TensorRT 部署
 NVIDIA® TensorRT™是一款用于NVIDIA GPU上的高性能深度学习推理的SDK。该存储库包含TensorRT的开源组件。
NVIDIA® TensorRT™是一款用于NVIDIA GPU上的高性能深度学习推理的SDK。该存储库包含TensorRT的开源组件。
1 了解 TensorRT
1.1 什么是 TensorRT
TensorRT 是英伟达官方提供的一个高性能深度学习推理优化库,支持 C++ 和 Python 两种编程语言 API,主要应用于边缘设备的推理。TensorRT 可以将训练好的模型分解再进行融合,融合后的模型具有高度的集合度,其直接利用 CUDA 以在显卡上运行,所有的代码库仅仅包括 C++ 和 CUDA,在利用此优化库运行代码时,运行速度和所占内存的大小都会大大缩减。
以下是 TensorRT 的一些主要特点和功能:postp
- 高效的推理加速:TensorRT 可以对经过训练的神经网络模型进行精简优化,以便在 NVIDIA GPU 上进行更高效的推理,减少延迟并提高吞吐量。
- 支持混合精度:支持混合精度推理,包括半精度 (FP16) 和 8 位整数 (INT8) 推理,以提高性能和减少内存占用,同时尽量保持模型的精度。
- 支持动态输入形状:TensorRT 支持动态输入大小(Dynamic Shapes),允许模型在推理时接受不同大小的输入,而无需固定输入尺寸。
- 支持多种学习框架:TensorRT 兼容主流的深度学习框架,包括 TensorFlow、PyTorch 和 ONNX 等,可以通过将模型转换为 TensorRT 格式来进行推理加速。
- 支持插件:TensorRT 支持自定义插件,允许用户编写自定义层,扩展 TensorRT 的功能,处理一些模型中不常见的算子。
1.2 TensorRT 优化方法
TensorRT 采用多种优化技术来提升深度学习模型的推理性能:
-
层间融合技术:
TensorRT 通过层间融合,将卷积层、偏置层和 ReLU 激活层合并为单一的 CBR 结构,实现横向和纵向的层融合。横向融合将这些层合并为单一操作,仅消耗一个 CUDA 核心,而纵向融合则将具有相同结构但不同权重的层合并成更宽的层,同样只占用一个 CUDA 核心。这种融合减少了计算图中的层数,降低了 CUDA 核心的使用量,从而使得模型结构更加紧凑、运行速度更快、效率更高。 -
数据精度优化:
在深度学习模型训练过程中,通常使用 32 位浮点数(FP32)来保证精度。然而,在推理阶段,由于不需要进行反向传播,可以安全地降低数据精度至 FP16 或 INT8,这不仅减少了内存占用和延迟,还使得模型体积更小,提高了推理速度。 -
Kernel自动调优:
TensorRT 能够自动调整 CUDA 核心的计算方式,以适应不同的算法、模型结构和 GPU 平台。这种自动调优确保了模型在特定硬件上以最佳性能运行。 -
平台特定的优化:
针对不同的 GPU 平台,如 NVIDIA 的 3090 和 T4,需要在各自的平台上进行 TensorRT 模型的转换和优化。这意味着不能在一种平台上完成转换后,直接在另一种平台上使用,而应该针对每个目标平台进行专门的优化和部署。
1.3 使用 TensorRT 的推理阶段
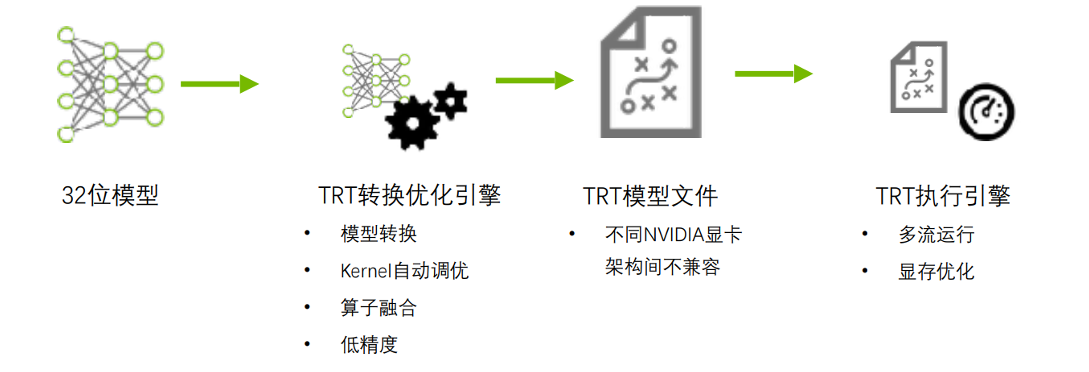
训练好的模型使用 TensorRT 推理的过程主要可以分为两个主要阶段:
- 构建(Build)阶段:在这个阶段,训练好的模型(如 PyTorch、TensorFlow、ONNX 等格式)需要通过 TensorRT 的工具(如 trtexec)或 API转换为 .engine 引擎文件。该过程涉及对模型进行优化,如层融合、算子优化、权重量化等,以便生成一个针对目标硬件(如 GPU 或 DLA)高效运行的推理引擎。
- 运行时(Runtime)阶段:在这个阶段,转换后的 TensorRT 引擎可以在目标设备上进行推理。这一阶段通过加载 TensorRT 引擎文件(.engine)进行实际的推理计算,支持在 GPU 或 DLA(Deep Learning Accelerator) 上运行,以提高推理速度和效率。
每个阶段具体的操作如下图所示:
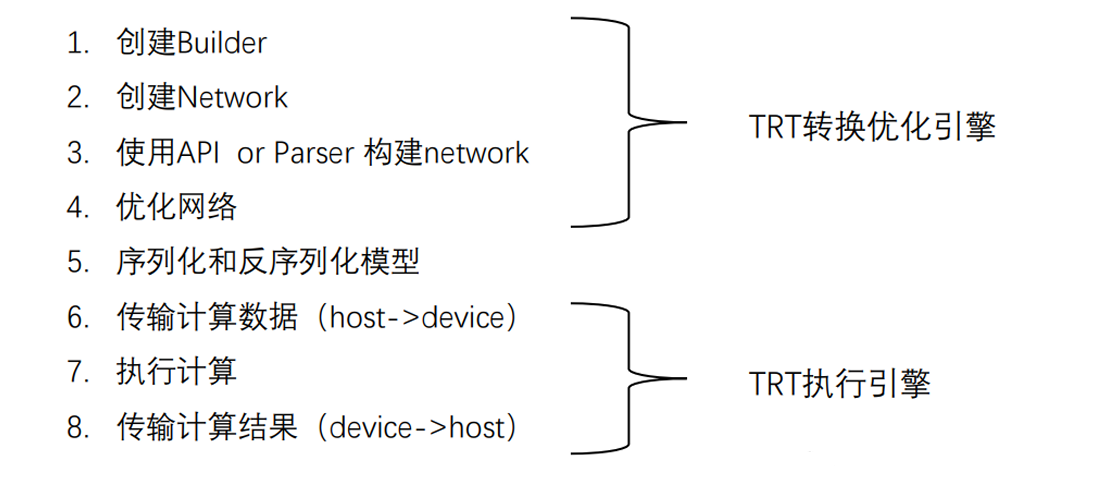
需要注意的是,在进行优化网络前需要基于训练好的模型构建出 TensorRT 网络,构建该网络主要有以下两种方式:
- API 构建:你手动使用 TensorRT 的 API 来逐层定义模型网络结构。
- Parser 构建:你通过 Parser 自动解析并加载现有的模型文件(如 ONNX、Caffe 模型),快速构建网络。
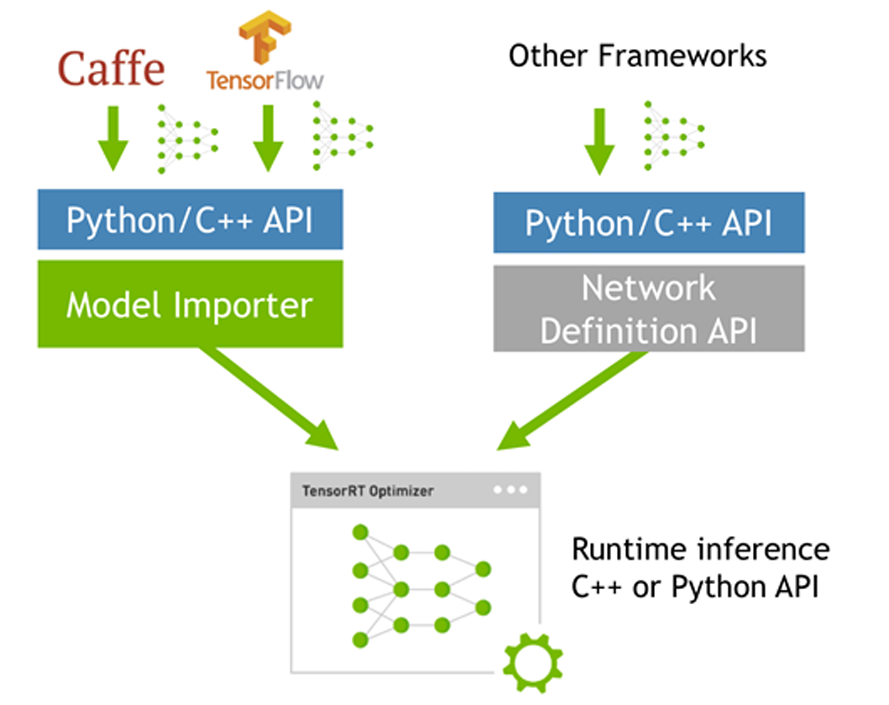
API 构建方式提供了对模型层级和参数的完全控制,允许精细调整和优化,以最大限度地发挥硬件性能和满足特定的精度要求。然而,这种方式复杂度较高,需要深入理解 TensorRT 的 API,且开发时间较长。适用于需要高度定制化和精细优化的场景。
而 Parser 构建方式通过解析现有模型文件(如 ONNX)快速构建模型,简化了开发流程,节省了时间。尽管自动化程度高、开发速度快,但对模型精度和优化的控制较少,适合已有模型的快速迁移和部署,尤其是在转换精度要求不高的情况下。
1.4 TensorRT 的安装
在已经安装好 CUDA 和 cuDNN 的前提下,安装 TensorRT 的详细步骤如下所示:
-
前往 Nvidia 官网选择最新的 TensorRT 进行下载,推荐下载适合自己 CUDA 版本的 GA 版:
注意
TensorRT 的 GA 版是稳定的生产版本,适用于正式环境,而 EA 版是包含新功能的早期访问版本,适合开发和测试。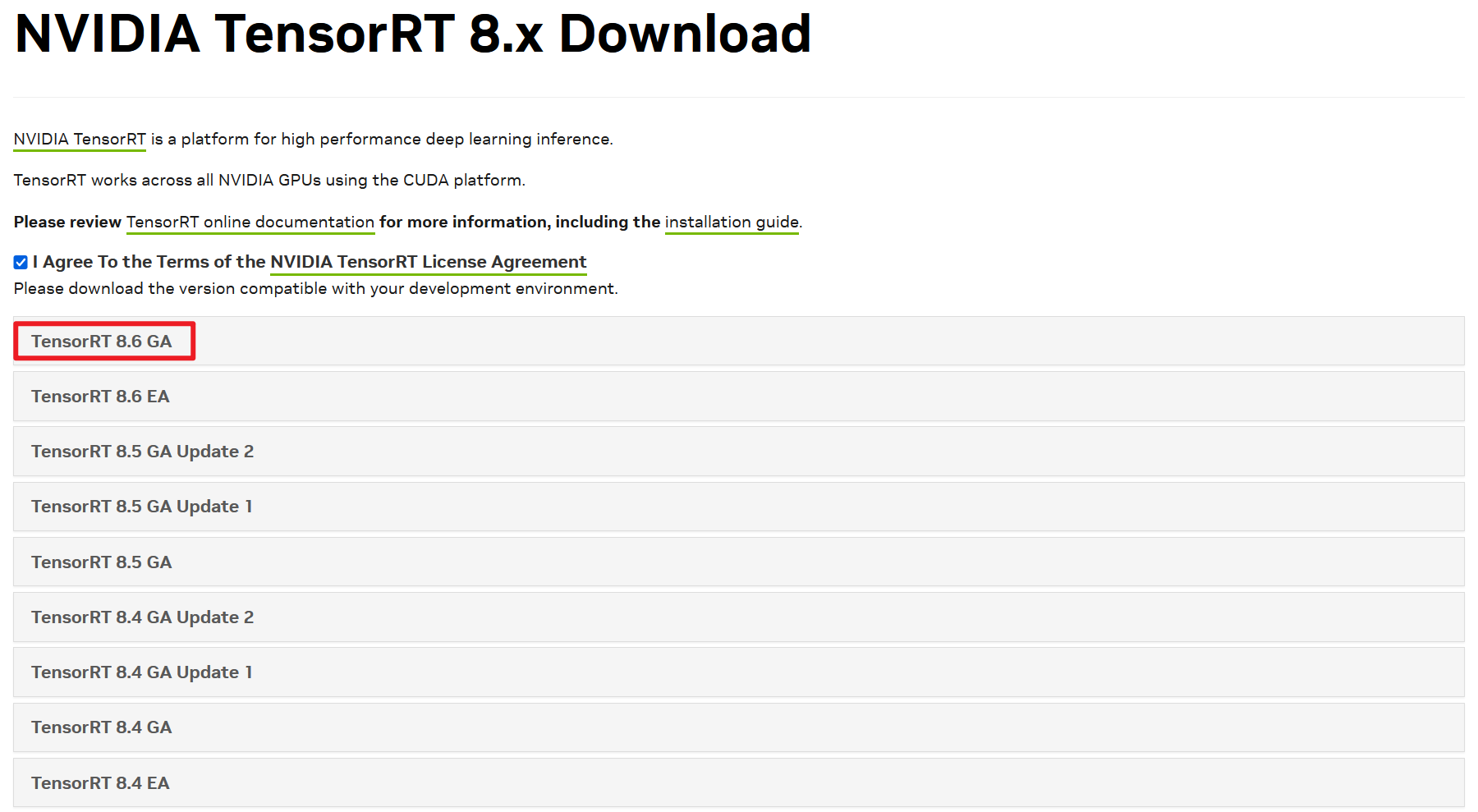
-
解压下载的 ZIP 文件,解压后的目录结构如下所示:
-
从解压好的文件夹中复制相关文件到 CUDA 的安装目录中,具体的复制规则如下表所示:
待复制文件 目标路径 …\TensorRT-8.6.1.6\bin\trtexec.exeC:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8\bin…\TensorRT-8.6.1.6\include\*C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8\include…\TensorRT-8.6.1.6\lib\*.libC:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8\lib\x64…\TensorRT-8.6.1.6\lib\*.dllC:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8\lib -
首先进入
...\TensorRT-8.6.1.6\graphsurgeon目录后安装 graphsurgeon-0.4.6-py2.py3-none-any.whl:pip install graphsurgeon-0.4.6-py2.py3-none-any.whl -
然后进入
...\TensorRT-8.6.1.6\onnx_graphsurgeon目录后安装 onnx_graphsurgeon-0.3.12-py2.py3-none-any.whl:pip install onnx_graphsurgeon-0.3.12-py2.py3-none-any.whl -
再然后进入
...\TensorRT-8.6.1.6\uff目录后安装 uff-0.6.9-py2.py3-none-any.whl:pip install uff-0.6.9-py2.py3-none-any.whl -
最后进入
...\TensorRT-8.6.1.6\python目录后,根据自己环境的 Python 版本选择合适的 tensorrt-8.6.1-cpxx-none-win_amd64.whl 进行安装: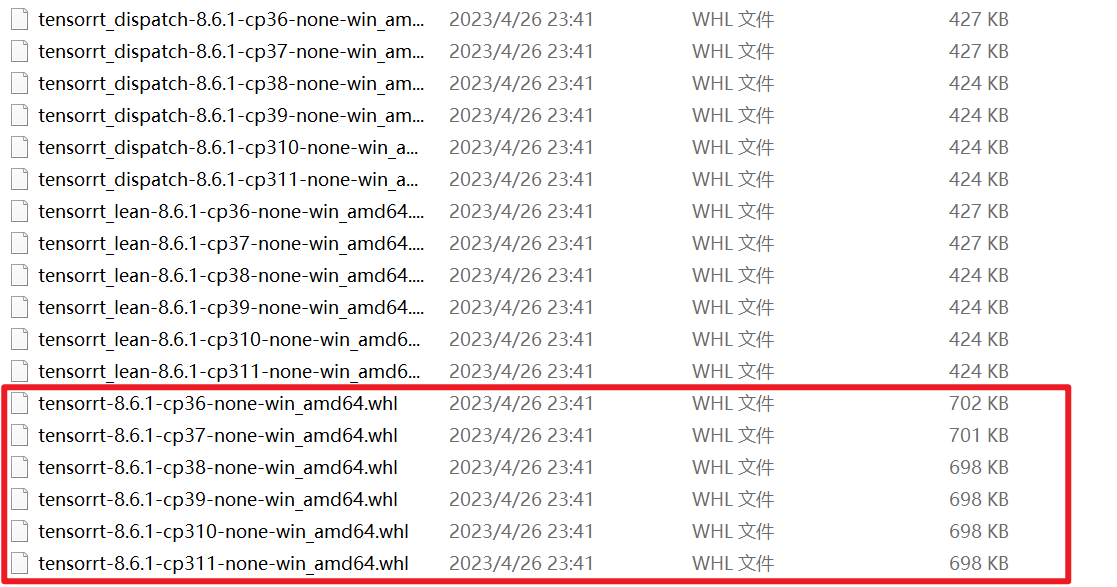
我的 Python 版本是 3.10,所以安装命令如下:
pip install tensorrt-8.6.1-cp310-none-win_amd64.whl -
在 CMD 中输入
python命令进入 Python 编译环境,再输入以下代码验证 TensorRT 是否安装成功:import tensorrt执行该命令可能报
Could not find: nvinfer.dll的错误:

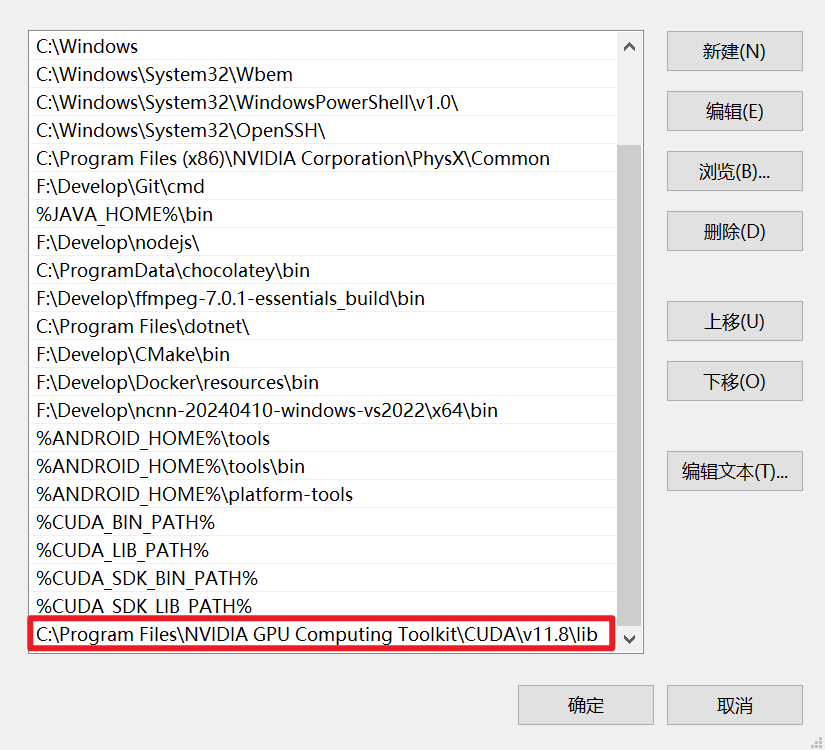
这是由于我们在第 3 步时将一些 dll 文件拷贝到了
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8\lib目录下但未配置 Path 环境变量,所以只需要将该路径配置为 Path 环境变量即可:
如果 TensorRT 安装成功,则不会有任何报错信息:

1.5 Ubuntu 安装参考
2 Python 构建推理
在本节将以一个实际的模型案例(LeNet5)展示使用 Python 来实现 TensorRT 的构建和推理。
2.1 Python 环境搭建
2.1.1 相关依赖库安装
首先,你需要创建一个新的 Conda 环境,用于安装所需的依赖库:
# 创建新的 Conda 环境
conda create -n trt_deploy python=3.10 -y
# 激活环境
conda activate trt_deploy
接着安装演示 Python 构建推理的必要依赖库:
-
PyTorch
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118PyTorch 用来定义和训练深度学习模型(LeNet-5),并将模型导出为 ONNX 格式。
-
onnx
pip install onnx==1.16.0onnx 库是将训练好的 PyTorch 模型导出为 ONNX 格式的必须依赖。
-
tqdm
pip install tqdmtqdm 库将提供演示过程中训练和测试的进度条显示,帮助实时跟踪模型训练和评估的进度。
-
pycuda
pip install pycudapycuda 库在推理过程中提供 Python 的 API 来管理 CUDA 计算和内存。
-
TensorRT
TensorRT 将 ONNX 模型转换为 TensorRT 引擎并进行推理。参考《1.4 TensorRT 的安装》中有详细的安装步骤。
2.1.2 训练和导出 ONNX 模型
以下是生成 ONNX 模型文件的代码示例。这段代码包括定义 LeNet-5 模型、训练模型、并将其导出为 ONNX 文件:
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import tqdm
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision.datasets import MNIST
# 定义LeNet-5模型
class LeNet5(nn.Module):
def __init__(self):
super(LeNet5, self).__init__()
self.conv1 = nn.Conv2d(1, 6, kernel_size=5)
self.conv2 = nn.Conv2d(6, 16, kernel_size=5)
self.fc1 = nn.Linear(16 * 4 * 4, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.max_pool2d(x, 2)
x = F.relu(self.conv2(x))
x = F.max_pool2d(x, 2)
x = x.view(-1, 16 * 4 * 4)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
if __name__ == '__main__':
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,)) # 正则化处理
])
train_dataset = MNIST('./data', train=True, download=True, transform=transform)
test_dataset = MNIST('./data', train=False, download=True, transform=transform)
train_dataloader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_dataloader = DataLoader(test_dataset, batch_size=64, shuffle=True)
