
Python爬虫常用之登录(三) 使用http请求登录
前面说了使用浏览器登录较为简单,不需要过多分析,而使用请求登录恰恰就是以分析为主.
开发一个请求登录程序的流程:
分析请求->模拟请求->测试登录->调整参数->测试登录->登录成功
一、分析网页
从网页着手,打开博客园的登录页面,F12调出网页调试,选择network的tab,然后登录,登录成功后大致有如下请求可以看到:
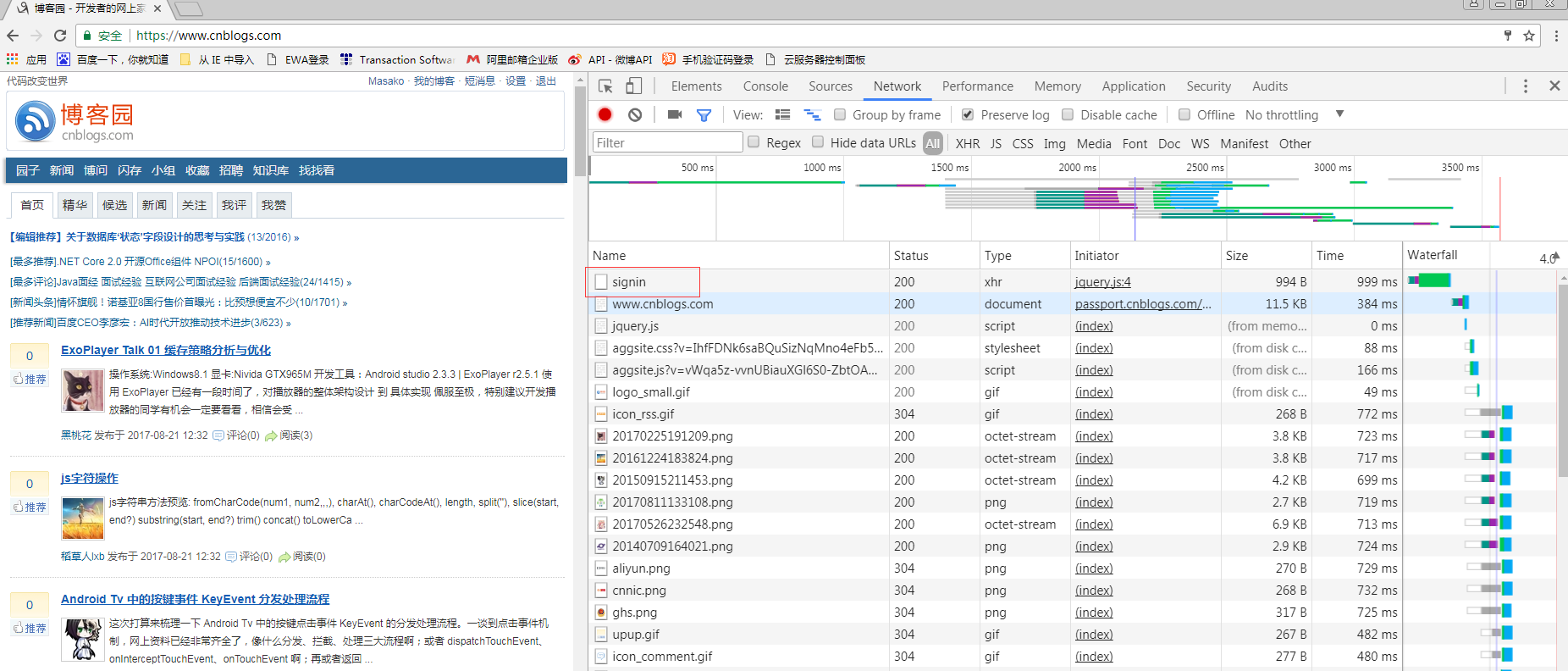
可以看到圈起来的signin请求,很明显这个就是登录的请求,别的网站也有叫login之类的,大同小异.
