2020-03-05 Linux安装zookeeper
一、下载
1.zookeeper官网下载安装包http://mirrors.hust.edu.cn/apache/zookeeper/
选一个版本下载
2、下载后将包放入 Linux系统的 /usr/local 路径下
二、设置启动
1、解压安装包
tar -zxvf ./zookeeper-3.4.10.tar.gz
2、进入zookeeper目录
cd zookeeper-3.4.10
3、创建data文件夹
mkdir data
4、进入 conf文件
cd conf
5、将zoo_sample.cfg复制一份并重命名为zoo.cfg
cp zoo_sample.cfg zoo.cfg
6、修改zoo.cfg中dataDir路径为刚刚创建的data
vim zoo.cfg

7、保存编辑后退出,进入bin目录
cd ../bin
8、启动
./zkServer.sh start
9、查看状态
./zkServer.sh status
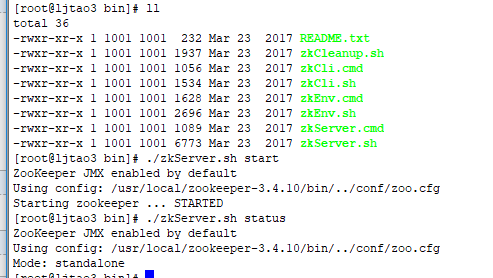
完成。
三、为什么需要 Zookeeper
在分布式系统中,需要协调者,来回答系统下各个节点的提问。
比如我们搭建了一个数据库集群,里面有一个Master,多个Slave,Master负责写,Slave只读,我们需要一个系统,来告诉客户端,哪个是Master。
有人说,很简单,我们把这个信息写到一个Java服务器的内存就好了,用一个map,key:master,value:master机器对应的ip
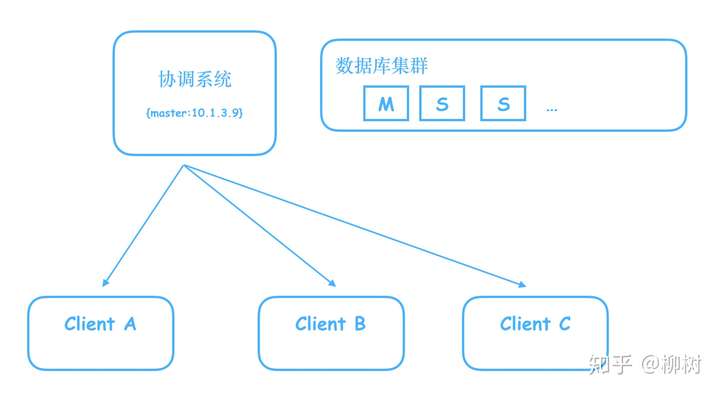
但是别忘了,这是个单机,一旦这个机器挂了,就完蛋了,客户端将无法知道到底哪个是Master。
于是开始进行拓展,拓展成三台服务器的集群。
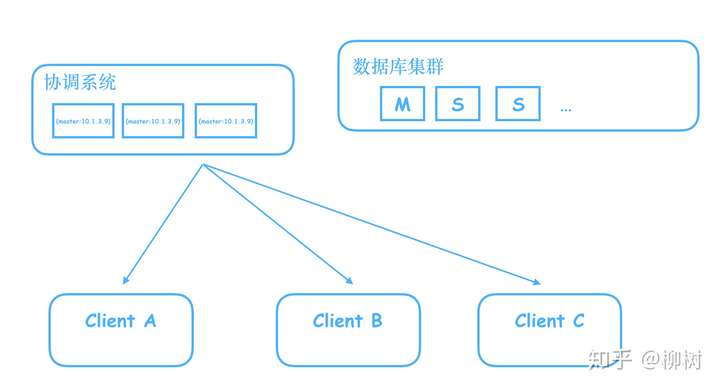
这下问题来了,如果我在其中一台机器修改了Master的ip,数据还没同步到其他两台,这时候客户端过来查询,如果查询走的是另外两台还没有同步到的机器,就会拿到旧的数据,往已经不是master的机器写数据。
所以我们需要这个存储master信息的服务器集群,做到当信息还没同步完成时,不对外提供服务,阻塞住查询请求,等待信息同步完成,再给查询请求返回信息。
这样一来,请求就会变慢,变慢的时间取决于什么时候这个集群认为数据同步完成了。
假设这个数据同步时间无限短,比如是1微妙,可以忽略不计,那么其实这个分布式系统,就和我们之前单机的系统一样,既可以保证数据的一致,又让外界感知不到请求阻塞,同时,又不会有SPOF(Single Point of Failure)的风险,即不会因为一台机器的宕机,导致整个系统不可用。
