
Coursera Deep Learning 2 Improving Deep Neural Networks: Hyperparameter tuning, Regularization and Optimization - week2, Optimization algorithms
Gradient descent
Batch Gradient Decent, Mini-batch gradient descent, Stochastic gradient descent



还有很多比gradient decent 更优化的算法,在了解这些算法前,需要先理解 Exponentially weighted averages 这个概念
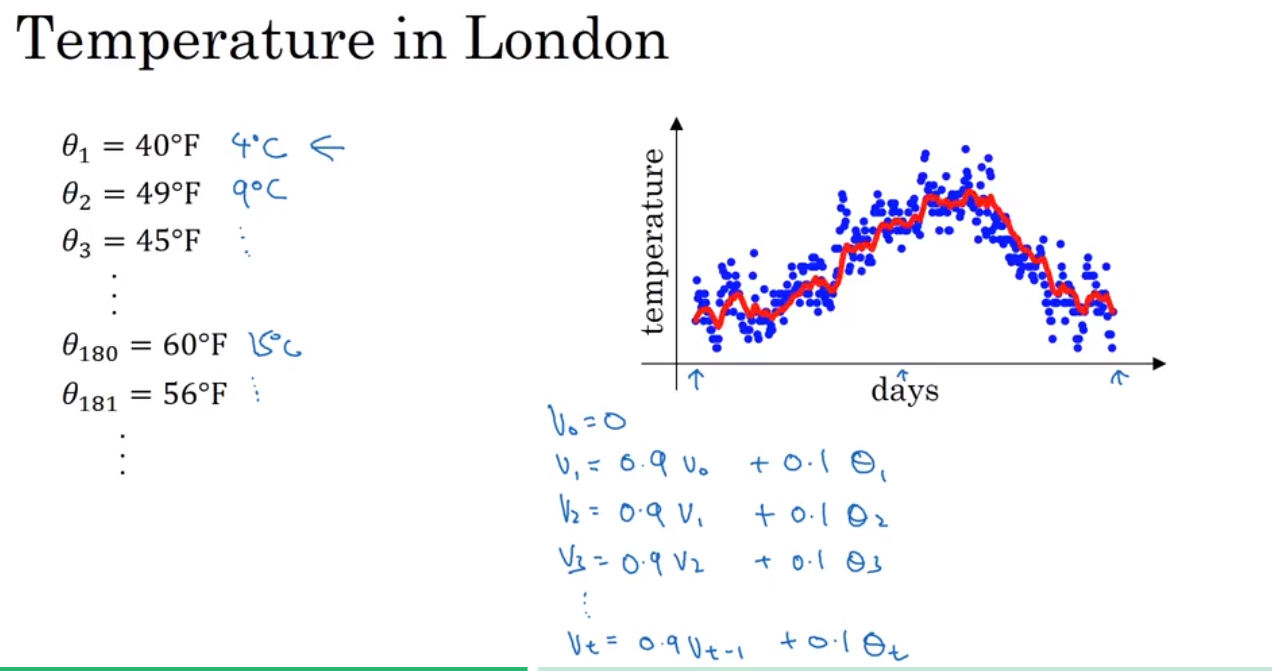

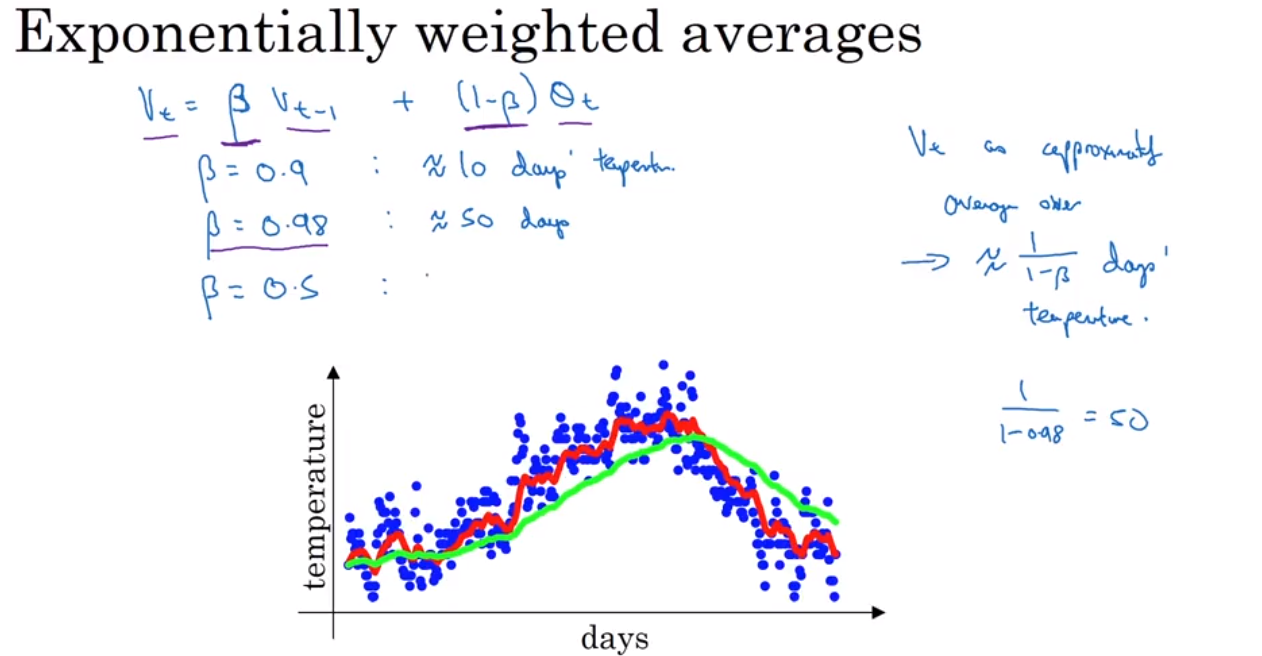
