
Coursera, Deep Learning 2, Improving Deep Neural Networks: Hyperparameter tuning, Regularization and Optimization - week1, Course
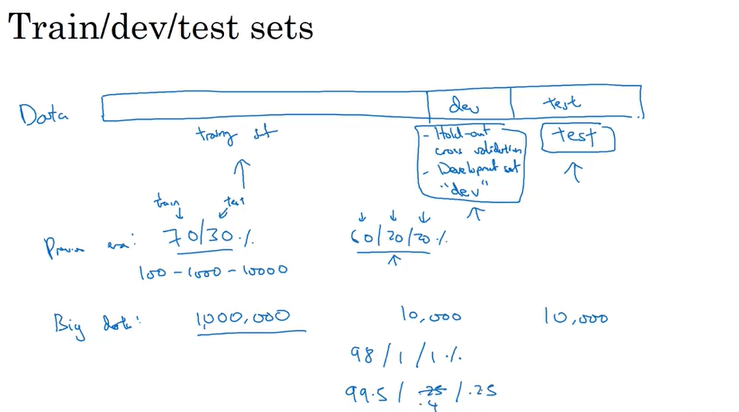
Train/Dev/Test set
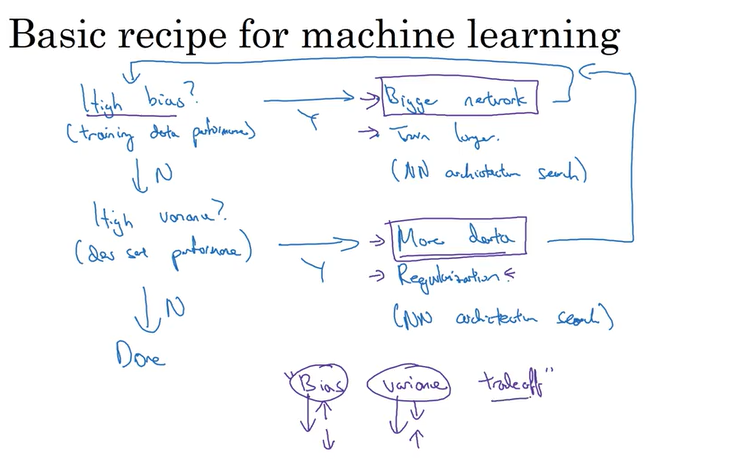
Bias/Variance