device = 'cuda' if torch.cuda.is_available() else 'cpu'
num_epochs = 100
model = LeNet5().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
scheduler = optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=100)
best_acc = 0
for epoch in range(1, 1 + num_epochs):
model.train()
train_total_loss = 0
train_total_acc = 0
for data, target in tqdm.tqdm(train_dataloader, desc='Training', delay=0.01, total=len(train_dataloader)):
data, target = data.to(device), target.to(device)
output = model(data)
optimizer.zero_grad()
loss = criterion(output, target)
loss.backward()
optimizer.step()
train_total_loss += loss.item()
train_total_acc += (output.argmax(dim=1) == target).sum().item()
train_avg_loss = train_total_loss / len(train_dataloader)
train_avg_acc = train_total_acc / len(train_dataloader.dataset)
print(f"Epoch: {epoch}, Loss: {train_avg_loss}, Acc: {train_avg_acc}")
model.eval()
test_total_loss = 0
test_total_acc = 0
for data, target in tqdm.tqdm(test_dataloader, desc='Testing', delay=0.01, total=len(test_dataloader)):
data, target = data.to(device), target.to(device)
output = model(data)
loss = criterion(output, target)
test_total_loss += loss.item()
test_total_acc += (output.argmax(dim=1) == target).sum().item()
test_avg_loss = test_total_loss / len(test_dataloader)
test_avg_acc = test_total_acc / len(test_dataloader.dataset)
if test_avg_acc > best_acc:
best_acc = test_avg_acc
# 导出成onnx模型
torch.onnx.export(
model,
torch.randn(1, 1, 28, 28).to(device),
"lenet5.onnx",
opset_version=11,
input_names=['input'],
output_names=['output'],
dynamic_axes={
'input': {0: 'batch_size'},
'output': {0: 'batch_size'}
},
)
print(f"Epoch: {epoch}, Loss: {test_avg_loss}, Acc: {test_avg_acc}, Best Acc: {best_acc}")
scheduler.step()
2.1.3 验证 ONNX 模型
以下代码用于验证导出的 ONNX 模型是否能够正确执行推理并计算其在 MNIST 测试集上的准确率。使用 ONNX Runtime 在 GPU 或 CPU 上运行推理,并通过批量处理方式计算整个测试集的准确率:
import onnxruntime as ort
import torch
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision.datasets import MNIST
import tqdm
if __name__ == '__main__':
batch_size = 100
device = 'cuda' if torch.cuda.is_available() else 'cpu'
model = ort.InferenceSession("lenet5.onnx", providers=["GPUExecutionProvider"])
# 得到输入、输出结点的名称
input_node_name = model.get_inputs()[0].name
output_node_name = model.get_outputs()[0].name
# 获取输入的shape
shape = model.get_inputs()[0].shape
transform = transforms.Compose([
transforms.Resize((shape[2], shape[3])), # 调整图像大小
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,)), # 正则化处理
])
test_dataset = MNIST('./data', train=False, download=True, transform=transform)
test_dataloader = DataLoader(test_dataset, batch_size=batch_size, shuffle=True)
test_total_acc = 0
for data, target in tqdm.tqdm(test_dataloader, desc='Testing', delay=0.01, total=len(test_dataloader)):
data, target = data.numpy(), target.numpy()
output = model.run([output_node_name], {input_node_name: data})[0]
test_total_acc += (output.argmax(axis=1) == target).sum()
test_avg_acc = test_total_acc / len(test_dataloader.dataset)
print(f"Acc: {test_avg_acc}")
2.2 构建引擎文件
2.2.1 使用 Parser 构建
TensorRT ONNX Parser 提供了一个方便的方法来将已经训练好的 ONNX 模型转换为 TensorRT 引擎文件。此方法比较简单,适用于处理已经定义好的网络结构。
以下是如何使用 TensorRT 的 ONNX Parser 自动构建 LeNet-5 引擎文件的示例代码:
import tensorrt as trt
def build_engine(onnx_file_path, engine_file_path):
TRT_LOGGER = trt.Logger(trt.Logger.WARNING)
builder = trt.Builder(TRT_LOGGER)
# 创建显式批次模式的网络定义
network = builder.create_network(1 << int(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH))
parser = trt.OnnxParser(network, TRT_LOGGER)
# 读取 ONNX 文件并解析
with open(onnx_file_path, 'rb') as model:
if not parser.parse(model.read()):
print('Failed to parse the ONNX file')
for error in range(parser.num_errors):
print(parser.get_error(error))
return None
# 创建配置对象
config = builder.create_builder_config()
# 设置工作空间大小
config.set_memory_pool_limit(trt.MemoryPoolType.WORKSPACE, 1 << 32) # 1 GB
# 启用 FP16 优化
if builder.platform_has_fast_fp16:
config.set_flag(trt.BuilderFlag.FP16)
# 创建优化配置文件(如果有动态输入)
profile = builder.create_optimization_profile()
input_tensor = network.get_input(0) # 获取输入张量
input_shape = input_tensor.shape
input_name = input_tensor.name
# 根据ONNX输入的shape调整profile的min/opt/max形状
min_shape = trt.Dims([1, input_shape[1], 28, 28])
opt_shape = trt.Dims([64, input_shape[1], 28, 28])
max_shape = trt.Dims([128, input_shape[1], 28, 28])
profile.set_shape(input_name, min_shape, opt_shape, max_shape)
config.add_optimization_profile(profile)
# 构建并序列化网络
engine = builder.build_serialized_network(network, config)
if engine is None:
print('Failed to build the engine')
return None
# 保存序列化的engine
with open(engine_file_path, 'wb') as f:
f.write(engine)
return engine
if __name__ == '__main__':
# 调用构建引擎的函数,将 ONNX 模型转换为 TensorRT 引擎
engine = build_engine('lenet5.onnx', 'lenet5.engine')
2.2.2 使用 Python API 构建
使用 TensorRT 的 Python API 构建引擎文件可以提供更大的灵活性,允许开发者手动控制网络结构和各层的细节。这种方法适用于需要自定义网络架构或对模型进行特殊优化的场景。
以下是如何使用 TensorRT 的 Python API 手动构建 LeNet-5 引擎文件的示例代码:
import numpy as np
import onnx
import tensorrt as trt
def extract_onnx_weights(onnx_file_path):
# 加载 ONNX 模型
model = onnx.load(onnx_file_path)
weights_dict = {}
# 遍历模型中的初始化器(权重部分)
for initializer in model.graph.initializer:
# 将权重转换为 NumPy 数组
weight_array = np.frombuffer(initializer.raw_data, dtype=np.float32)
# 根据权重名称和维度将其存储到字典中
weights_dict[initializer.name] = weight_array.reshape(initializer.dims)
return weights_dict
def create_fully_connected_layer(network, input_itensor, weights_dict, layer_name):
# 从权重字典中获取当前层的权重
weight_np = weights_dict[layer_name + '.weight']
# 将权重转换为 TensorRT Weights 对象
weight_trt = trt.Weights(weight_np)
