【GUI软件】采集抖音博主的主页视频(可监控对标账号最新作品)
一、背景介绍
1.1 爬取目标
您好!我是@马哥python说,一名10年程序猿。
我用python开发了一个抖音爬虫采集软件,可自动按博主抓取其已发布视频数据。
为什么有了源码还开发界面软件呢?方便不懂编程代码的小白用户使用,无需安装python,无需改代码,双击打开即用!
软件界面截图: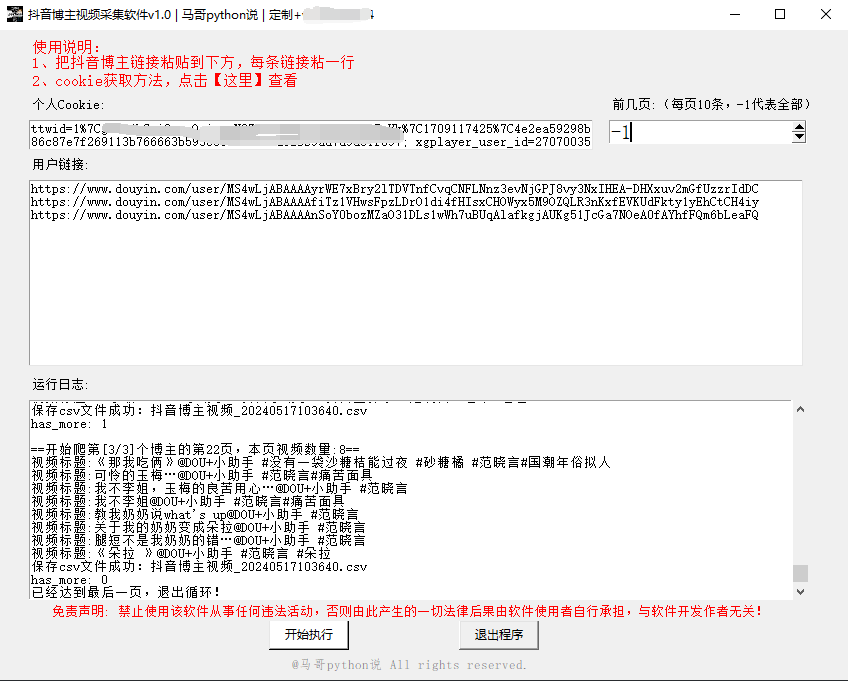
爬取结果截图:
结果截图1: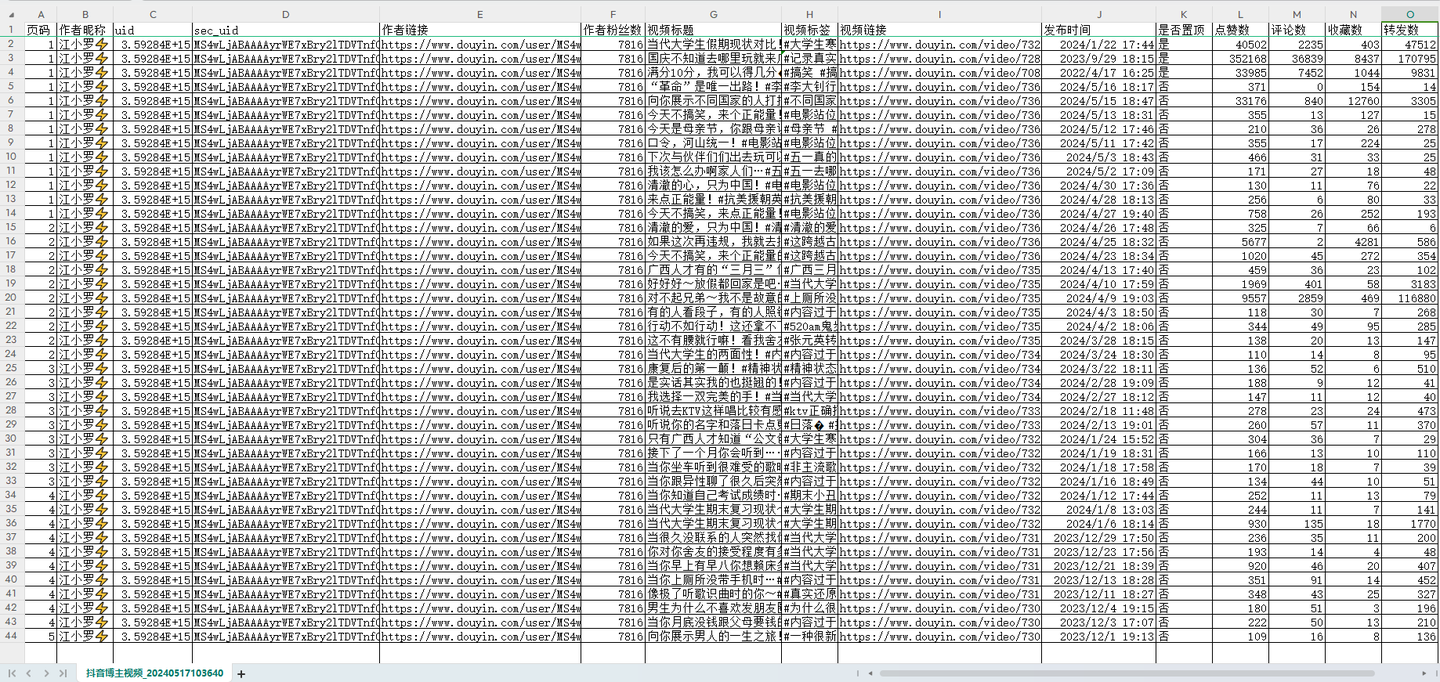