我们来仔细看一下这个请求.
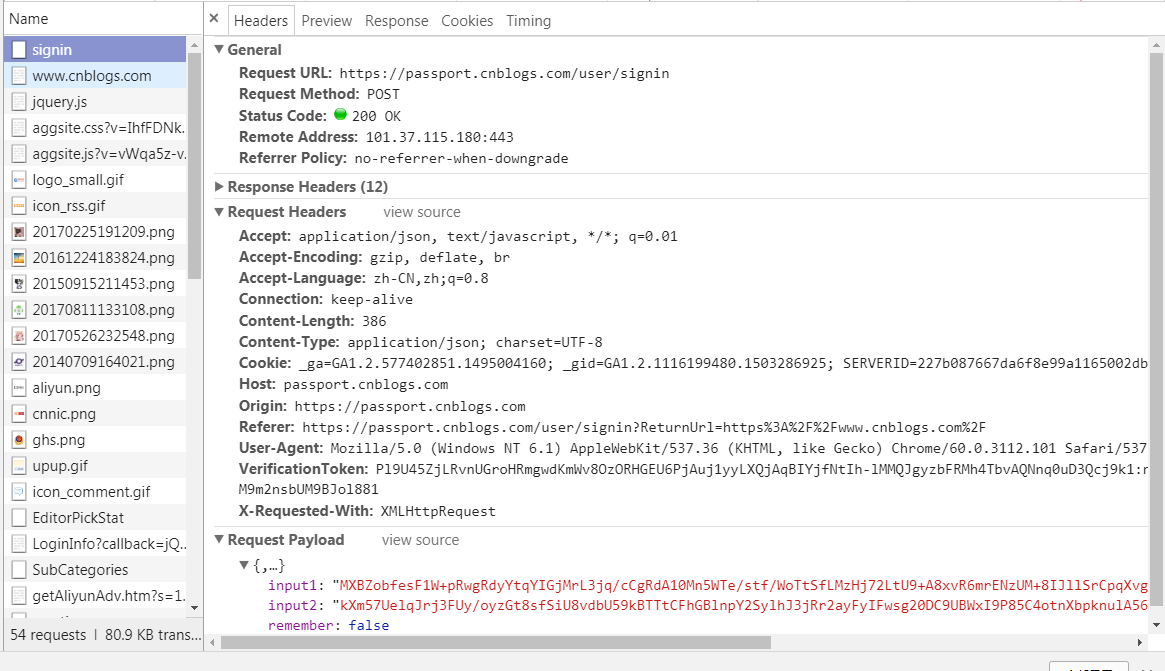
主要注意到:使用post方法,请求头一大堆,有三个参数.
先分析参数,根据上一篇的网页分析,大致可以猜到input1和input2这两个参数是用户名和密码,
remenber应该是是否记录的那个选框.这个试几次就知道是不是了,我们暂且都定死为false
接下来,把网页上的参数全部拷下来,模拟请求,看看结果
import requests session = requests.Session() url = "https://passport.cnblogs.com/user/signin" data = { "input1": "MXBZobfesF1W+pRwgRdyYtqYIGjMrL3jq/cCgRdA10Mn5WTe/stf/WoTtSfLMzHj72LtU9+A8xvR6mrENzUM+8IJllSrCpqXvgLgInBVQYpc4PTYfrYswrR3WL4oRu+5wUvUUSYGUFVDbHjPIXLk63WCbJs6uCCCXtReGoHQgSA=", "input2": "kXm57UelqJrj3FUy/oyzGt8sfSiU8vdbU59kBTTtCFhGBlnpY2SylhJ3jRr2ayFyIFwsg20DC9UBWxI9P85C4otnXbpknulA56AUYcTGsbaPSewX2+gU9+3+5LpKRxQFnufW+fkP5oiVESj/uV/9WeONAqaU52Z7UsNgxvr/L3Q=", "remember": False } headers = { "Accept": "application/json, text/javascript, */*; q=0.01", "Accept-Encoding": "gzip, deflate, br", "Accept-Language": "zh-CN,zh;q=0.8", "Connection": "keep-alive", "Host": "passport.cnblogs.com", "Origin": "https://passport.cnblogs.com", "Referer": "https://passport.cnblogs.com/user/signin?ReturnUrl=https%3A%2F%2Fwww.cnblogs.com%2F", "User-Agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.81 