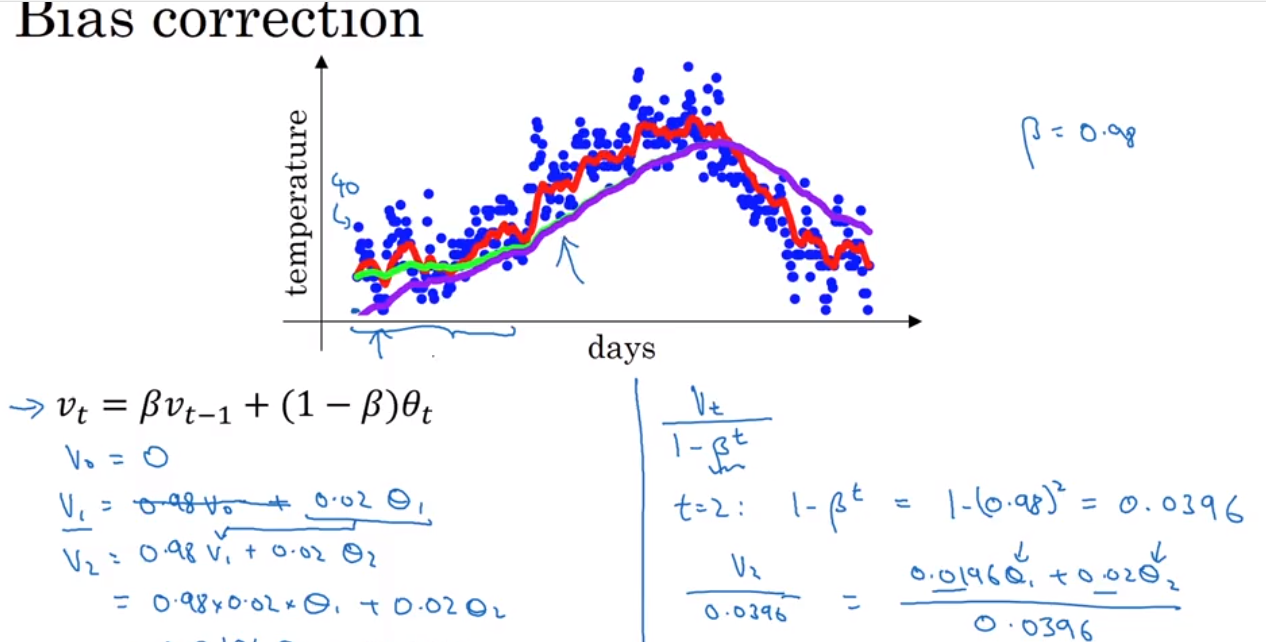
Exponentially weighted average 是一种计算平均值的方法,非常省storage 和 memory, 但是不是很精确。 然后引出一个bias correction 的概念,就是为了能使得 Exponentially weighted average 更加精确.
momentum (or called Gradient descent with momentum)
传统的Gradient descent 算法有如下图所示的问题 - 每次迭代都会来回跳动,不直接指向optimum, 在没有做feature scaling 的时候尤其明显。所以引出一个修正的算法 - Gradient descent with momentum.