# 创建常量层以加载权重
weight_layer = network.add_constant(weight_np.shape, weight_trt)
weights_itensor = weight_layer.get_output(0)
# 创建矩阵乘法层,实现全连接层的计算
fc = network.add_matrix_multiply(
input0=input_itensor, op0=trt.MatrixOperation.NONE, # 默认操作
input1=weights_itensor, op1=trt.MatrixOperation.TRANSPOSE # 权重矩阵通常需要转置
)
# 从权重字典中获取偏置并添加偏置
bias_np = weights_dict[layer_name + '.bias'][None]
if bias_np is not None:
bias_trt = trt.Weights(bias_np)
bias_layer = network.add_constant(bias_np.shape, bias_trt)
bias_itensor = bias_layer.get_output(0)
# 添加加法操作,将偏置与全连接输出相加
fc = network.add_elementwise(
input1=fc.get_output(0),
input2=bias_itensor,
op=trt.ElementWiseOperation.SUM
)
return fc
def build_engine(onnx_file_path, engine_file_path):
# 提取 ONNX 权重
weights_dict = extract_onnx_weights(onnx_file_path)
# 创建 TensorRT 构建器
TRT_LOGGER = trt.Logger(trt.Logger.WARNING)
builder = trt.Builder(TRT_LOGGER)
network = builder.create_network(1 << int(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH))
# 定义网络结构并填充权重
input_tensor = network.add_input("input", trt.DataType.FLOAT, (-1, 1, 28, 28))
# conv1 卷积层
conv1 = network.add_convolution_nd(input=input_tensor, num_output_maps=6, kernel_shape=(5, 5),
kernel=weights_dict['conv1.weight'], bias=weights_dict['conv1.bias'])
conv1.stride_nd = (1, 1)
relu1 = network.add_activation(input=conv1.get_output(0), type=trt.ActivationType.RELU)
# pool1 池化层
pool1 = network.add_pooling_nd(input=relu1.get_output(0), type=trt.PoolingType.MAX, window_size=(2, 2))
pool1.stride_nd = (2, 2)
# conv2 卷积层
conv2 = network.add_convolution_nd(input=pool1.get_output(0), num_output_maps=16, kernel_shape=(5, 5),
kernel=weights_dict['conv2.weight'], bias=weights_dict['conv2.bias'])
conv2.stride_nd = (1, 1)
relu2 = network.add_activation(input=conv2.get_output(0), type=trt.ActivationType.RELU)
# pool2 池化层
pool2 = network.add_pooling_nd(input=relu2.get_output(0), type=trt.PoolingType.MAX, window_size=(2, 2))
pool2.stride_nd = (2, 2)
# 展平池化输出
flatten = network.add_shuffle(pool2.get_output(0))
flatten.reshape_dims = (-1, np.prod(pool2.get_output(0).shape[1:]))
# fc1 全连接层
fc1 = create_fully_connected_layer(network, flatten.get_output(0), weights_dict, 'fc1')
relu3 = network.add_activation(input=fc1.get_output(0), type=trt.ActivationType.RELU)
# fc2 全连接层
fc2 = create_fully_connected_layer(network, relu3.get_output(0), weights_dict, 'fc2')
relu4 = network.add_activation(input=fc2.get_output(0), type=trt.ActivationType.RELU)
# fc3 全连接层(输出层)
fc3 = create_fully_connected_layer(network, relu4.get_output(0), weights_dict, 'fc3')
# 设置输出
fc3.get_output(0).name = "output"
network.mark_output(fc3.get_output(0))
# 创建配置对象
config = builder.create_builder_config()
# 设置工作空间大小
config.set_memory_pool_limit(trt.MemoryPoolType.WORKSPACE, 1 << 32) # 1 GB
# 启用 FP16 优化
if builder.platform_has_fast_fp16:
config.set_flag(trt.BuilderFlag.FP16)
# 创建优化配置文件(如果有动态输入)
profile = builder.create_optimization_profile()
input_tensor = network.get_input(0) # 获取输入张量
input_shape = input_tensor.shape
input_name = input_tensor.name
# 根据ONNX输入的shape调整profile的min/opt/max形状
min_shape = trt.Dims([1, input_shape[1], 28, 28])
opt_shape = trt.Dims([64, input_shape[1], 28, 28])
max_shape = trt.Dims([128, input_shape[1], 28, 28])
profile.set_shape(input_name, min_shape, opt_shape, max_shape)
config.add_optimization_profile(profile)
# 构建并序列化网络
engine = builder.build_serialized_network(network, config)
if engine is None:
print('Failed to build the engine')
return None
# 保存序列化的engine
with open(engine_file_path, 'wb') as f:
f.write(engine)
return engine
if __name__ == '__main__':
# 调用构建引擎的函数,将 ONNX 模型转换为 TensorRT 引擎
engine = build_engine('lenet5.onnx', 'lenet5.engine')
2.3 使用引擎文件推理
在生成了 TensorRT 引擎文件之后,可以通过加载该引擎并进行推理。推理过程主要包括分配输入输出缓冲区、将数据传递给 GPU 执行计算,以及将结果从设备内存复制回主机内存。以下代码具体展示了如何实现推理:
import numpy as np
import pycuda.driver as cuda
from tensorrt import TensorIOMode
__import__("pycuda.autoinit") # 用于自动初始化 CUDA 上下文
import tensorrt as trt
class HostDeviceMem(object):
def __init__(self, host_mem, device_mem):
self.host = host_mem # 主机内存对象
self.device = device_mem # 设备内存对象
def __str__(self):
return "Host:\n" + str(self.host) + "\nDevice:\n" + str(self.device)
def __repr__(self):
return self.__str__()
class TrtModel:
def __init__(self, engine_path, dtype=np.float32, input_name="input", output_name="output"):
self.input_name, self.output_name = input_name, output_name
self.engine_path = engine_path # TensorRT 引擎文件的路径
self.dtype = dtype # 数据类型(例如 np.float32)
self.logger = trt.Logger(trt.Logger.WARNING) # 创建 TensorRT 日志记录器,设置日志级别为警告
self.runtime = trt.Runtime(self.logger) # 创建 TensorRT 运行时对象
self.engine = self.load_engine() # 从文件加载 TensorRT 引擎
self.cur_batch_size = None # 当前批次
self.inputs, self.outputs, self.bindings, self.stream = None, None, None, None # 分配内存缓冲区
self.context = self.engine.create_execution_context() # 创建 TensorRT 执行上下文
def load_engine(self):
"""从文件中加载 TensorRT 引擎"""
with open(self.engine_path, 'rb') as f:
engine_data = f.read() # 读取引擎数据
engine = self.runtime.deserialize_cuda_engine(engine_data) # 反序列化引擎数据
return engine
def allocate_buffers(self, batch_size):
"""为输入和输出分配主机和设备内存"""
inputs = [] # 输入缓冲区列表
outputs = [] # 输出缓冲区列表
bindings = [] # 绑定的设备内存地址列表
stream = cuda.Stream() # 创建 CUDA 流
for binding in self.engine: # 遍历所有绑定(输入和输出)
# 计算缓冲区大小
size = trt.volume(self.engine.get_tensor_shape(binding)[1:]) * batch_size
host_mem = cuda.pagelocked_empty(size, self.dtype) # 创建主机内存(页锁定)
device_mem = cuda.mem_alloc(host_mem.nbytes) # 在设备上分配内存
bindings.append(int(device_mem)) # 将设备内存地址添加到绑定列表
if self.engine.get_tensor_mode(binding) == TensorIOMode.INPUT: # 判断是否为输入绑定
