr__(self):
return f'Advance Product: {self.name} - {self.weight}'
@classmethod
def from_dict(cls, data: dict):
name, actual_weight = AdvanceProduct._get_data(data, (cls.MULTI, cls.UP_VALUE))
return cls(name, actual_weight)
products = [AdvanceProduct(f'Toy - {i}', i*2) for i in range(10)]
print('--- product & product.from_dict 地址---')
for product in products:
print(id(product), id(product.from_dict))
9.6. public vs private
# Python 并没有像其他的编程语言<如 Java/C#>那样有类的公有属性和私有属性的约束访问的概念
* 只能遵循 PEP-8 的规范在代码的 Style 上做出约束
* 要求在对Python进行类的设计的时候
* _前缀作为私有变量的提示
* __前缀作为保护属性的提示
* 让 Python 的开发人员在这种约定下进行合作
* 看到非公有的方法或属性就不要去访问和互动
* 保证 Python 代码的高可维护性
# 从子类继承父类的角度上分析了如何使用这些特性
class A:
def __init__(self, g=2.0):
self._a = 1.5
self.__g = g
def get_a(self):
return self._a
def get_g(self):
return self.__g
def get_hg(self):
return self.get_a() * self.get_g()
# 继承
class B(A):
def __init__(self, g=3.0):
# 可为父类中的变量赋值
# 现实中尽可能不这样做
# 子类尽可能不改变父类抽像的一些行为
# 尽可能使用<组合>而不是<继承>
super().__init__(g)
self.__g = 6
def calc(self):
return self.__g * 10
def calc_from_parent(self):
# 调用父类方法获取父类 __g 值
return self.get_g() * 10
b = B()
print(b.calc())
print(b.calc_from_parent())
# 显示实例 b 的所有属性参数
print(b.__dict__)
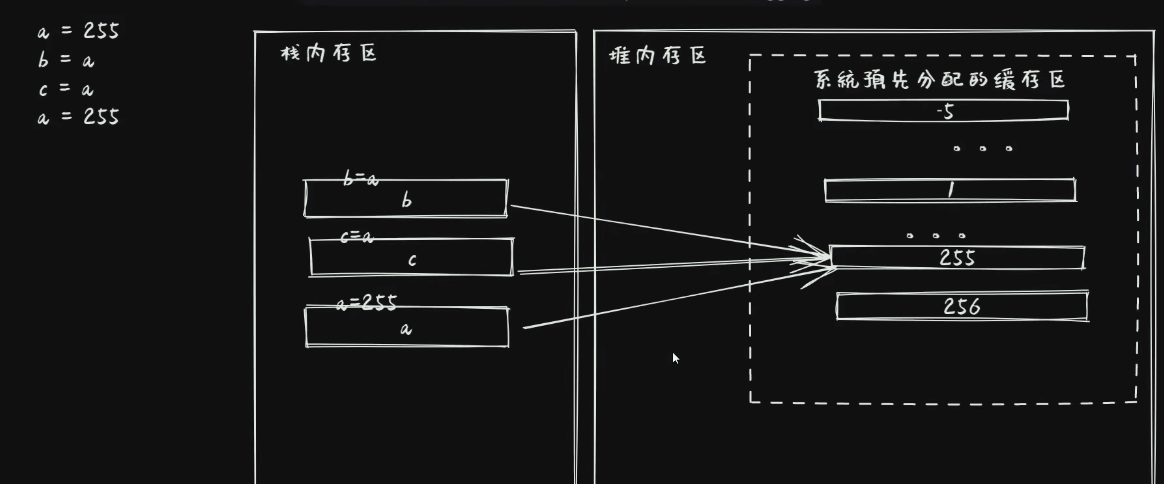
9.7. is 与 ==
# is: 对象在内存中的<地址>进行比较
# ==: 使用实现了 __eq__ 魔术方法的值的比较
# Python 对代码的优化情况:
* 整数: 在-5 ~ 256 区间的初始值, Python 会默认划分一个缓存区来存贮
* 赋值区间内的值不会重新在堆内存中再划分新区来存贮, 而是使用缓存区,
* 会大大提高效率
* 字符串: 在 < 4097 个字符的情况也一样
# Python 的解析器会有很多内部的优化机制
* 在编译代码为 Bytecode 的期间会预先扫描源代码把可以优化的复制片段进行优化
9.8. super() 的使用
# Python 可能不是纯粹的面向对象语言, 却也拥有使用面向对象设计模式构建软件和应用程序的基础
* 使用 super() 方法支持继承
* 所有语言一样, 此方法允许从派生类本身访问超类的实体
* super() 方法返回对父类实例的引用, 可以用来调用基类的方法
# super() 的例子里面引申出了面向对象分析与设计的开闭原则
* 设计易于维护的并容易扩展的类离不开这些原则的渗透和 super() 工具提供的便利
class A:
def __init__(self, name):
self.name = name
def show(self):
print(f'A - {self.name}')
# 继承
class B(A):
def __init__(self, name):
# 可为父类中的变量赋值
# 现实中尽可能不这样做
# 子类尽可能不改变父类抽像的一些行为
# 尽可能使用<组合>而不是<继承>
super().__init__(name)
def show(self):
super().show()
print(f'B - * * {self.name}')
b = B('Test')
print(b.show())
import logging
log = logging.getLogger(__name__)
log.setLevel(logging.DEBUG)
ch = logging.StreamHandler()
ch.setLevel(logging.DEBUG)
log.addHandler(ch)
class Person:
def __getattribute__(self, name):
log.debug(f'getting attribute [{name}]')
return super().__getattribute__(name)
def __setattr__(self, name, value):
log.debug(f'setting attribute [{name}] to {value}')
super().__setattr__(name, value)
person = Person()
# 调用 person.__setattr__()
person.name = 'Steven'
# 调用 person.__getattribute__()
print(person.name)
# 体现了开闭原则的思想:
* 没有对基类中的 __getattribute__ 和 __setattr__ 重新编写或修改内容
* 只是对基于基类的这两个方法的实现做了一个扩展
* 应用时可基于继承实现对一些功能的增强
class ProgrammingLanguage:
def __init__(self, name):
print(name, 'is a programming language.')