Safari/537.36", "VerificationToken": "Pl9U45ZjLRvnUGroHRmgwdKmWv8OzORHGEU6PjAuj1yyLXQjAqBIYjfNtIh-lMMQJgyzbFRMh4TbvAQNnq0uD3Qcj9k1:nxi3tgeeeOYyz7REolByuYtTow8Qw0AYQElwZ5vIj5oUJr-Tna1n2wG8WLaVNOIFNCyx_eiI2tWM9m2nsbUM9BJol881", "Upgrade-Insecure-Requests": "1", "X-Requested-With": "XMLHttpRequest", 'Content-Type': 'application/x-www-form-urlencoded' } r = session.post(url, headers=headers, data=data) print r print r.content
上面只是用到了requests的基本用法.可以看到打印出来的页面内容仍是登录页面,说明登录失败.
二、分析加密
看看input的格式,似乎是加密过的,我们先复制下来找个网页用base64解码看看,抱着一丝它只是简单base64编码过的希望.
事实证明,这个并不是简单地将用户名和密码使用base64编码一下,因为解码出来的全是乱码.可以自己试一下.
因为我最近一直在破解各种网站的登录方式,很容易能想到,多半是先用rsa加密过的.但是如果没有这种经历该怎么分析呢?
我们可以回到网页上面来,打开Elements,我们^F搜一下input1,发现不止在登录标签那里有,我们看看其他的,大多在header里面的<script>里面
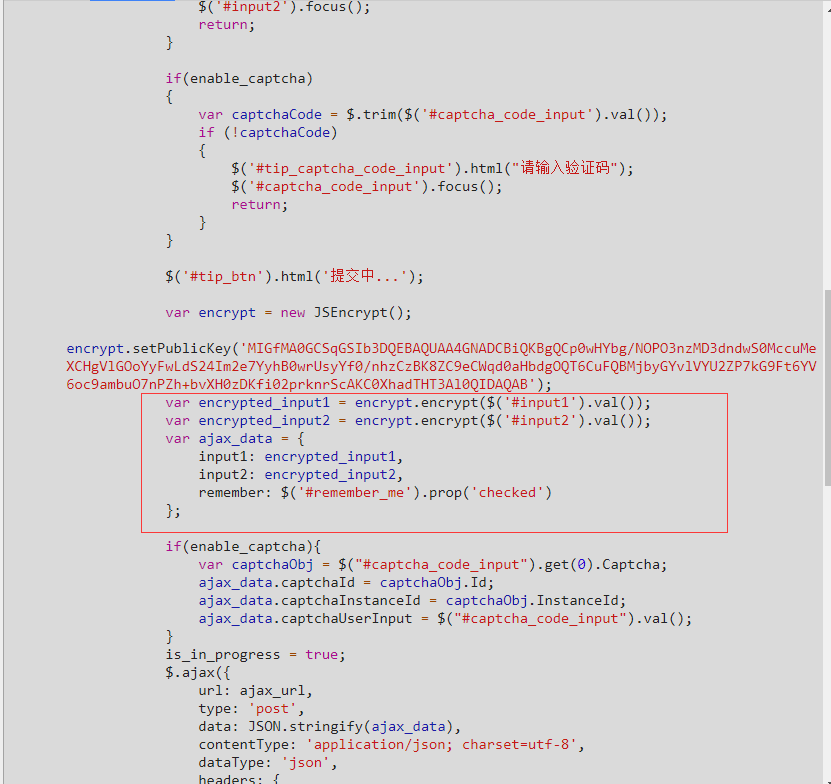
找到这个,可以看到仅仅是用js做了一个简单的加密,有兴趣的可以看下这个js代码(https://passport.cnblogs.com/scripts/jsencrypt.min.js),就是rsa.