inputs.append(HostDeviceMem(host_mem, device_mem)) # 创建输入缓冲区, 并添加到输入缓冲区列表
else:
outputs.append(HostDeviceMem(host_mem, device_mem)) # 创建输出缓冲区, 并添加到输出缓冲区列表
self.cur_batch_size = batch_size
return inputs, outputs, bindings, stream # 返回分配的缓冲区列表和流
def __call__(self, x: np.ndarray):
"""执行推理"""
x = x.astype(self.dtype) # 将输入数据转换为指定的数据类型
if x.shape[0] != self.cur_batch_size:
# 重新分配内存缓冲区
self.inputs, self.outputs, self.bindings, self.stream, = self.allocate_buffers(x.shape[0])
# 动态设置神经网络的输入层形状
self.context.set_input_shape(self.input_name, x.shape)
np.copyto(self.inputs[0].host, x.ravel()) # 将输入数据拷贝到主机内存(展平为一维数组)
# 将数据从主机内存拷贝到设备内存
for inp in self.inputs:
cuda.memcpy_htod_async(inp.device, inp.host, self.stream)
# 执行推理
self.context.execute_async_v2(bindings=self.bindings, stream_handle=self.stream.handle)
# 将结果从设备内存拷贝回主机内存
for out in self.outputs:
cuda.memcpy_dtoh_async(out.host, out.device, self.stream)
self.stream.synchronize() # 同步 CUDA 流,确保所有操作完成
# 将输出数据重新形状为 TensorRT 引擎的绑定形状
return [out.host.reshape(self.engine.get_tensor_shape(self.output_name)) for out in self.outputs]
def __del__(self):
del self.context
del self.engine
del self.runtime
if __name__ == '__main__':
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision.datasets import MNIST
import tqdm
batch_size = 32 # 批处理大小需要与模型匹配
model = TrtModel("lenet5.engine") # 创建 TrtModel 实例
shape = model.engine.get_tensor_shape(model.input_name) # 获取输入张量的形状
transform = transforms.Compose([
transforms.Resize((shape[2], shape[3])), # 调整图像大小
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,)), # 正则化处理
])
test_dataset = MNIST('./data', train=False, download=True, transform=transform)
test_dataloader = DataLoader(test_dataset, batch_size=batch_size, shuffle=True)
test_total_acc = 0
for data, target in tqdm.tqdm(test_dataloader, desc='Testing', delay=0.01, total=len(test_dataloader)):
data, target = data.numpy(), target.numpy()
output = model(data)[0
prob = (output)
test_total_acc += (output.argmax(axis=1) == target).sum()
test_avg_acc = test_total_acc / len(test_dataloader.dataset)
print(f"Acc: {test_avg_acc}")
3 命令行构建推理
3.1 trtexec 工具介绍
trtexec 是一个简单且快速的工具,用于将 ONNX、UFF、Caffe、TensorFlow 等模型文件直接转化为 TensorRT 引擎文件,并用于后续的推理。
trtexec 工具主要适用于性能评估和测试,生成的是随机输入数据,不适合处理实际图像或真实数据。如果需要将模型部署到实际应用中,则需要编写自定义的推理脚本,加载真实数据并处理推理结果。
trtexec 命令的基本语法格式如下:
trtexec [options]
其中:
-
模型选项
查看详细选项
选项 说明 --uff=<file>指定要加载的 UFF 模型文件路径。 --onnx=<file>指定要加载的 ONNX 模型文件路径。 --model=<file>指定要加载的 Caffe 模型文件路径(默认为无模型,使用随机权重)。 --deploy=<file>指定要加载的 Caffe prototxt 文件路径。 --output=<name>[,<name>]*指定模型的输出节点名称(可以指定多个);UFF 和 Caffe 模型至少需要一个输出节点。 --uffInput=<name>,X,Y,Z指定 UFF 模型的输入 blob 名称及其维度(X,Y,Z=C,H,W),可以指定多个输入;UFF 模型至少需要一个输入。 --uffNHWC如果输入是 NHWC 布局而不是 NCHW,则设置此选项(在 --uffInput中使用 X,Y,Z=H,W,C 顺序)。 -
构建选项
查看详细选项
选项 说明 --maxBatch设置最大批量大小,并构建隐式批量引擎(默认为与 --batch相同的大小)。此选项不应与 ONNX 模型或动态形状一起使用。--minShapes=spec使用提供的最小形状构建具有动态形状的配置文件。 --optShapes=spec使用提供的最佳形状构建具有动态形状的配置文件。 --maxShapes=spec使用提供的最大形状构建具有动态形状的配置文件。 --minShapesCalib=spec使用提供的最小形状进行动态形状校准。 --optShapesCalib=spec使用提供的最佳形状进行动态形状校准。 --maxShapesCalib=spec使用提供的最大形状进行动态形状校准。 --inputIOFormats=spec每个输入张量的类型和格式(默认为 fp32:chw)。--outputIOFormats=spec每个输出张量的类型和格式(默认为 fp32:chw)。--workspace=N设置工作区大小,单位为 MiB。 --memPoolSize=poolspec指定指定内存池的大小约束,单位为 MiB。 --profilingVerbosity=mode指定性能剖析的详细程度,默认为 layer_names_only。--minTiming=M设置在内核选择中使用的最小迭代次数(默认为 1)。 --avgTiming=M设置每次迭代内核选择的平均次数(默认为 8)。 --refit将引擎标记为可重新调整的,这允许检查引擎内的可重新调整层和权重。 --versionCompatible, --vc将引擎标记为版本兼容,这允许引擎在同一主机操作系统上与 TensorRT 的新版本一起使用。 --useRuntime=runtime指定 TensorRT 引擎运行时, runtime可以是full、lean或dispatch。--leanDLLPath=<file>指定要在版本兼容模式下使用的外部精简运行时 DLL。 --excludeLeanRuntime当启用版本兼容模式时,不嵌入精简运行时。 --sparsity=spec控制稀疏性(默认为禁用)。 --noTF32禁用 TF32 精度(默认为启用)。 --fp16启用 FP16 精度(默认禁用)。 --int8启用 INT8 精度(默认禁用)。 --fp8启用 FP8 精度(默认禁用)。 --best启用所有精度以获得最佳性能(默认禁用)。 --directIO避免在网络边界处重新格式化(默认禁用)。 --precisionConstraints=spec控制精度约束设置(默认无)。 --layerPrecisions=spec控制每层的精度约束,仅在 precisionConstraints设置为obey或prefer时有效。--layerOutputTypes=spec控制每层的输出类型约束,仅在 precisionConstraints设置为obey或prefer时有效。--layerDeviceTypes=spec指定每层的设备类型,未指定设备类型的层将使用默认设备类型。 --calib=<file>读取 INT8 校准缓存文件。 --safe启用构建安全认证引擎,若启用 DLA,则自动指定 --buildDLAStandalone(默认禁用)。--buildDLAStandalone启用构建 DLA 独立可加载模块,启用此选项时,不允许使用 --allowGPUFallback,并且默认启用--skipInference。--allowGPUFallback启用 DLA 时,允许不支持的层回退到 GPU(默认禁用)。 --consistency对安全认证引擎执行一致性检查。 --restricted启用安全范围检查,并设置 kSAFETY_SCOPE构建标志。--saveEngine=<file>保存序列化引擎。 --loadEngine=<file>加载序列化引擎。 --tacticSources=tactics指定通过添加(+)或删除(-)策略来使用的策略源,默认使用所有可用策略。 --noBuilderCache禁用构建器中的时间缓存(默认为启用)。 --heuristic启用构建器中的策略选择启发式算法(默认为禁用)。 --timingCacheFile=<file>保存/加载序列化的全局时间缓存。 --preview=features通过添加(+)或删除(-)预览功能来指定要使用的预览功能。 --builderOptimizationLevel设置构建器优化级别(默认为 3)。较高的级别允许 TensorRT 花费更多的构建时间以获得更多优化选项。 --hardwareCompatibilityLevel=mode使引擎文件与其他 GPU 架构兼容, mode可以是none或ampere+(默认为none)。--tempdir=<dir>覆盖 TensorRT 创建临时文件时使用的默认临时目录。 --tempfileControls=controls控制 TensorRT 在创建临时可执行文件时允许的操作。 --maxAuxStreams=N设置每个推理流允许使用的最大辅助流数量,如果网络包含可以并行运行的操作,设置为 0 可优化内存使用(默认使用启发式)。 -
推理选项
查看详细选项
选项 说明 --batch=N设置隐式批量引擎的批次大小(默认值为 1)。构建引擎时,如果使用 ONNX 模型或提供动态形状,则不应使用此选项。 --shapes=spec为动态形状推理输入设置输入形状。输入名称可以用单引号包裹(例如:'Input:0')。形状规格示例: input0:1x3x256x256, input1:1x3x128x128。每个输入形状以键值对的形式提供,键为输入名称,值为该输入的维度(包括批次维度)。多个输入形状可以通过逗号分隔的键值对提供。--loadInputs=spec从文件中加载输入值(默认是生成随机输入)。输入名称可以用单引号包裹(例如:'Input:0')。输入值规格: Ival[","spec],其中Ival格式为name":"file。--iterations=N运行至少 N 次推理迭代(默认值为 10)。 --warmUp=N在测量性能之前,预热运行 N 毫秒(默认值为 200)。 --duration=N设置性能测量至少运行的秒数(默认值为 3)。如果设置为 -1,推理将持续运行,直到手动停止。 --sleepTime=N在推理启动前延迟 N 毫秒(默认值为 0)。 --idleTime=N在两次连续迭代之间休眠 N 毫秒(默认值为 0)。 --infStreams=N实例化 N 个引擎以并发运行推理(默认值为 1)。 --exposeDMA序列化设备与主机之间的 DMA 传输(默认禁用)。 --noDataTransfers禁用设备与主机之间的 DMA 传输(默认启用)。 --useManagedMemory使用托管内存而不是分别的主机和设备分配(默认禁用)。 --useSpinWait在 GPU 事件上主动同步。此选项可能减少同步时间,但会增加 CPU 使用率和功耗(默认禁用)。 --threads启用多线程以独立线程驱动引擎或加速重新配置(默认禁用)。 --useCudaGraph使用 CUDA 图捕获引擎执行,然后启动推理(默认禁用)。此标志可能在图捕获失败时被忽略。 --timeDeserialize计时反序列化网络所需的时间并退出。 --timeRefit计时重新配置引擎前所需的时间。 --separateProfileRun在基准测试运行中不附加分析器;如果启用了分析,将执行第二次分析运行(默认禁用)。 --skipInference在构建引擎后退出并跳过推理性能测量(默认禁用)。 --persistentCacheRatio设置持久缓存限制的比例,0.5 表示最大持久 L2 大小的一半(默认值为 0)。 -