结果截图2: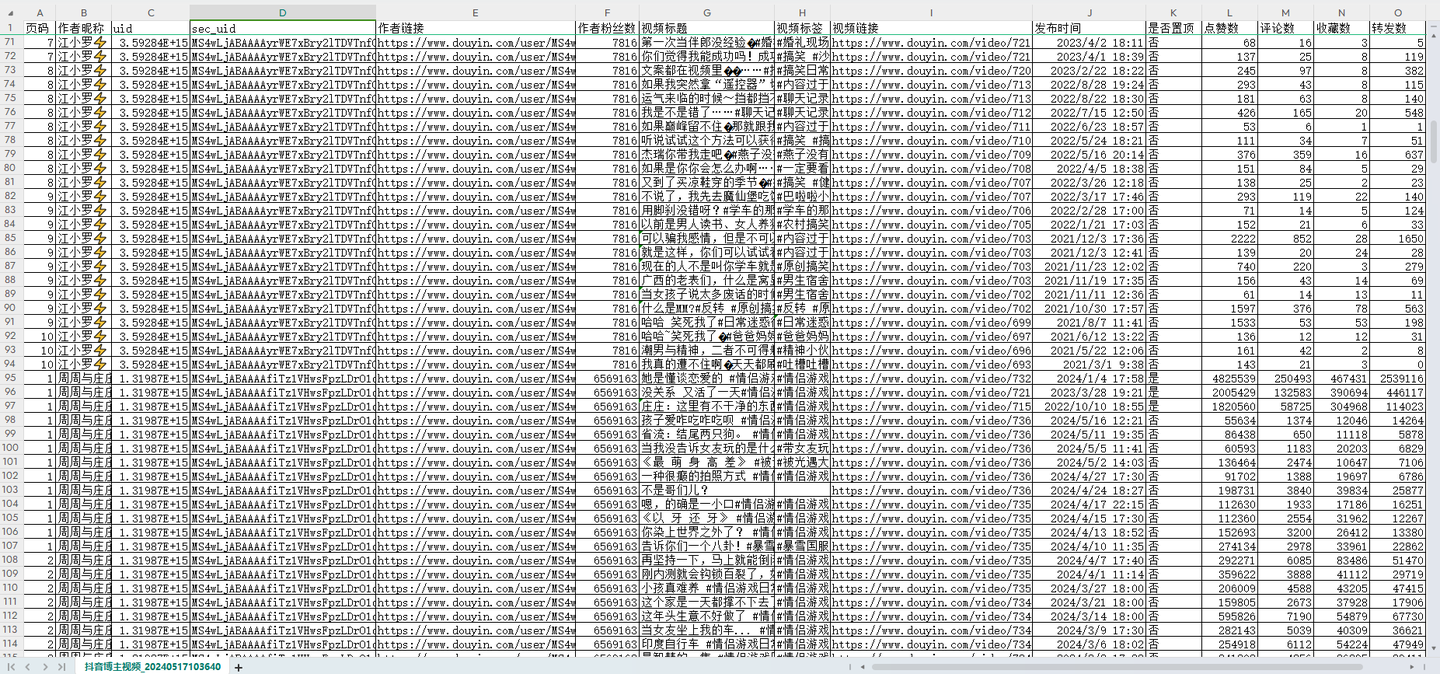
结果截图3: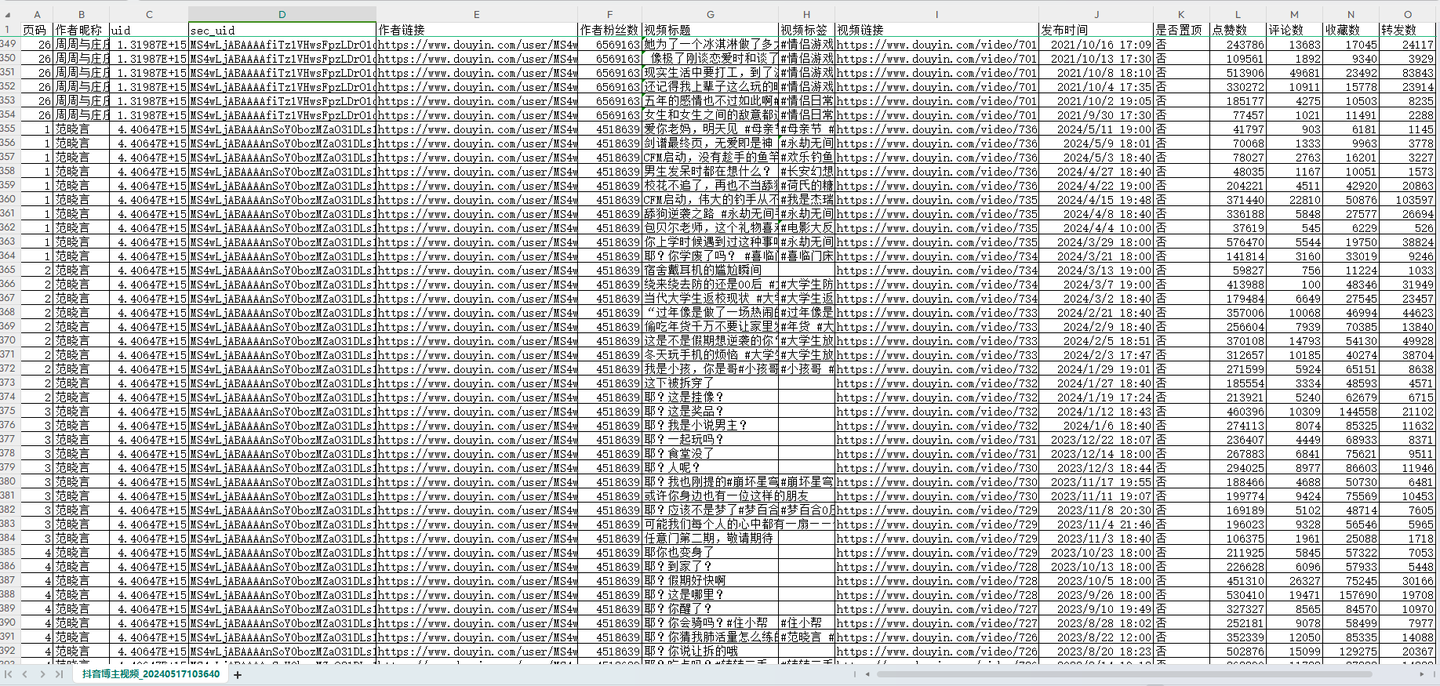
以上。
1.2 演示视频
软件使用演示:(不懂编程没关系,了解软件的作用和使用方法就行)
【软件演示】抖音主页作品采集,可监控目标账号的最新作品
1.3 软件说明
几点重要说明:
以上。
二、代码讲解
2.1 爬虫采集模块
首先,定义接口地址作为请求地址:
# 请求地址
url = 'https://www.douyin.com/aweme/v1/web/aweme/post/'
定义一个请求头,用于伪造浏览器:
# 请求头
h1 = {