这个也可以明显看到,remember这个参数确实就是网页上的下次自动登录标志.
我们在python里面直接选择rsa模块代替js的加密.
把网页上的公钥复制下来,作为公钥输入,填上自己的用户名和密码,使用rsa和base64加密看看
import rsa import base64 from web_encrypt import str2key username = "Masako" password = "123456" rsa_str = "MIGfMA0GCSqGSIb3DQEBAQUAA4GNADCBiQKBgQCp0wHYbg/NOPO3nzMD3dndwS0MccuMeXCHgVlGOoYyFwLdS24Im2e7YyhB0wrUsyYf0/nhzCzBK8ZC9eCWqd0aHbdgOQT6CuFQBMjbyGYvlVYU2ZP7kG9Ft6YV6oc9ambuO7nPZh+bvXH0zDKfi02prknrScAKC0XhadTHT3Al0QIDAQAB" pub_key = str2key(rsa_str) modulus = int(pub_key[0], 16) exponent = int(pub_key[1], 16) key = rsa.PublicKey(modulus, exponent) encrypt_name = rsa.encrypt(username, key) encrypt_pw = rsa.encrypt(password, key) input1 = base64.b64encode(encrypt_name) input2 = base64.b64encode(encrypt_pw) print input1 print input2
输出结果如下:
Q/+Aq2og1LeCQDPqVbfhUohK3R+hu0CTcCajTJC1mO/GqxSHWqUx2mrMMt3GJrSZ+Ip66dIh+0RpKbRPyk1Sqj/MV1+SL00HUQSgwZOdlQBl+gQfYEq6RSqjw2Id4gHXgb5TcG63Q8r2TEoEWk9Yi45sx2rbARG/2FuRZqYg8zQ= nFVRcbBqj7OcPHvIoznWrGUOfhq83rfN0f/nEBG/B+lSON6hUAnHCkwHg5S5nkOo+Avv7F1NrxskV/JI+ysbFHskjPp+T24X/vcjIj8VH68qW5u+4EtrQJGomOgefkXdKeA+A1eu7cAeZqDdGgf4d/Rb43A6S+dahvoGJSqiN1I=
可以看到,格式已经非常接近了,其实这就是需要填入请求的数据.
上面代码中的str2key()方法是我自己写的,主要功能就是将网页上的rsa公钥字符串转换成python可识别的格式.
因为百度了很久没有看到什么好的办法,所以自己写了一个,后面有时间再拿出来讲.
三、整合调试
现在把第一步和第二步结合起来,将第二步加密过的结果传到第一步中,试一下能否成功.