构建和推理批处理选项
查看详细选项
选项 说明 隐式批处理在隐式批处理模式下,如果未指定最大批次大小,那么在推理时使用的批次大小将自动设定为引擎的最大批次大小。 显式批处理如果使用显式批处理,且仅为推理指定了形状,这些形状也将被用于构建配置文件中的最小(min)、最优(opt)和最大(max)形状。如果仅为构建指定了形状,则最优形状也将用于推理。如果同时为构建和推理指定了形状,这些形状必须兼容。 ONNX模型使用 ONNX 模型时,会自动启用显式批处理。 -
报告选项
查看详细选项
选项 说明 --verbose使用详细日志记录(默认 = false) --avgRuns=N报告 N 次连续迭代的平均性能测量结果(默认 = 10) --percentile=P1,P2,P3,...报告 P1、P2、P3... 百分位数的性能(0 ≤ P_i ≤ 100,0 代表最大性能,100 代表最小性能;默认 = 90,95,99%) --dumpRefit打印可重新调整的引擎层和权重 --dumpOutput打印最后一次推理迭代的输出张量(默认 = 禁用) --dumpRawBindingsToFile将最后一次推理迭代的输入/输出张量打印到文件(默认 = 禁用) --dumpProfile打印每层的性能概况信息(默认 = 禁用) --dumpLayerInfo将引擎的层信息打印到控制台(默认 = 禁用) --exportTimes=<file>将时间结果写入 JSON 文件(默认 = 禁用) --exportOutput=<file>将输出张量写入 JSON 文件(默认 = 禁用) --exportProfile=<file>将每层的性能概况信息写入 JSON 文件(默认 = 禁用) --exportLayerInfo=<file>将引擎的层信息写入 JSON 文件(默认 = 禁用) -
系统选项
查看详细选项
参数选项 说明 --device=N选择 CUDA 设备 N(默认 = 0) --useDLACore=N选择支持 DLA 的层使用 DLA 核心 N(默认 = 无) --staticPlugins静态加载的插件库 (.so)(可以多次指定) --dynamicPlugins动态加载的插件库 (.so),如果包含在 --setPluginsToSerialize中,可以与引擎一起序列化(可以多次指定)--setPluginsToSerialize与引擎一起序列化的插件库 (.so)(可以多次指定) --ignoreParsedPluginLibs默认情况下,在构建版本兼容的引擎时,由 ONNX 解析器指定的插件库会被隐式序列化并动态加载(除非指定了 --excludeLeanRuntime)。启用此标志以忽略这些插件库。 -
帮助
查看详细选项
参数选项 说明 --help, -h打印此消息
3.2 构建引擎文件
使用 trtexec 将 ONNX 模型转换为 TensorRT 引擎,以下是基本用法:
trtexec --onnx=/path/to/your_model.onnx --saveEngine=/path/to/your_model.engine
常用选项:
--onnx: 指定输入的 ONNX 模型文件路径。--saveEngine: 指定要保存的 TensorRT 引擎文件路径。--explicitBatch: 开启显式批处理模式,推荐使用此选项来处理动态批次大小。--minShapes,--optShapes,--maxShapes: 用于设置动态输入的最小、优化和最大形状。此选项在处理动态输入时非常重要。- 示例:
--minShapes=input:1x3x224x224 --optShapes=input:4x3x224x224 --maxShapes=input:8x3x224x224
- 示例:
--workspace: 设置 GPU 的内存工作空间大小,单位为 MB。默认值通常为 16。- 示例:
--workspace=2048
- 示例:
--fp16: 启用 FP16 精度加速,前提是你的 GPU 支持 FP16。--int8: 启用 INT8 精度加速,前提是有校准表或量化感知训练的支持。--calib: 指定 INT8 校准表的路径。--verbose: 启用详细日志输出,便于调试。
例如,你想要将 lenet5.onnx 模型转换为 TensorRT 引擎文件 lenet5.engine,并启用 FP16 精度和显式批处理模式,设置了动态输入的最小、优化和最大形状为 1x1x28x28、64x1x28x28 和 128x1x28x28,并分配了 1024 MB 的 GPU 内存用于构建引擎,具体命令如下:
trtexec --onnx=lenet5.onnx --saveEngine=lenet5.engine --fp16 --explicitBatch --minShapes=input:1x1x28x28 --optShapes=input:64x1x28x28 --maxShapes=input:128x1x28x28 --workspace=1024
3.3 使用引擎文件推理
使用 trtexec 工具加载并推理已构建的 TensorRT 引擎文件。以下是基本用法:
trtexec --loadEngine=/path/to/your_model.engine
常用选项:
--loadEngine: 指定要加载的 TensorRT 引擎文件路径。--batch: 设置推理的批处理大小,适用于显式批处理模式的引擎。--iterations: 设置推理的迭代次数。--duration: 指定推理的持续时间(以秒为单位)。--useCudaGraph: 启用 CUDA 图形加速推理过程。--streams: 设置并发执行的 CUDA 流数。--verbose: 启用详细日志输出,便于调试。
例如,你想加载并推理 lenet5.engine 文件,设定批处理大小为 8,并执行 10 次推理迭代,具体命令如下:
trtexec --loadEngine=lenet5.engine --batch=8 --iterations=10 --useCudaGraph
4 C++ 构建推理
4.1 C++ 环境搭建
# 设置 CMake 的最低版本要求为 3.28 以上
cmake_minimum_required(VERSION 3.28)
# 定义项目名称为 ctrt,并使用 CUDA 和 C++ 语言
project(ctrt CUDA CXX)
# 设置 C++ 标准为 C++17
set(CMAKE_CXX_STANDARD 17)
# 指定 CUDA 工具包的根目录路径
set(CUDA_TOOLKIT_ROOT_DIR "C:/Program Files/NVIDIA GPU Computing Toolkit/CUDA/v11.8")
# 将 CUDA 头文件目录添加到编译器的包含路径中
include_directories("${CUDA_TOOLKIT_ROOT_DIR}/include")
# 将 CUDA 库目录添加到链接器的搜索路径中
link_directories("${CUDA_TOOLKIT_ROOT_DIR}/lib/x64")
# 指定 TensorRT 的根目录路径
set(TENSORRT_ROOT "C:/Program Files/NVIDIA GPU Computing Toolkit/CUDA/v11.8/TensorRT-8.6.1.6")
# 将 TensorRT 头文件目录添加到编译器的包含路径中
include_directories("${TENSORRT_ROOT}/include")
# 将 TensorRT 库目录添加到链接器的搜索路径中
link_directories("${TENSORRT_ROOT}/lib")
# 定义项目的源文件
set(SOURCES build.cpp)
# 创建一个名为 ctrt 的可执行文件,并指定要编译的源文件
add_executable(ctrt ${SOURCES})
# 链接库文件到可执行文件 ctrt 中,确保链接 TensorRT 和 CUDA 库
target_link_libraries(ctrt
nvinfer # TensorRT 主库,用于执行神经网络推理
cudart # CUDA 运行时库,提供 CUDA 相关功能的支持
nvonnxparser # TensorRT 的 ONNX 解析器库,用于解析 ONNX 格式的模型
)
4.2 构建引擎文件
4.2.1 使用 Parser 构建
/*
* TensorRT 构建 engine 的过程:
* 1. 创建 builder
* 2. 创建网络定义 network
* 3. 创建配置参数 config
* 4. 生成 engine
* 5. 序列化保存 engine 文件
* 6. 释放资源
* */
#include <iostream>
#include <fstream>
#include <NvInfer.h>
#include <nvonnxparser.h>
// 定义一个自定义的日志记录器类 TRTLogger,继承自 TensorRT 的 ILogger 接口
class TRTLogger : public nvinfer1::ILogger {
void log(Severity severity, const char *msg) noexcept override {
// 屏蔽掉 INFO 等级的日志消息
if (severity != Severity::kINFO) {
std::cout << msg << std::endl;
}
}
};
int main() {
char *onnxModelPath = "lenet5.onnx";
char *engineOutputPath = "lenet5.engine";
bool isDynamic = true;
TRTLogger logger;
// 创建 builder
nvinfer1::IBuilder *builder = nvinfer1::createInferBuilder(logger);
// 创建网络定义
nvinfer1::INetworkDefinition *network = builder->createNetworkV2(
// 1 左移 0 位,代表显式批次模式
1U << static_cast<uint32_t>(nvinfer1::NetworkDefinitionCreationFlag::kEXPLICIT_BATCH)
);
// 使用 ONNX Parser 构建网络模型
nvonnxparser::IParser *parser = nvonnxparser::createParser(*network, logger);
if (!parser) {
std::cerr << "Failed to create TensorRT parser." << std::endl;
return -1;
}
// 调用 parseFromFile 方法并校验返回值
bool success = parser->parseFromFile(onnxModelPath, static_cast<int>(nvinfer1::ILogger::Severity::kWARNING));
// 校验解析是否成功
if (!success) {
std::cerr << "Failed to parse the ONNX model: " << onnxModelPath << std::endl;
// 获取并打印所有解析错误消息
for (int i = 0; i < parser->getNbErrors(); ++i) {
