
Coursera, Big Data 2, Modeling and Management Systems (week 4/5/6)
week4
streaming data format
下面讲 data lakes

schema-on-read: 从数据源读取raw data 直接放到 data lake 里,然后再读到model里
schema-on-write: 传统模式,把raw data 经过处理后放到data warehouse里,此时已经是结构化的数据,然后直接load 出来

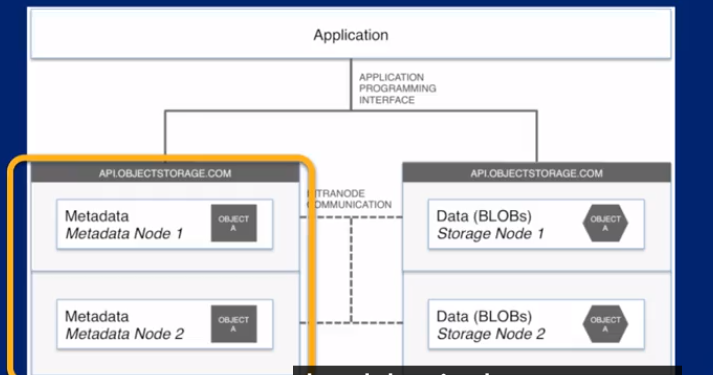
data lake summary

week5 - big data management
针对大数据,传统DBMS 需要提高的地方

some solutiion

from DBMS to BDMS
BDMS 应该具有的特征



BASE 就是基于CAP理论的

一些常用的BDMS及其优缺点
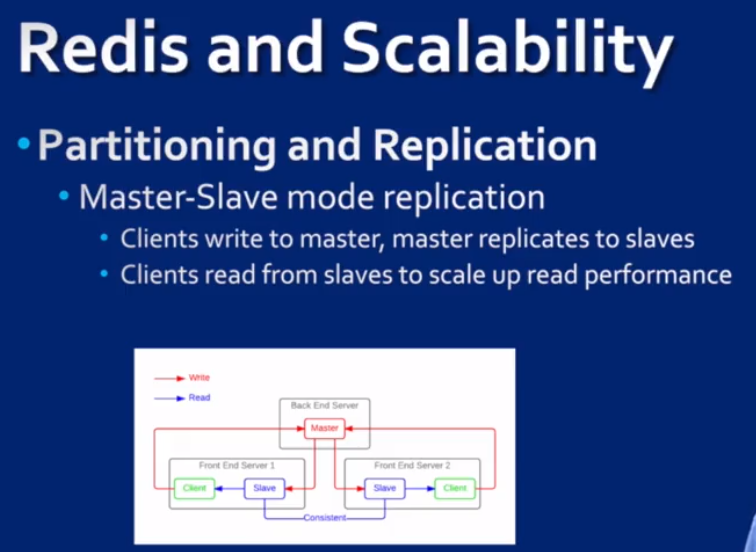
Redis: an enhanced key-value store




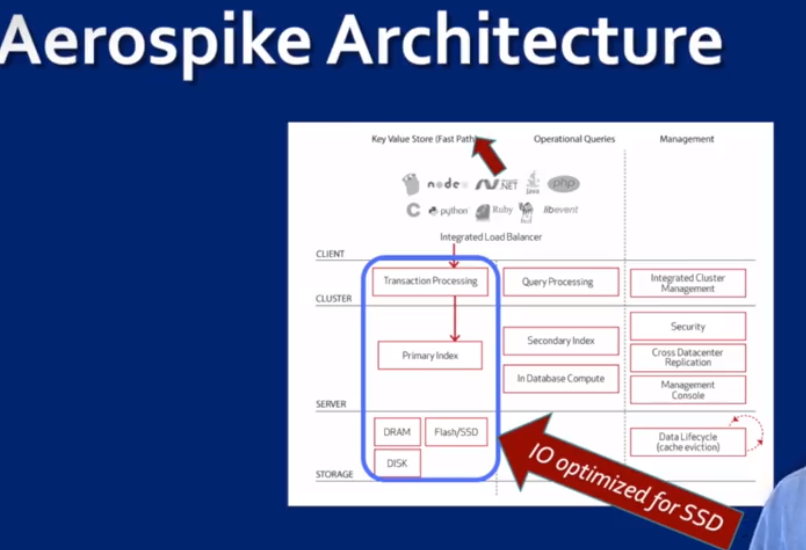
Aerospike: a new generation KV store
这是一个分布式NoSQL database + KV store. 是强一致性的



AsterixDB: a DBMS for semistructured data. 大家都知道的mongodb 以json 格式存储j数据, 这个Asterix 和 mongodb 类似. 它提供ACID保证.

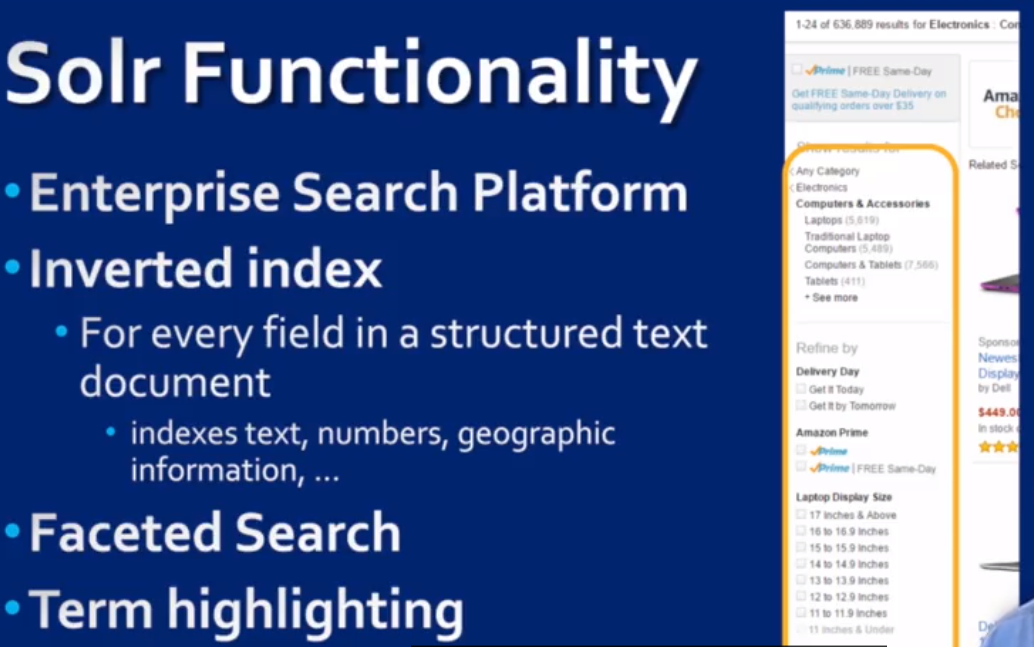
Solr : Text data searching. 基于Lucene的
应该是一种search engine, 不知道和 ES 什么区别.

反向索引,至少要包含 doc id list, 也可以包含更多信息

除了full text search, 还有下面的功能
Vertica:a columnar DBMS


 浙公网安备 33010602011771号
浙公网安备 33010602011771号