# /usr/bin/python # encoding: utf-8 import rsa import base64 import requests from web_encrypt import str2key def login(username, password): rsa_str = "MIGfMA0GCSqGSIb3DQEBAQUAA4GNADCBiQKBgQCp0wHYbg/NOPO3nzMD3dndwS0MccuMeXCHgVlGOoYyFwLdS24Im2e7YyhB0wrUsyYf0/nhzCzBK8ZC9eCWqd0aHbdgOQT6CuFQBMjbyGYvlVYU2ZP7kG9Ft6YV6oc9ambuO7nPZh+bvXH0zDKfi02prknrScAKC0XhadTHT3Al0QIDAQAB" pub_key = str2key(rsa_str) modulus = int(pub_key[0], 16) exponent = int(pub_key[1], 16) key = rsa.PublicKey(modulus, exponent) encrypt_name = rsa.encrypt(username, key) encrypt_pw = rsa.encrypt(password, key) input1 = base64.b64encode(encrypt_name) input2 = base64.b64encode(encrypt_pw) session = requests.Session() url = "https://passport.cnblogs.com/user/signin" data = { "input1": input1, "input2": input2, "remember": False } headers = { "Accept": "application/json, text/javascript, */*; q=0.01", "Accept-Encoding": "gzip, deflate, br", "Accept-Language": "zh-CN,zh;q=0.8", "Connection": "keep-alive", "Host": "passport.cnblogs.com", "Origin": "https://passport.cnblogs.com", "Referer": "https://passport.cnblogs.com/user/signin?ReturnUrl=https%3A%2F%2Fwww.cnblogs.com%2F", "User-Agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.81 Safari/537.36", "VerificationToken": "Pl9U45ZjLRvnUGroHRmgwdKmWv8OzORHGEU6PjAuj1yyLXQjAqBIYjfNtIh-lMMQJgyzbFRMh4TbvAQNnq0uD3Qcj9k1:nxi3tgeeeOYyz7REolByuYtTow8Qw0AYQElwZ5vIj5oUJr-Tna1n2wG8WLaVNOIFNCyx_eiI2tWM9m2nsbUM9BJol881", "Upgrade-Insecure-Requests": "1", "X-Requested-With": "XMLHttpRequest", 'Content-Type': 'application/x-www-form-urlencoded' } r = session.post(url, headers=headers, data=data) print r print r.content if __name__ == "__main__": username = "Masako" password = "*****" login(username, password)
代码多了起来,写了个函数包裹一下啊啊啊
试一下,还是会失败.
再回头看一下signin这个请求,它的请求头除了常见的几个参数,也没有cookie什么的用来识别身份的,不算特别......等等,好像看到了一个很陌生的字段
VerificationToken是个什么鬼,貌似忽略了这个.反复登录几次比较一下请求记录,这个值每次都不一样,说明它是在变的.
那么怎么获取到这个变化的值呢,一般我会从两方面着手:1.看看有没有单独请求这个参数的network记录,2.看看网页上有没有相关字段.
这里,在网页上就可以找到这个字段:
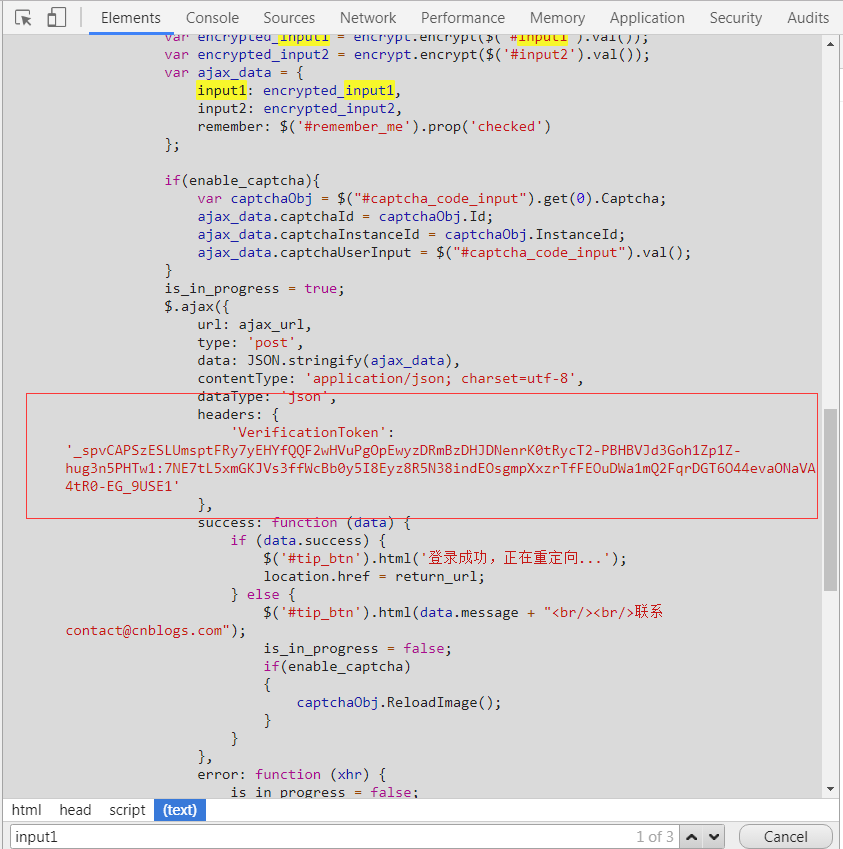
就在第二步加密代码的下面.
