
Object Detection / Human Action Recognition 项目
https://towardsdatascience.com/real-time-and-video-processing-object-detection-using-tensorflow-opencv-and-docker-2be1694726e5
https://www.pyimagesearch.com/2018/11/12/yolo-object-detection-with-opencv/
https://www.pyimagesearch.com/2017/09/18/real-time-object-detection-with-deep-learning-and-opencv/
https://medium.com/@jonathan_hui/real-time-object-detection-with-yolo-yolov2-28b1b93e2088
Deep Learning for Videos:
https://medium.com/@jonathan_hui/object-detection-speed-and-accuracy-comparison-faster-r-cnn-r-fcn-ssd-and-yolo-5425656ae359
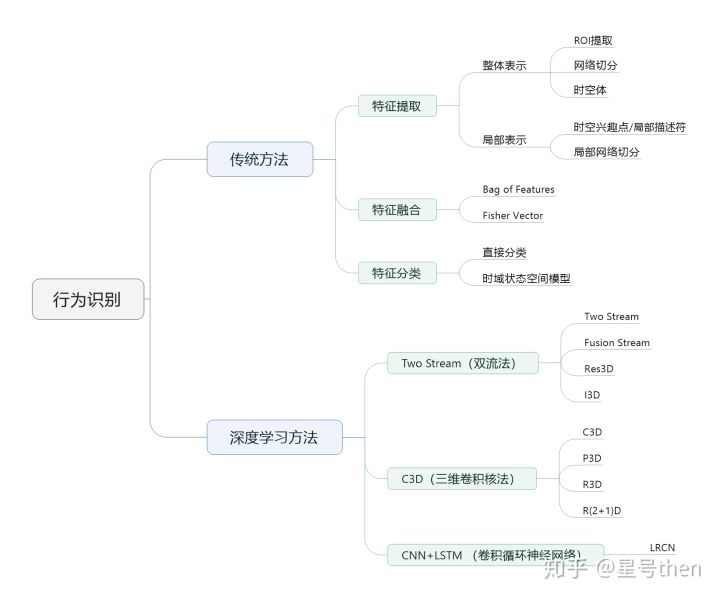
Human Action Recognition:
难点:
- 高的计算量
- 捕捉长的上下文context
- 什么网络合适(1. 是一个网络来捕获时空信息,还是时、空信息分别由不同网络捕获, 2, 怎么融合单帧的预测结果,3,是用E2E网络还是先提取特征再去分类)
- 数据集缺乏,之前长期用的是UCF101,Sports1M, 现在有Kinetics了情况有所改观
数据集:
算法:
2013年以前,传统算法的做法是先提取手工特征 (HOG,HOF,Dense Trajectories等)然后用分类器分类。传统算法里有名的有 improved Dense Trajectories (iDT), 同时期的深度学习方法 3D 卷积也在用但是那时候效果不好。 在2014年出来两篇突破性的Paper, 基本是后面的paper的主要来源,这两篇paper对时空信息的融合思路不一样。
Approach 1: Single Stream Network, 2014 Karpathy

Approach 2: Two Stream Networks, 2014 Simmoyan and Zisserman

“The method involved pre-computing optical flow vectors and storing them separately. Also, the training for both the streams was separate implying end-to-end training on-the-go is still a long road”[8]
预先计算光流是个很大的缺点
基于以上2个思路,和下图的几个基本思想,到2018为止有以下的算法:

- LRCN
- C3D
- Conv3D & Attention
- TwoStreamFusion
- TSN (pre-computing optical flow)
- ActionVlad
- HiddenTwoStream (可以自己生成光流了!!!用MotionNet)

- I3D
- T3D


| Model | HMDB-51 | UCF-101 | |
| I3D | 80.9% | 98.0% |
Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset (May 2017) |
总的来说多个分支都有最新研究出现,但是相对的基于骨架的图卷积方法和基于视频的3D conv方法更多一些。[1]
“Finally, the third trend focused on computational efficiency to scale to even larger datasets so that they could be adopted in real applications. Examples include Hidden TSN [278], TSM [128], X3D [44], TVN [161], etc”, 一些实时性高的模型 [9]
Ref:
- 一文了解通用行为识别ActionRecognition:了解及分类 (2020)
- 动作识别调研 (2018)
- 行为识别Action Detection概述及资源合集(持续更新...)
- https://zhuanlan.zhihu.com/p/33040925
- https://zhuanlan.zhihu.com/p/26460437
- 视频理解近期研究进展
- https://zhuanlan.zhihu.com/p/45444790
- Deep Learning for Videos: A 2018 Guide to Action Recognition - Summary of major landmark action recognition research papers till 2018
- https://zhuanlan.zhihu.com/p/337212192,A Comprehensive Study of Deep Video Action Recognition, AWS 李沐 团队, 2020 (2014-2020的综述)
分割算法
Understanding How Mask RCNN Works for Semactic Segmentation - https://ardianumam.wordpress.com/2017/12/16/understanding-how-mask-rcnn-works-for-semactic-segmentation/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号