"Accept": "application/json, text/plain, */*",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "zh-CN,zh;q=0.9",
"Cookie": self.cookie_val,
"Priority": "u=1, i",
"Referer": "https://www.douyin.com/user/{}?vid=7325137998331399435".format(user_id),
"Sec-Ch-Ua": '"Not_A Brand";v="8", "Chromium";v="120", "Google Chrome";v="120"',
"Sec-Ch-Ua-Mobile": "?0",
"Sec-Ch-Ua-Platform": "macOS",
"Sec-Fetch-Dest": "empty",
"Sec-Fetch-Mode": "cors",
"Sec-Fetch-Site": "same-origin",
"User-Agent": ua,
}
说明一下,cookie是个关键参数。
其中,cookie的获取方法,如下: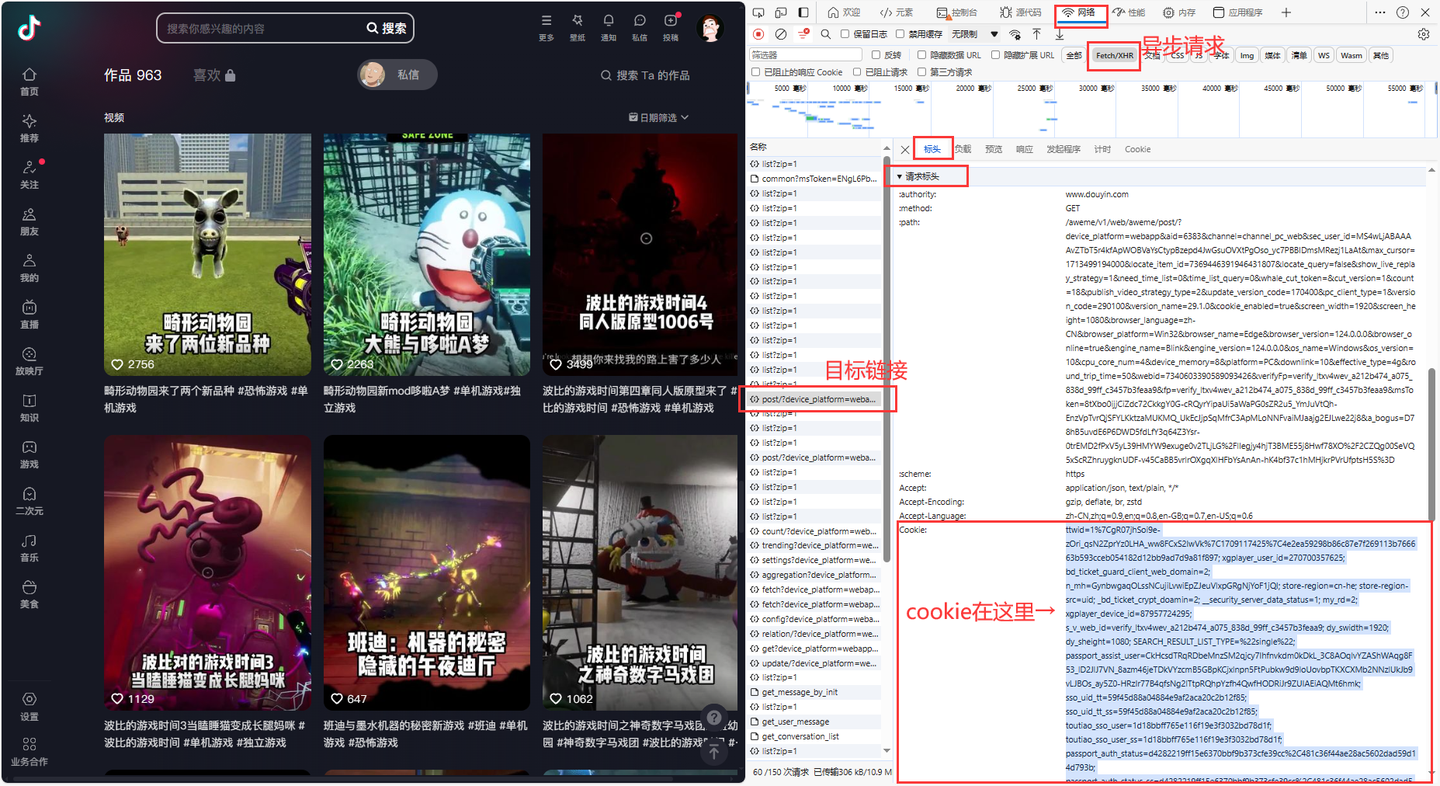
这个值非常重要,软件界面需要填写!!
