

最简单方式理解为什么MongoDB索引选择B-树,而 Mysql 选择B+树
这个问题是我在看视频的时候老师提到的,虽然之前知道他们各自的索引结构但是还没有研究过原因。在网上一搜答案特别多。但是都特别的啰嗦。于是总结了这篇文章。
一、B-树和B+树的区别
很明显,我们要想弄清楚原因就要知道B-树和B+树的区别。为了不长篇大论。我们直接给出他们的形式总结他们的特点。
1、B-树
B-树是一种自平衡的搜索树,形式很简单:

这就是一颗B-树。针对我们这个问题的最核心的特点如下:
(1)多路,非二叉树
(2)每个节点既保存索引,又保存数据
(3)搜索时相当于二分查找
在这里我们假定都已经了解了B树相关的结构。
2、B+树
B+树是B-树的变种

最核心的特点如下:
(1)多路非二叉
(2)只有叶子节点保存数据
(3)搜索时相当于二分查找
(4)增加了相邻接点的指向指针。
从上面我们可以看出最核心的区别主要有俩,一个是数据的保存位置,一个是相邻节点的指向。就是这俩造成了MongoDB和Mysql的差别。为什么呢?
3、B-树和B+树的区别
(1)B+树查询时间复杂度固定是logn,B-树查询复杂度最好是 O(1)。
(2)B+树相邻接点的指针可以大大增加区间访问性,可使用在范围查询等,而B-树每个节点 key 和 data 在一起,则无法区间查找。
(3)B+树更适合外部存储,也就是磁盘存储。由于内节点无 data 域,每个节点能索引的范围更大更精确
(4)注意这个区别相当重要,是基于(1)(2)(3)的,B-树每个节点即保存数据又保存索引,所以磁盘IO的次数很少,B+树只有叶子节点保存,磁盘IO多,但是区间访问比较好。
在B+树上增加了顺序访问指针,也就是每个叶子节点增加一个指向相邻叶子节点的指针,这样一棵树成了数据库系统实现索引的首选数据结构。
原因有很多,最主要的是这棵树矮胖,呵呵。一般来说,索引很大,往往以索引文件的形式存储的磁盘上,索引查找时产生磁盘I/O消耗,相对于内存存取,I/O存取的消耗要高几个数量级,所以评价一个数据结构作为索引的优劣最重要的指标就是在查找过程中磁盘I/O操作次数的时间复杂度。树高度越小,I/O次数越少。
那为什么是B+树而不是B树呢,因为它内节点不存储data,这样一个节点就可以存储更多的key。
二、原因解释
想要解释原因,我们还必须要了解一下MongoDB和Mysql的基本概念。
1、MongoDB
MongoDB 是文档型的数据库,是一种 nosql,它使用类 Json 格式保存数据。比如之前我们的表可能有用户表、订单表、购物篮表等等,还要建立他们之间的外键关联关系。但是类Json就不一样了。
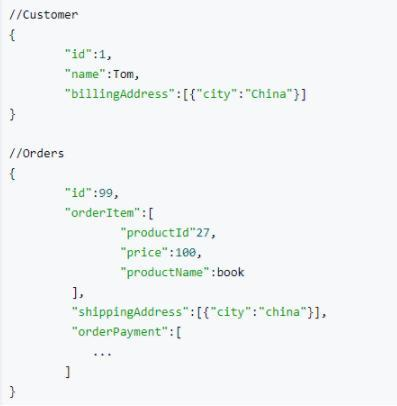
我们可以看到这种形式更简单,通俗易懂。那为什么 MongoDB 使用B-树呢?
MongoDB使用B-树,所有节点都有Data域,只要找到指定索引就可以进行访问,无疑单次查询平均快于Mysql。
2、Mysql
Mysql作为一个关系型数据库,数据的关联性是非常强的,区间访问是常见的一种情况,B+树由于数据全部存储在叶子节点,并且通过指针串在一起,这样就很容易的进行区间遍历甚至全部遍历。
这俩区别的核心如果你能看懂B-树和B+树的区别就很容易理解。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号