auto *error = parser->getError(i);
std::cerr << "Error [" << i << "] ";
std::cerr << "Severity: " << static_cast<int>(error->code()) << " ";
std::cerr << "Message: " << error->desc() << std::endl;
}
// 清理解析器
parser->destroy();
return -1; // 返回 false 表示解析失败
}
std::cout << "Successfully parsed the ONNX model: " << onnxModelPath << std::endl;
// 创建配置参数
nvinfer1::IBuilderConfig *config = builder->createBuilderConfig();
// 设置最大工作空间大小(例如 1GB)
config->setMaxWorkspaceSize(1 << 30); // 1 GiB
// 设置 FP16 模式(如果支持)
if (builder->platformHasFastFp16()) {
config->setFlag(nvinfer1::BuilderFlag::kFP16);
}
// 创建优化配置文件(用于动态输入)
if (isDynamic) {
nvinfer1::IOptimizationProfile *profile = builder->createOptimizationProfile();
if (!profile) {
std::cerr << "Failed to create optimization profile." << std::endl;
return -1;
}
// 获取输入张量
nvinfer1::ITensor *input_tensor = network->getInput(0);
nvinfer1::Dims input_shape = input_tensor->getDimensions();
const char *input_name = input_tensor->getName();
// 根据 ONNX 输入的形状调整 profile 的 min/opt/max 形状
nvinfer1::Dims min_shape{4, {1, input_shape.d[1], 28, 28}};
nvinfer1::Dims opt_shape{4, {64, input_shape.d[1], 28, 28}};
nvinfer1::Dims max_shape{4, {128, input_shape.d[1], 28, 28}};
profile->setDimensions(input_name, nvinfer1::OptProfileSelector::kMIN, min_shape);
profile->setDimensions(input_name, nvinfer1::OptProfileSelector::kOPT, opt_shape);
profile->setDimensions(input_name, nvinfer1::OptProfileSelector::kMAX, max_shape);
// 添加优化配置文件到配置中
config->addOptimizationProfile(profile);
}
// 生成引擎
nvinfer1::ICudaEngine *engine = builder->buildEngineWithConfig(*network, *config);
if (!engine) {
std::cerr << "Failed to build the TensorRT engine." << std::endl;
return -1;
}
// 序列化并保存 engine 文件
nvinfer1::IHostMemory *serializedModel = engine->serialize();
if (!serializedModel) {
std::cerr << "Failed to serialize the TensorRT engine." << std::endl;
return -1;
}
std::ofstream engineFile(engineOutputPath, std::ios::binary);
if (!engineFile) {
std::cerr << "Failed to open file for writing the TensorRT engine." << std::endl;
return -1;
}
engineFile.write(reinterpret_cast<const char *>(serializedModel->data()), serializedModel->size());
engineFile.close();
// 释放资源(先打开的后释放)
serializedModel->destroy();
engine->destroy();
config->destroy();
network->destroy();
parser->destroy();
builder->destroy();
std::cout << "TensorRT engine built and saved successfully." << std::endl;
return 0;
}
4.2.2 使用 C++ API 构建
/*
* TensorRT 构建 engine 的过程:
* 1. 创建 builder
* 2. 创建网络定义 network
* 3. 创建配置参数 config
* 4. 生成 engine
* 5. 序列化保存 engine 文件
* 6. 释放资源
* */
#include <iostream>
#include <fstream>
#include <NvInfer.h>
#include <nvonnxparser.h>
// 定义一个自定义的日志记录器类 TRTLogger,继承自 TensorRT 的 ILogger 接口
class TRTLogger : public nvinfer1::ILogger {
void log(Severity severity, const char *msg) noexcept override {
// 屏蔽掉 INFO 等级的日志消息
if (severity != Severity::kINFO) {
std::cout << msg << std::endl;
}
}
};
int main() {
char *engineOutputPath = "fc.engine";
TRTLogger logger;
// 创建 builder
nvinfer1::IBuilder *builder = nvinfer1::createInferBuilder(logger);
// 创建网络定义
nvinfer1::INetworkDefinition *network = builder->createNetworkV2(
// 1 左移 0 位,代表显式批次模式
1U << static_cast<uint32_t>(nvinfer1::NetworkDefinitionCreationFlag::kEXPLICIT_BATCH)
);
//网络定义:input -->fc1 -->sigmodi -->output
//创建一个input tensor,参数分别为:名称,数据类型,维度
const int input_size = 3;
nvinfer1::ITensor* input = network->addInput("input",nvinfer1::DataType::kFLOAT,nvinfer1::Dims4{1,input_size,1,1});
//创建一个全连接层fc1
//权重和偏置
const float* fc1_weight_data = new float[6]{0.1,0.2,0.3,0.4,0.5,0.6};
const float* fc1_bias_data = new float [2]{0.1,0.5};
const int output_size = 2;
//转为nvinfer1::Weights类型,参数分别为:数据类型,数据指针,数据大小
nvinfer1::Weights fc1_weights{nvinfer1::DataType::kFLOAT,fc1_weight_data,6};
nvinfer1::Weights fc1_bias{nvinfer1::DataType::kFLOAT,fc1_bias_data,2};
//创建全连接层,参数分别为:输入,输出大小,权重,偏置
nvinfer1::IFullyConnectedLayer* fc1 = network->addFullyConnected(*input,output_size,fc1_weights,fc1_bias);
//添加激活函数层,参数为:输入,激活函数类型
nvinfer1::IActivationLayer* sigmoid = network->addActivation(*fc1->getOutput(0),nvinfer1::ActivationType::kSIGMOID);
//设置输出的名字
sigmoid->getOutput(0)->setName("output");
//标记输出(声明当前的值为输出,防止被优化掉)
network->markOutput(*sigmoid->getOutput(0));
// 创建配置参数
nvinfer1::IBuilderConfig *config = builder->createBuilderConfig();
// 设置最大工作空间大小(例如 1GB)
config->setMaxWorkspaceSize(1 << 30); // 1 GiB
// 设置 FP16 模式(如果支持)
if (builder->platformHasFastFp16()) {
config->setFlag(nvinfer1::BuilderFlag::kFP16);
}
// 生成引擎
nvinfer1::ICudaEngine *engine = builder->buildEngineWithConfig(*network, *config);
if (!engine) {
std::cerr << "Failed to build the TensorRT engine." << std::endl;
return -1;
}
// 序列化并保存 engine 文件
nvinfer1::IHostMemory *serializedModel = engine->serialize();
if (!serializedModel) {
std::cerr << "Failed to serialize the TensorRT engine." << std::endl;
return -1;
}
std::ofstream engineFile(engineOutputPath, std::ios::binary);
if (!engineFile) {
std::cerr << "Failed to open file for writing the TensorRT engine." << std::endl;
return -1;
}
engineFile.write(reinterpret_cast<const char *>(serializedModel->data()), serializedModel->size());
engineFile.close();
// 释放资源(先打开的后释放)
serializedModel->destroy();
engine->destroy();
config->destroy();
network->destroy();
builder->destroy();
std::cout << "TensorRT engine built and saved successfully." << std::endl;
return 0;
}
4.3 使用引擎文件推理
/*
* TensorRt runtime 推理过程
*
* 1.创建一个runtime对象
* 2.反序列化生成的engine文件(加载):runtime-->engine
* 3.创建一个执行上下文的对象ExcutionContext:engine-->context
* 4.填充数据
* 5.执行推理:context-->enqueueV2
* 6.释放资源
* */