加上请求参数,告诉程序你的爬取条件是什么:
# 请求参数
params = {
"device_platform": "webapp",
"aid": "6383",
"channel": "channel_pc_web",
"sec_user_id": user_id,
"max_cursor": max_cursor,
"locate_item_id": "7325137998331399435",
"locate_query": "false",
"show_live_replay_strategy": "1",
"need_time_list": "0",
"time_list_query": "0",
"whale_cut_token": "",
"cut_version": "1",
"count": 10,
"publish_video_strategy_type": "2",
"pc_client_type": "1",
"version_code": "170400",
"version_name": "17.4.0",
"cookie_enabled": "true",
"screen_width": "1440",
"screen_height": "900", "browser_language": "zh-CN",
"browser_platform": "MacIntel",
"browser_name": "Chrome",
"browser_version": "120.0.0.0",
"browser_online": "true",
"engine_name": "Blink",
"engine_version": "120.0.0.0",
"os_name": "Mac OS",
"os_version": "10.15.7",
"cpu_core_num": "4",
"device_memory": "8",
"platform": "PC",
"downlink": "1.35",
"effective_type": "3g",
"round_trip_time": "550",
"webid": "7312681406147921448",
"msToken": "Bjgl7yWKL7c57PFiwM6V4UWZ54Lm_eh4gjFdyOkX4xV93SpMHyyPMdO1u9j_OvsvgjtNNQFhaK9rWs2G8o7had3VtbDQuuaA41G3yFif70ssE_5ZnqQ6rg",
}
下面就是发送请求和接收数据:
# 发送请求
r = requests.get(url, headers=h1, params=params)
print(r.status_code)
# 以json格式接收返回数据
json_data = r.json()
定义一些空列表,用于存放解析后字段数据:
# 定义空列表
title_list = [] # 视频标题
tag_list = [] # 视频标签
link_list = [] # 视频链接
author_name_list = [] # 作者昵称
uid_list = [] # uid
sec_uid_list = [] # sec_uid
author_link_list = [] # 作者链接
follower_count_list = [] # 作者粉丝数
create_time_list = [] # 发布时间
is_top_list = [] # 是否置顶
like_count_list = [] # 点赞数
comment_count_list = [] # 评论数
collect_count_list = [] # 收藏数
share_count_list = [] # 转发数
循环解析字段数据,以"视频标题"为例:
for v in video_list:
# 视频标题
title = v['desc']
self.tk_show('视频标题:' + title)
title_list.append(title)
其他字段同理,不再赘述。
最后,是把数据保存到csv文件:
# 保存数据到DF
df = pd.DataFrame(
{
'页码': page,