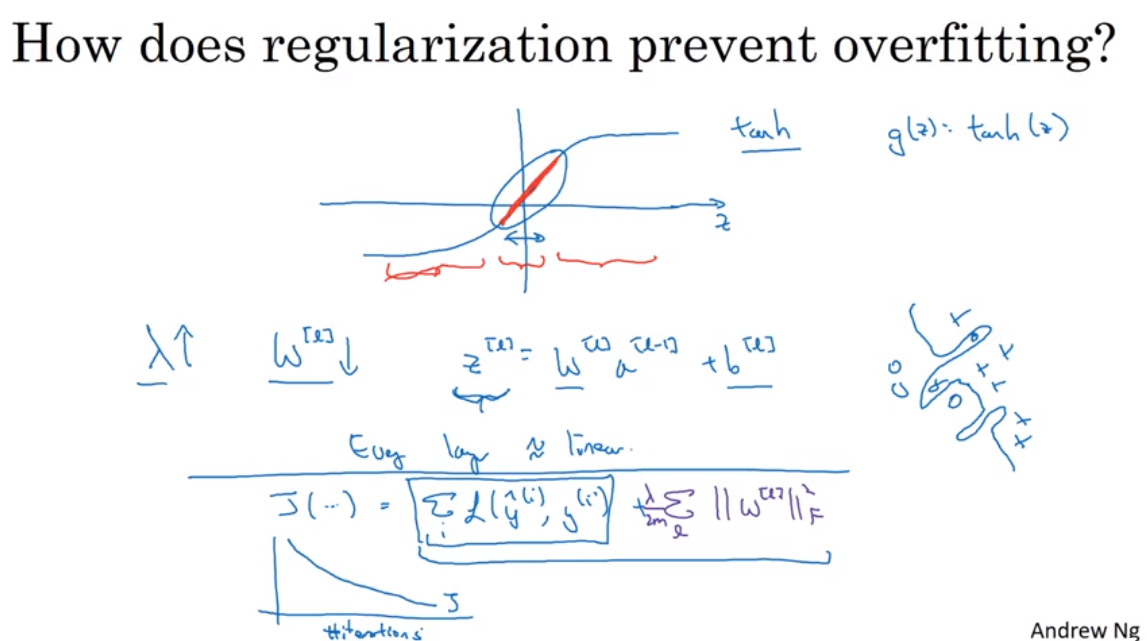
Regularization
- L2 regularation
- drop out
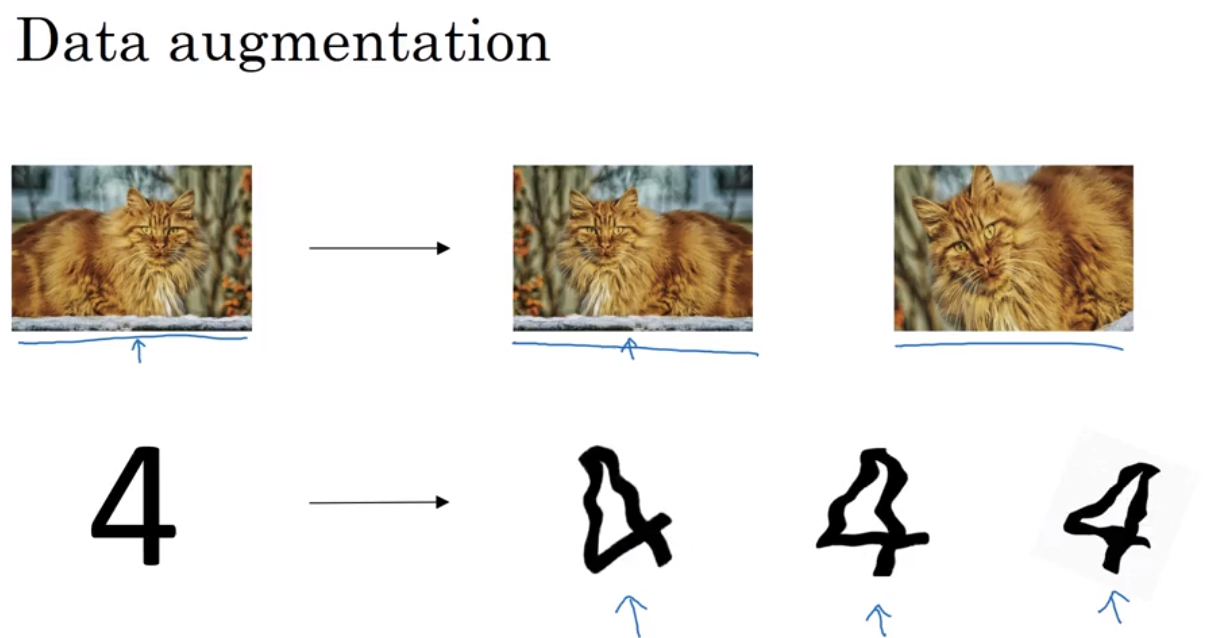
- data augmentation(翻转图片得到一个新的example), early stopping(画出J_train 和J_dev 对应于iteration的图像)
L2 regularization:

Forbenius Norm.
上面这张图提到了weight decay 的概念
Weight Decay: A regularization technique (such as L2 regularization) that results in gradient descent shrinking the weights on every iteration.
why regulation works(intuition)?
Dropout regularization:
下面的图只显示了forward propagation过程中使用dropout, back propagation 同样也需要drop out.

在对 test set 做预测的时候,不需要 drop out.