class DesktopProgrammingLanguage(ProgrammingLanguage):
def __init__(self, name):
print(name, 'is a desktop programming language.')
super().__init__(name)
class WebProgrammingLanguage(ProgrammingLanguage):
def __init__(self, name):
print(name, 'is a web programming language.')
super().__init__(name)
class MixedProgrammingLanguage(DesktopProgrammingLanguage, WebProgrammingLanguage):
def __init__(self, name):
print(name, 'is a mixed programming language.')
super().__init__(name)
python = MixedProgrammingLanguage('Python')
9.9. MRO
# 方法解析顺序<MRO>表示编程语言解析方法或属性的方式
# Python 支持从其他类继承
* 被继承的类称为父类或超类
* 继承的类称为子类或子类
# 在 python 中, 方法解析顺序定义了执行方法时搜索基类的顺序
* 首先在类中搜索方法或属性
* 第二按照我们在继承时指定的顺序进行搜索
* 此顺序也称为类的线性化, 而一组规则称为 MRO<方法解析顺序>
* 从另一个类继承时, 解释器需要一种方法来解析通过实例调用的方法
# Python 支持多重继承
* 在 Python 中, MRO 是从下到上, 从左到右
* 首先, 在对象的类中搜索方法
* 如果没有找到, 则在直接超类中搜索
* 在多个超类的情况下, 按照开发者声明的顺序从左到右进行搜索。
# Python3是通过C3线性化算法来实现MRO的
9.10. 类与实例的陷井
# Python 对象区分实例变量和类变量
# 类的范围内定义的方法和属性独立于类的任何实例
* 它们将信息保存在类级别
* 每个实例化对象都可以访问相同的类变量
* 利用类变量可以在类的所有实例之间共享信息
# 实例变量特定于创建的对象
* 这些变量的信息存储在特定于该对象的内存中
* 独立于其他实例变量
# 相同的名称实例变量比类变量具有更高的优先级
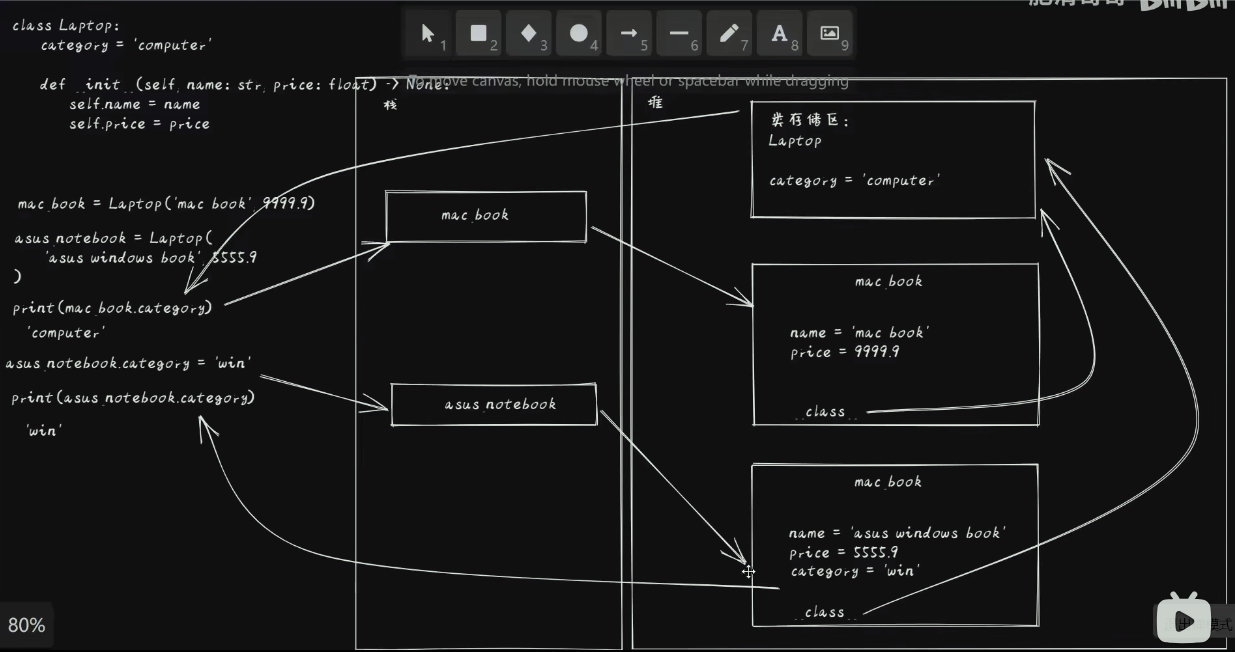
9.11. 带有类属性 self 或 classmethod
# 类级属性不需要类的实例即可使用
# 使用类属性在类继承的情况下, 需要注意传递类的知识以及类的上下文, 才能够让子类能够在继承复用父类功能的前提下, 有这更好的扩展, 而不会产生歧义。
查一下

 浙公网安备 33010602011771号
浙公网安备 33010602011771号