'作者昵称': author_name_list,
'uid': uid_list,
'sec_uid': sec_uid_list,
'作者链接': author_link_list,
'作者粉丝数': follower_count_list,
'视频标题': title_list,
'视频标签': tag_list,
'视频链接': link_list,
'发布时间': create_time_list,
'是否置顶': is_top_list,
'点赞数': like_count_list,
'评论数': comment_count_list,
'收藏数': collect_count_list,
'转发数': share_count_list,
}
)
if os.path.exists(self.result_file): # 如果文件存在,不再设置表头
header = False
else: # 否则,设置csv文件表头
header = True
df.to_csv(self.result_file, mode='a+', index=False, header=header, encoding='utf_8_sig')
self.tk_show('保存csv文件成功:' + self.result_file)
完整代码中,还含有:判断循环结束条件、js逆向参数、时间戳转换、判断置顶视频等关键实现逻辑。
2.2 软件界面模块
主窗口部分:
# 创建主窗口
root = tk.Tk()
root.title('抖音博主视频采集软件v1.1 | 马哥python说 |')
# 设置窗口大小
root.minsize(width=850, height=650)
输入控件部分:
# 用户链接
tk.Label(root, justify='left', text='用户链接:').place(x=30, y=125)
entry_nt = tk.Text(root, bg='#ffffff', width=110, height=14, )
entry_nt.place(x=30, y=150, anchor='nw') # 摆放位置
底部版权部分:
# 版权信息
copyright = tk.Label(root, text='@马哥python说 All rights reserved.', font=('仿宋', 10), fg='grey')
copyright.place(x=290, y=625)
以上。
2.3 日志模块
好的日志功能,方便软件运行出问题后快速定位原因,修复bug。
核心代码:
def get_logger(self):
self.logger = logging.getLogger(__name__)
# 日志格式
formatter = '[%(asctime)s-%(filename)s][%(funcName)s-%(lineno)d]--%(message)s'
# 日志级别
self.logger.setLevel(logging.DEBUG)
# 控制台日志
sh = logging.StreamHandler()
log_formatter = logging.Formatter(formatter, datefmt='%Y-%m-%d %H:%M:%S')
# info日志文件名
info_file_name = time.strftime("%Y-%m-%d") + '.log'
# 将其保存到特定目录,ap方法就是寻找项目根目录,该方法博主前期已经写好。
case_dir = r'./logs/'
info_handler = TimedRotatingFileHandler(filename=case_dir + info_file_name,
when='MIDNIGHT',
interval=1,
backupCount=7,
encoding='utf-8')
日志文件截图: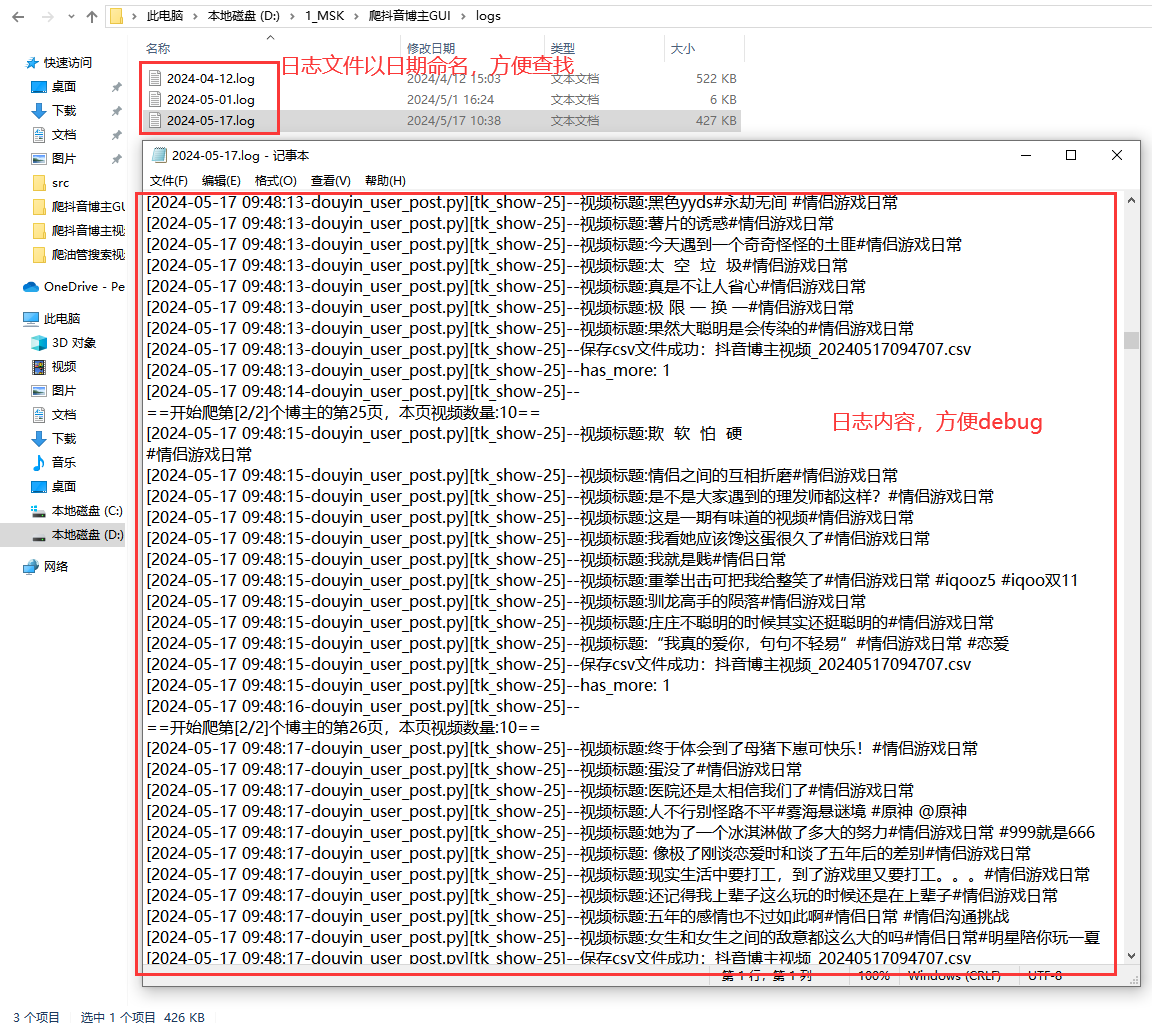
以上。
三、获取采集软件
完整exe采集软件,微信公众号"老男孩的平凡之路"后台回复"爬抖音博主软件"即可获取。点击直达
我是@马哥python说,一名10年程序猿,持续分享Python干货中!