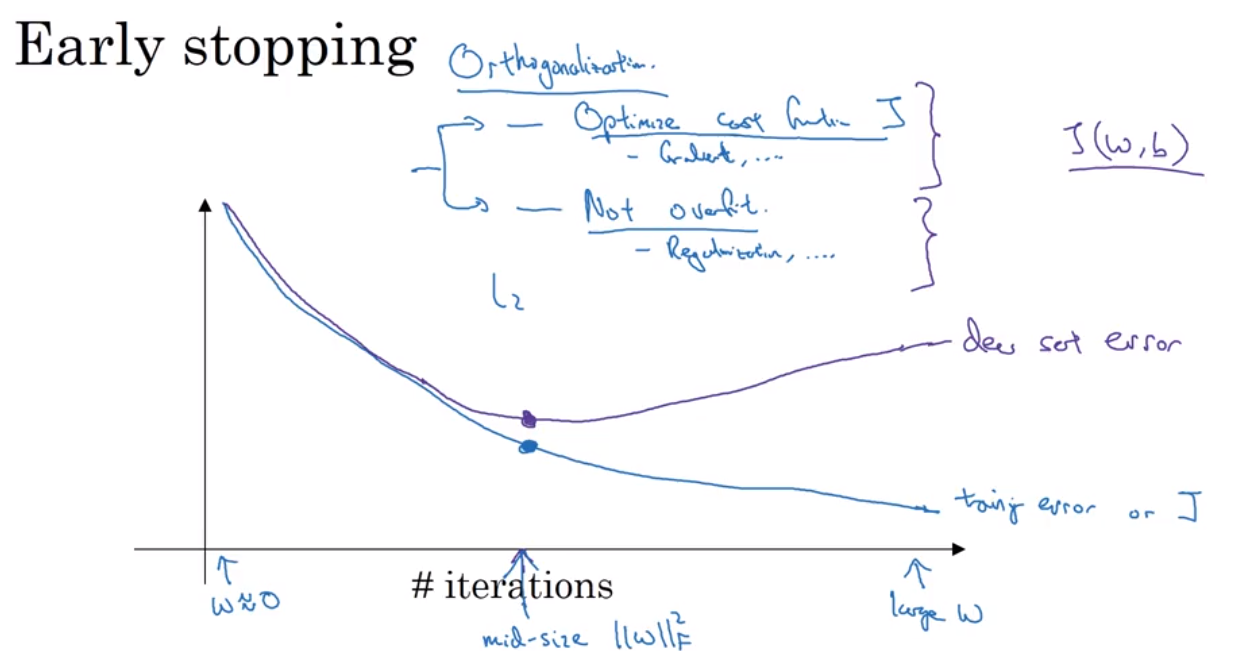
Early stopping: 缺点是违反了正交原则(Orthoganalization, 不同角度互不影响计算), 因为early stopping 同时关注Optimize cost func J, 和 Not overfit 两个任务,不是分开解决。一般建议用L2 regularization, 但是缺点是迭代次数多.
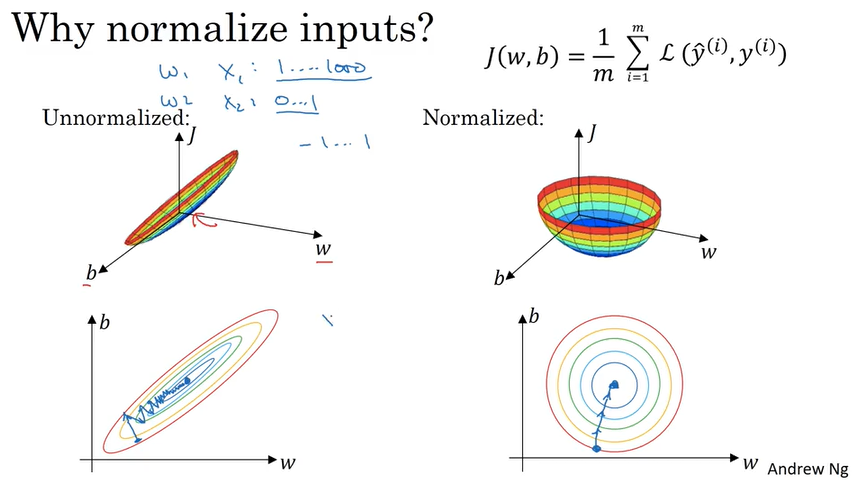
Normalizing input
就是把input x 转化成方差,公式如下
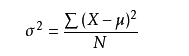
Vanishing/Exploding gradients
deep neural network suffer from these issues. they are huge barrier to training deep neural network.
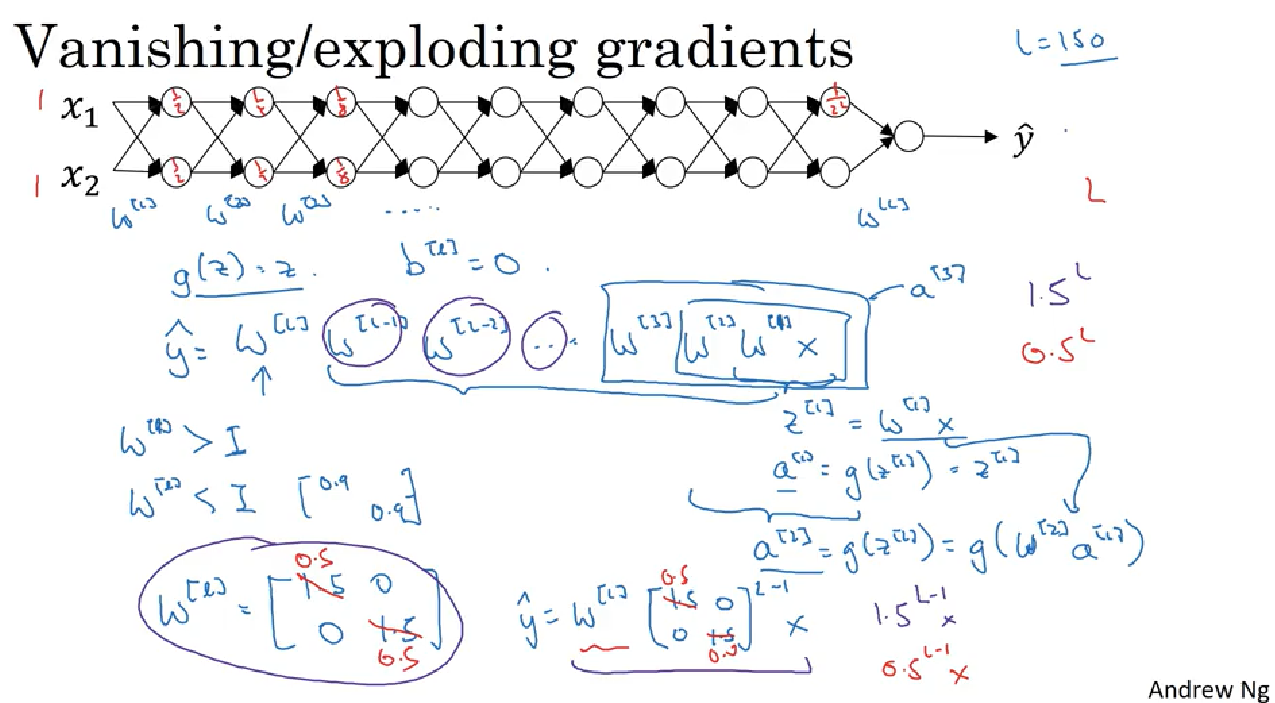
There is a partial solution to solve the above problem but help a lot which is careful choice how you initialize the weights. 主要目的是使得weight W[l]不要比1太大或者太小,这样最后在算W的指数级的时候就很大程度改善vanishing 和 exploding的问题.
如果用的是Relu activation, 就用中下部的蓝框的内容(He Initialization),如果是tanh activation 就用右边的蓝框的内容(Xavier initialization),也有些人对tanh用右边第二种
Weight Initialization for Deep Networks

Xavier initialization
Gradient Checking




Ref:
1. Coursera

 浙公网安备 33010602011771号
浙公网安备 33010602011771号