其实第一步分析请求的时候,我们就可以注意到这个参数的问题,但是由于经验不足或者说粗心大意,到现在才去修正它.
这个ajax就是构造登录请求的代码.可以看到,它也是设置了一个headers.
我选择访问网页,使用正则,获取到这个字段
代码如下:
import re import requests headers = { "Accept": "application/json, text/javascript, */*; q=0.01", "Accept-Encoding": "gzip, deflate, br", "Accept-Language": "zh-CN,zh;q=0.8", "Connection": "keep-alive", "Host": "passport.cnblogs.com", "Origin": "https://passport.cnblogs.com", "Referer": "https://passport.cnblogs.com/user/signin?ReturnUrl=https%3A%2F%2Fwww.cnblogs.com%2F", "User-Agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.81 Safari/537.36", } url = "https://passport.cnblogs.com/user/signin" session = requests.Session() r = session.get(url, headers=headers) tmp = re.findall("'VerificationToken':(.*?)}", r.content, re.S) token = tmp[0].strip() token = token.strip("'\r\n") print token
将这段代码添加到登录程序中
并把token传到登录请求的请求头中
# /usr/bin/python # encoding: utf-8 import re import rsa import base64 import requests from web_encrypt import str2key def login(username, password): rsa_str = "MIGfMA0GCSqGSIb3DQEBAQUAA4GNADCBiQKBgQCp0wHYbg/NOPO3nzMD3dndwS0MccuMeXCHgVlGOoYyFwLdS24Im2e7YyhB0wrUsyYf0/nhzCzBK8ZC9eCWqd0aHbdgOQT6CuFQBMjbyGYvlVYU2ZP7kG9Ft6YV6oc9ambuO7nPZh+bvXH0zDKfi02prknrScAKC0XhadTHT3Al0QIDAQAB" pub_key = str2key(rsa_str) modulus = int(pub_key[0], 16) exponent = int(pub_key[1], 16) key = rsa.PublicKey(modulus, exponent) encrypt_name = rsa.encrypt(username, key) encrypt_pw = rsa.encrypt(password, key) input1 = base64.b64encode(encrypt_name) input2 = base64.b64encode(encrypt_pw) session = requests.Session() url = "https://passport.cnblogs.com/user/signin" headers = { "Accept": "application/json, text/javascript, */*; q=0.01", "Accept-Encoding": "gzip, deflate, br", "Accept-Language": "zh-CN,zh;q=0.8", "Connection": "keep-alive", "Host": "passport.cnblogs.com", "Origin": "https://passport.cnblogs.com", "Referer":"https://passport.cnblogs.com/user/signin?ReturnUrl=https%3A%2F%2Fwww.cnblogs.com%2F", "User-Agent":"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.81 Safari/537.36", } data = { "input1": input1, "input2": input2, "remember": False } before = session.get(url, headers=headers) tmp = re.findall("'VerificationToken':(.*?)}", before.content, re.S) token = tmp[0].strip() token = token.strip("'\r\n") headers["VerificationToken"] = token headers["X-Requested-With"] = "XMLHttpRequest" r = session.post(url, headers=headers, data=data) print r print r.content if __name__ == "__main__": username = "Masako" password = "*****" login(username, password)
填入正确的用户名和密码,返回:
{"success":true}
表示登录成功!大功告成.
只需要保存r.cookie就可以访问博客园里面需要登录才能访问的内容哦.
直接使用这个登录过的session也是可以的!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号