这样的系统,就叫分布式协调系统。谁能把这个数据同步的时间压缩的更短,谁的请求响应就更快,谁就更出色,Zookeeper就是其中的佼佼者。
它用起来像单机一样,能够提供数据强一致性,但是其实背后是多台机器构成的集群,不会有SPOF。
如果把各个节点比作各种小动物,那协调者,就是动物园管理员,这也就是Zookeeper名称的由来了,从名字就可以看出来它的雄心勃勃。
讲完了上面这些,现在再来看官网这句话,就很能理解了:
ZooKeeper: A Distributed Coordination Service for Distributed Applications当然还有这句:

而以往的很多ZK教程,上来就是“Zookeeper是开源的分布式应用协调系统”blabla,很多像我这样的小年轻看到就会很费解,到底什么是分布式协调,为什么分布式就需要协调 …
上面只是回答了我自己提出的问题,为什么需要Zookeeper,或者说,为什么需要分布式协调系统,如果想进一步学习 ZK,你还需要了解下 Zookeeper 的内部实现原理。
比如 ZK 的宏观结构:
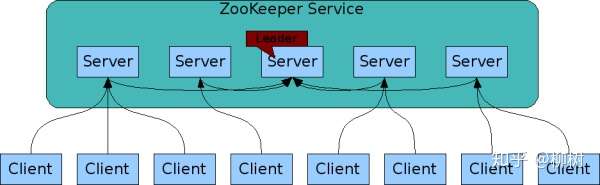
到 ZK 的微观:
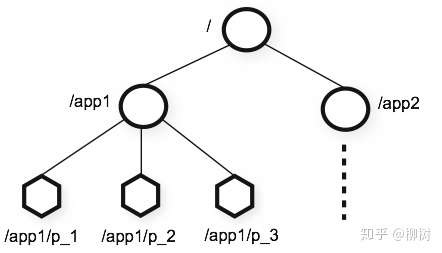
再到 ZK 是如何实现高性能的强一致的,即ZAB协议的原理,很多教程上来就开始介绍ZAB协议,很容易让人一头雾水,不知道为什么需要这样一个分布式一致性协议,有了上述介绍的背景,就好懂许多。
四、Zookeeper能做什么
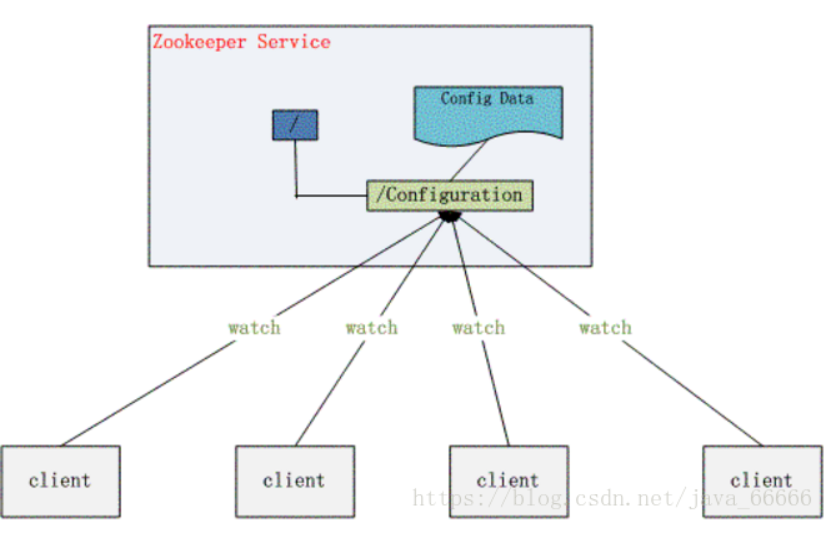
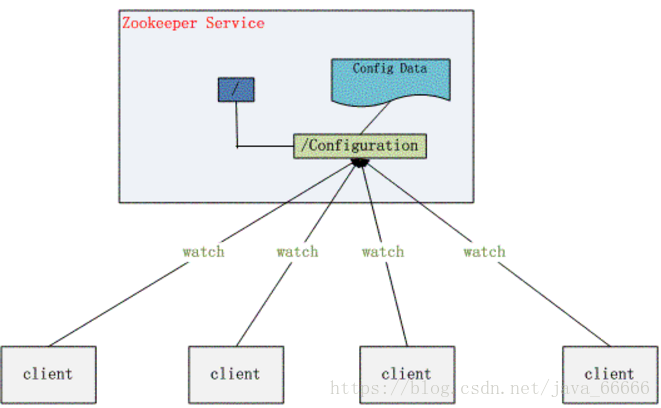
zookeeper功能非常强大,可以实现诸如分布式应用配置管理、统一命名服务、状态同步服务、集群管理等功能,我们这里拿比较简单的分布式应用配置管理为例来说明。
假设我们的程序是分布式部署在多台机器上,如果我们要改变程序的配置文件,需要逐台机器去修改,非常麻烦,现在把这些配置全部放到zookeeper上去,保存在 zookeeper 的某个目录节点中,然后所有相关应用程序对这个目录节点进行监听,一旦配置信息发生变化,每个应用程序就会收到 zookeeper 的通知,然后从 zookeeper 获取新的配置信息应用到系统中。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号