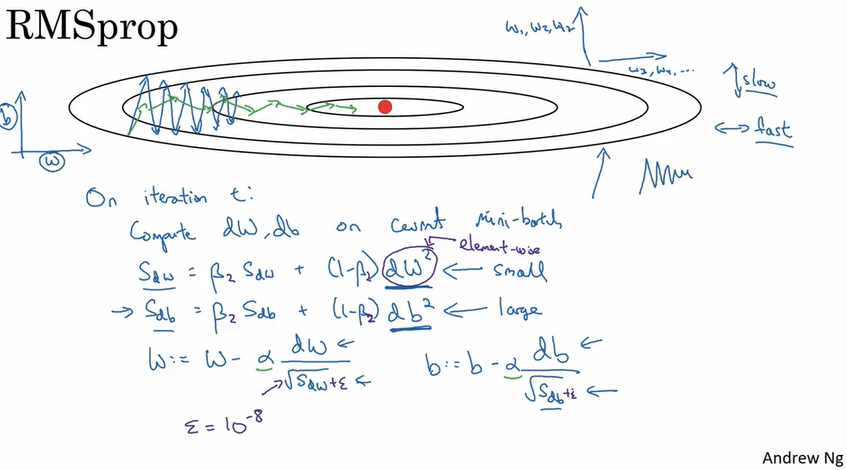
RMSprop
目的和上面讲到的Momentum是一样的,就是使得每次迭代都尽量指向optimum而不是来回跳动. 算法实现如下. RMSprop带来的好处是迭代更快,和可以选用更大的learning rate.
Adam optimation algorithm:
结合了Momentum 和 RMSprop 两种算法. Adam stands for Adaptive mement estimation.


Learning rate decay
why? to reduce the oscillation near the central point.
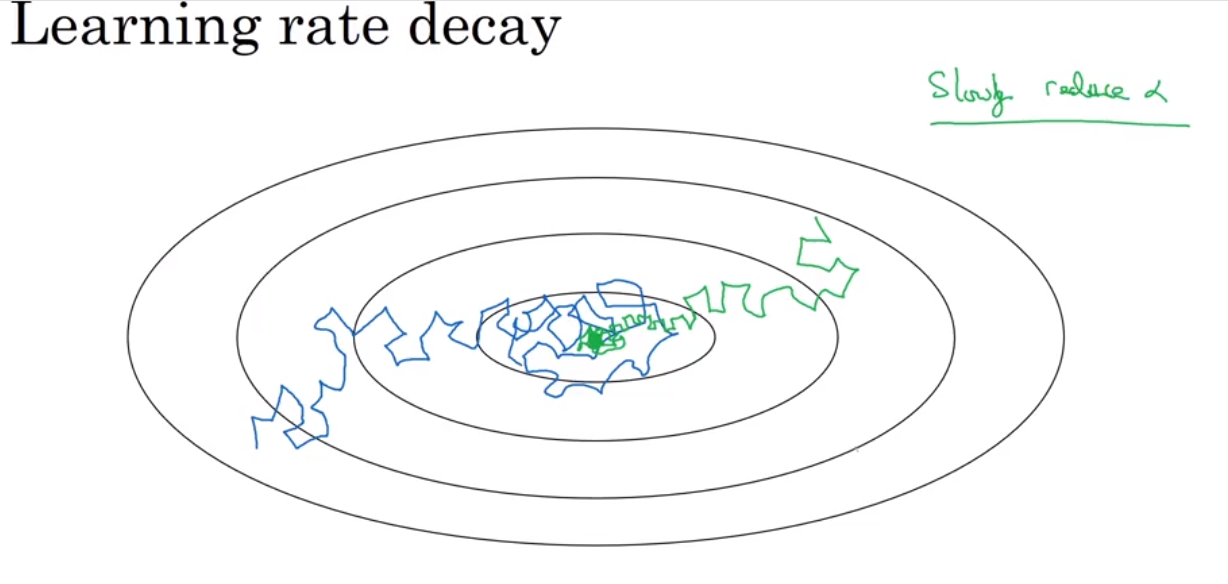
有哪些实现方式呢?


Local optima and saddle point
在大型神经网络里,saddle point 可能比local optima更常见.