#include <iostream>
#include <vector>
#include <fstream>
#include <cassert>
#include <NvInfer.h>
#include <cuda_runtime.h>
//logger 用于管控打印的日志级别
//TRTLogger 继承nvinfer1::ILogger
class TRTLogger : public nvinfer1::ILogger {
void log(Severity severity, const char *msg) noexcept override {
//info,warring,error
//屏蔽掉info级别的日志
if (severity != Severity::kINFO) {
std::cout << msg << std::endl;
}
}
};
//加载engine模型
std::vector<unsigned char> loadEngineModel(const std::string &filename) {
//读文件
std::ifstream file(filename, std::ios::binary);
assert(file.is_open() && "load engine model failed");
//定位到文件的末尾
file.seekg(0, std::ios::end);
//获取文件大小
size_t size = file.tellg();
//创建一个vector,大小为engine文件的大小
std::vector<unsigned char> data(size);
//定位到engine文件开头
file.seekg(0, std::ios::beg);
//读取engine文件内容到data里面
file.read((char *) data.data(), size);
file.close();
return data;
}
int main() {
//1.创建runtime对象
TRTLogger logger;
nvinfer1::IRuntime *runtime = nvinfer1::createInferRuntime(logger);
//2.反序列化生成的engine文件(加载engine文件)
auto engineModel = loadEngineModel("fc.engine");
//调用runtime的反序列化方法,反序列化生成的engine
nvinfer1::ICudaEngine *engine = runtime->deserializeCudaEngine(engineModel.data(), engineModel.size(), nullptr);
if (!engine) {
std::cout << "deserialize Engine failed!" << std::endl;
return -1;
}
//3. 创建一个执行上下文的对象ExecutionContext: engine-->context
nvinfer1::IExecutionContext *context = engine->createExecutionContext();
//4.填充数据
//设置stream流
cudaStream_t stream = nullptr;
cudaStreamCreate(&stream);
//数据流转: host-->device-->inference-->host
//输入数据
float *host_input_data = new float[3]{2, 4, 8};
int input_data_size = 3 * sizeof(float);
float *device_input_data = nullptr;
//输出数据
float *host_output_data = new float[2]{0, 0};
int output_data_size = 2 * sizeof(float);
float *device_output_data = nullptr;
//申请device内存
//申请input在device上的内存
cudaMalloc((void **) &device_input_data, input_data_size);
//申请output在device上的内存
cudaMalloc((void **) &device_output_data, output_data_size);
//host-->device 参数: 目标地址,源地址,数据大小,拷贝方向,stream流
cudaMemcpyAsync(device_input_data, host_input_data, input_data_size, cudaMemcpyHostToDevice, stream);
//bindings 告诉上下文context输入输出的数据位置
float *bindings[] = {device_input_data, device_output_data};
//5. 执行推理: context-->enqueueV2
bool success = context->enqueueV2((void **) bindings, stream, nullptr);
//输出结果
std::cout << "推理是否成功:" << success << std::endl;
//数据从device-->host
cudaMemcpyAsync(host_output_data, device_output_data, output_data_size, cudaMemcpyDeviceToHost, stream);
//等待流执行完毕
cudaStreamSynchronize(stream);
//输出结果
std::cout << "输出结果" << host_output_data[0] << "," << host_output_data[1] << std::endl;
//6. 释放资源
cudaStreamDestroy(stream);
cudaFree(device_output_data);
cudaFree(device_input_data);
delete host_output_data;
delete host_input_data;
delete context;
delete engine;
delete runtime;
}
/**
* 将 runtime.cpp 的后缀更改为 .cu,可以使 NVCC 编译器处理 CUDA 代码。NVCC 是 NVIDIA 专门为 CUDA 开发的编译器,
* 它比 MSVC(Microsoft Visual C++ 编译器)在处理 CUDA 代码时更高效,编译速度通常也更快。
* 注意:修改文件后缀的时候,也要修改 CMakeLists.txt 中的文件名
*/
4.4 YOLO V5 目标检测案例
整个项目的目录结构如下所示:
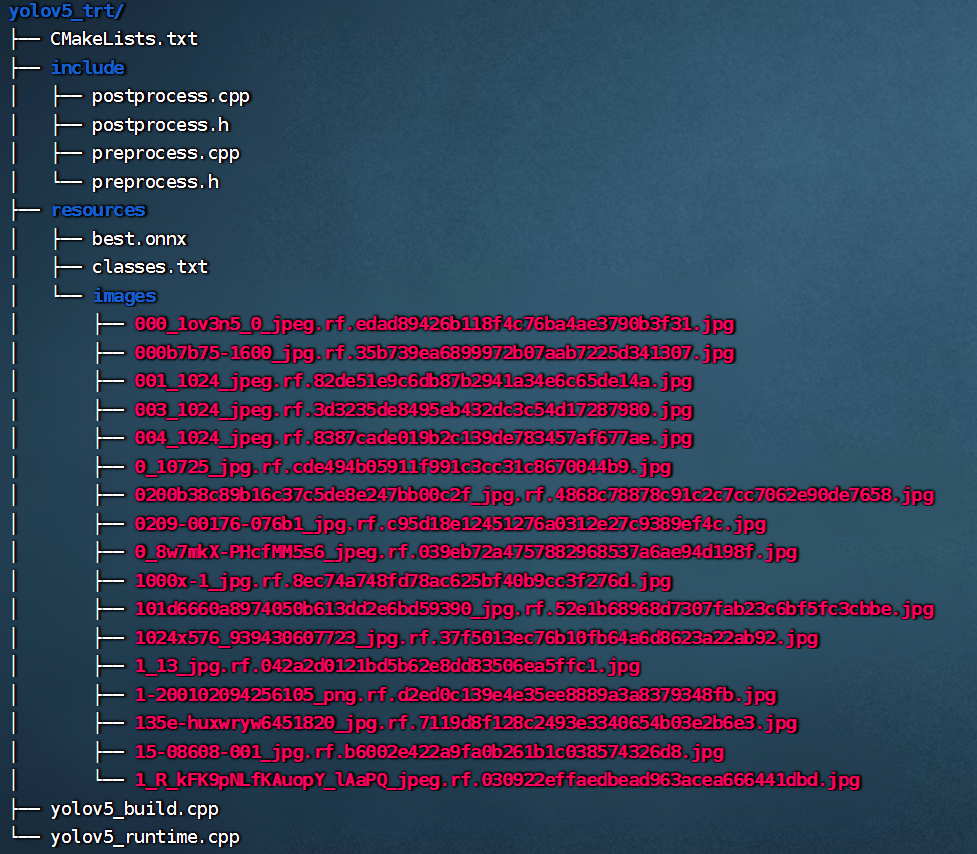
需要注意的是,在构建阶段需要在 CMakeLists.txt 中将 yolov5_build.cpp 包含在项目源文件中;而推理阶段则要将 yolov5_runtime.cpp 包含在项目源文件中。
4.4.1 CMakeLists.txt
# 指定项目名称
set(PROJECT_NAME yolov5_trt)
# 指定 CUDA 工具包的根目录路径
set(CUDA_TOOLKIT_ROOT "C:/Program Files/NVIDIA GPU Computing Toolkit/CUDA/v11.8")
# 指定 TensorRT 的根目录路径
set(TENSORRT_ROOT "C:/Program Files/NVIDIA GPU Computing Toolkit/CUDA/v11.8/TensorRT-8.6.1.6")
# 指定 OpenCV 的根目录路径
set(OpenCV_ROOT "F:/Develop/opencv/opencv")
# 指定包含文件的目录路径
set(INCLUDE_DIR "include")
# 设置资源文件的源目录
set(RESOURCE_DIR "${CMAKE_SOURCE_DIR}/resources")
# 设置资源文件的目标目录
set(RESOURCE_OUTPUT_DIR "${CMAKE_BINARY_DIR}")
# 将资源文件复制到可执行文件所在目录
file(COPY ${RESOURCE_DIR} DESTINATION ${RESOURCE_OUTPUT_DIR})
# 设置 CMake 的最低版本要求为 3.28 以上
cmake_minimum_required(VERSION 3.28)
# 定义项目名称为 ctrt,并使用 CUDA 和 C++ 语言
project(${PROJECT_NAME} CUDA CXX)
# 设置 C++ 标准为 C++17
set(CMAKE_CXX_STANDARD 17)
set(CMAKE_CXX_STANDARD_REQUIRED ON)
# 将 CUDA 头文件目录添加到编译器的包含路径中
include_directories("${CUDA_TOOLKIT_ROOT}/include")
# 将 CUDA 库目录添加到链接器的搜索路径中
link_directories("${CUDA_TOOLKIT_ROOT}/lib/x64")
# 将 TensorRT 头文件目录添加到编译器的包含路径中
include_directories("${TENSORRT_ROOT}/include")
# 将 TensorRT 库目录添加到链接器的搜索路径中
link_directories("${TENSORRT_ROOT}/lib")
# 指定 OpenCV 的安装路径以找到 OpenCV 配置文件
set(OpenCV_DIR "${OpenCV_ROOT}/build/x64/vc16/lib")
# 查找 OpenCV 库,并设置相关的包含路径和库路径
find_package(OpenCV REQUIRED)
# 定义项目头文件
file(GLOB HEADERS "${INCLUDE_DIR}/*.h")
# 定义项目的源文件(指定源文件或全部源文件)
#set(SOURCES yolov5_runtime.cpp "${INCLUDE_DIR}/*.cpp")
file(GLOB SOURCES "${INCLUDE_DIR}/*.cpp" yolov5_runtime.cpp)
# 创建一个名为 ctrt 的可执行文件,并指定要编译的源文件和头文件
add_executable(${PROJECT_NAME} ${SOURCES} ${HEADERS})
# 链接库文件到可执行文件 ctrt 中,确保链接 TensorRT 和 CUDA 库
target_link_libraries(${PROJECT_NAME}
nvinfer # TensorRT 主库,用于执行神经网络推理
cudart # CUDA 运行时库,提供 CUDA 相关功能的支持
nvonnxparser # TensorRT 的 ONNX 解析器库,用于解析 ONNX 格式的模型
${OpenCV_LIBS}
)
# 如果使用的是 MSVC 编译器,则复制 OpenCV 的 DLL 文件到可执行文件的输出目录
if (MSVC)
# 查找 OpenCV 的 DLL 文件
file(GLOB OPENCV_DLLS "${OpenCV_ROOT}/build/x64/vc16/bin/*.dll")
# 设置在构建完成后,将 OpenCV 的 DLL 文件复制到可执行文件的输出目录
add_custom_command(TARGET ${PROJECT_NAME}
POST_BUILD
COMMAND ${CMAKE_COMMAND} -E copy_if_different
${OPENCV_DLLS}
$<TARGET_FILE_DIR:${PROJECT_NAME}>)
endif (MSVC)
4.4.2 yolov5_build.cpp
#include <iostream>
#include <fstream>
#include <NvInfer.h>
#include <nvonnxparser.h>
using namespace nvinfer1;
// ONNX 模型和 TensorRT engine 文件的路径
std::string onnx_model_path = "resources/best.onnx";
std::string trt_model_path = "resources/yolov5.engine";
// 是否使用 fp16 量化