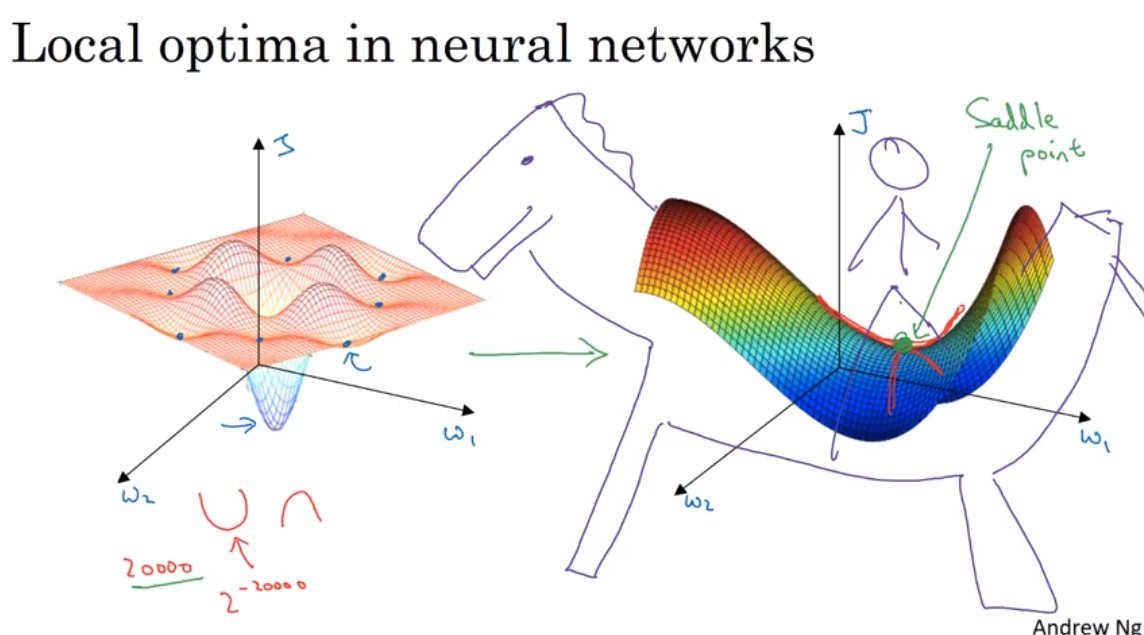
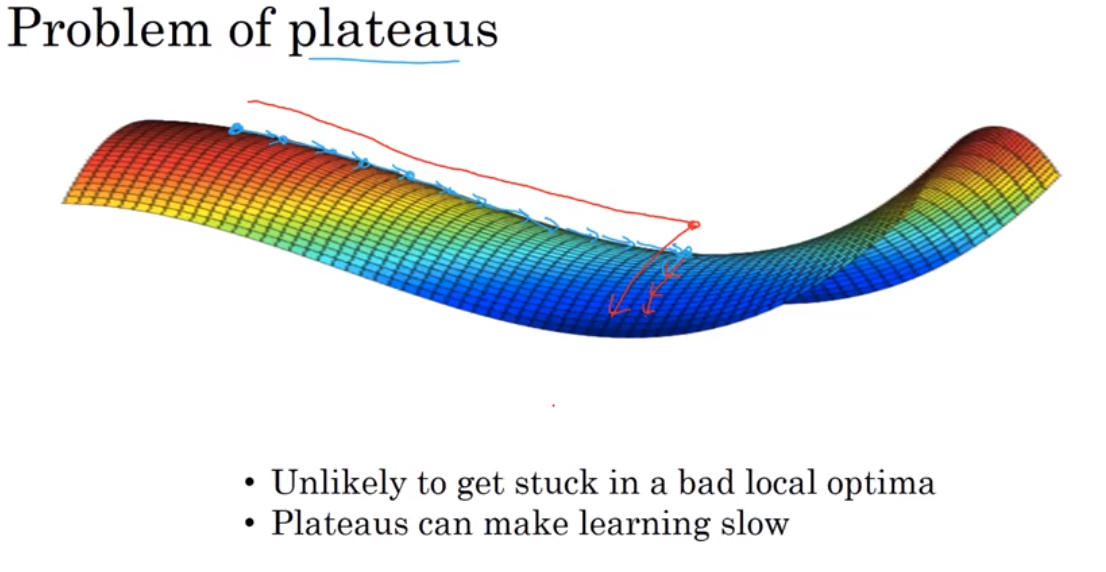
Ref:
Coursera, Deep leaning, Andrew Ng

 浙公网安备 33010602011771号
浙公网安备 33010602011771号