bool is_fp16 = true;
// 是否使用动态输入
bool is_Dynamic = true;
// 使用动态输入时允许的最小、最优和最大输入尺寸
Dims min_shape{4, {1, 3, 320, 320}};
Dims opt_shape{4, {64, 3, 640, 640}};
Dims max_shape{4, {128, 3, 640, 640}};
// 定义一个自定义的日志记录器类 TRTLogger,继承自 TensorRT 的 ILogger 接口
class TRTLogger : public ILogger {
void log(Severity severity, const char *msg) noexcept override {
// 屏蔽掉 INFO 等级的日志消息
if (severity != Severity::kINFO) {
std::cout << msg << std::endl;
}
}
};
// 释放资源的函数
void cleanup(IHostMemory *serializedModel, ICudaEngine *engine, IBuilderConfig *config, nvonnxparser::IParser *parser,
INetworkDefinition *network, IBuilder *builder) {
if (serializedModel) serializedModel->destroy();
if (engine) engine->destroy();
if (config) config->destroy();
if (parser) parser->destroy();
if (network) network->destroy();
if (builder) builder->destroy();
}
int main() {
// 1. 创建 builder
TRTLogger logger;
IBuilder *builder = createInferBuilder(logger);
if (!builder) {
std::cerr << "Failed to create TensorRT builder." << std::endl;
return -1;
}
// 2. 创建网络定义
INetworkDefinition *network = builder->createNetworkV2(
1U << static_cast<uint32_t>(NetworkDefinitionCreationFlag::kEXPLICIT_BATCH)
);
if (!network) {
std::cerr << "Failed to create TensorRT network definition." << std::endl;
cleanup(nullptr, nullptr, nullptr, nullptr, network, builder);
return -1;
}
// 使用 ONNX Parser 构建网络模型
nvonnxparser::IParser *parser = nvonnxparser::createParser(*network, logger);
if (!parser) {
std::cerr << "Failed to create TensorRT parser." << std::endl;
cleanup(nullptr, nullptr, nullptr, parser, network, builder);
return -1;
}
// 解析 ONNX 模型文件
bool success = parser->parseFromFile(onnx_model_path.c_str(), static_cast<int>(ILogger::Severity::kWARNING));
if (!success) {
std::cerr << "Failed to parse the ONNX model: " << onnx_model_path << std::endl;
for (int i = 0; i < parser->getNbErrors(); ++i) {
auto *error = parser->getError(i);
std::cerr << "Error [" << i << "] "
<< "Severity: " << static_cast<int>(error->code()) << " "
<< "Message: " << error->desc() << std::endl;
}
cleanup(nullptr, nullptr, nullptr, parser, network, builder);
return -1;
}
std::cout << "Successfully parsed the ONNX model: " << onnx_model_path << std::endl;
// 3. 创建配置参数
IBuilderConfig *config = builder->createBuilderConfig();
if (!config) {
std::cerr << "Failed to create TensorRT builder configuration." << std::endl;
cleanup(nullptr, nullptr, nullptr, parser, network, builder);
return -1;
}
// 设置最大工作空间大小为 1 GB
config->setMaxWorkspaceSize(1 << 30);
// 设置启用 fp16 量化模式
if (is_fp16 && builder->platformHasFastFp16()) {
config->setFlag(BuilderFlag::kFP16);
}
// 创建优化配置文件(用于动态输入)
if (is_Dynamic) {
IOptimizationProfile *profile = builder->createOptimizationProfile();
if (!profile) {
std::cerr << "Failed to create optimization profile." << std::endl;
cleanup(nullptr, nullptr, config, parser, network, builder);
return -1;
}
ITensor *input_tensor = network->getInput(0);
const char *input_name = input_tensor->getName();
profile->setDimensions(input_name, OptProfileSelector::kMIN, min_shape);
profile->setDimensions(input_name, OptProfileSelector::kOPT, opt_shape);
profile->setDimensions(input_name, OptProfileSelector::kMAX, max_shape);
config->addOptimizationProfile(profile);
}
// 5. 生成引擎
ICudaEngine *engine = builder->buildEngineWithConfig(*network, *config);
if (!engine) {
std::cerr << "Failed to build the TensorRT engine." << std::endl;
cleanup(nullptr, nullptr, config, parser, network, builder);
return -1;
}
// 6. 序列化并保存 engine 文件
IHostMemory *serializedModel = engine->serialize();
if (!serializedModel) {
std::cerr << "Failed to serialize the TensorRT engine." << std::endl;
cleanup(nullptr, engine, config, parser, network, builder);
return -1;
}
std::ofstream engineFile(trt_model_path, std::ios::binary);
if (!engineFile) {
std::cerr << "Failed to open file for writing the TensorRT engine." << std::endl;
cleanup(serializedModel, engine, config, parser, network, builder);
return -1;
}
engineFile.write(reinterpret_cast<const char *>(serializedModel->data()), serializedModel->size());
engineFile.close();
// 释放资源
cleanup(serializedModel, engine, config, parser, network, builder);
std::cout << "TensorRT engine built and saved successfully." << std::endl;
return 0;
}
4.4.3 yolov5_runtime.cpp
/*
* TensorRt runtime 推理过程
*
* 1. 加载 TensorRT 引擎
* 2. 创建 TensorRT 运行时 (Runtime)
* 3. 反序列化引擎
* 4. 创建执行上下文
* 5. 申请资源
* 6. 准备输入数据(预处理)
* 7. 将输入数据拷贝到 GPU
* 8. 执行推理
* 9. 获取输出结果到 Host
* 10. 执行后处理逻辑
* 11. 释放资源
* */
#include <iostream>
#include <vector>
#include <fstream>
#include <cassert>
#include <NvInfer.h>
#include <cuda_runtime.h>
#include <opencv2/opencv.hpp>
#include "include/postprocess.h"
#include "include/preprocess.h"
#include <filesystem>
using namespace nvinfer1;
// TensorRT engine 文件的路径
std::string engine_file = "resources/yolov5.engine";
// 检测源路径,可以是图像、视频、摄像头(0)、图像目录
// std::string input_source = "sources/images/0_8w7mkX-PHcfMM5s6_jpeg.rf.039eb72a4757882968537a6ae94d198f.jpg";
std::string input_source = "0";
// std::string input_source = "sources/images";
bool is_Dynamic = true;
// 预处理设置
cv::Scalar mean_ = cv::Scalar(0, 0, 0); // 均值
cv::Scalar std_ = cv::Scalar(1, 1, 1); // 标准差
// 模型输入输出信息
int batch_size = 8;
int num_channels = 3; // yolov5只支持3通道
cv::Size input_size(640, 640);
int num_anchors = 25200;
std::string classes_path = "models/classes.txt";
// 后处理设置
float conf_threshold = 0.25f;
float nms_threshold = 0.45f;
// 定义一个自定义的日志记录器类 TRTLogger,继承自 TensorRT 的 ILogger 接口
class TRTLogger : public ILogger {
void log(Severity severity, const char *msg) noexcept override {
// 屏蔽掉 INFO 等级的日志消息
if (severity != Severity::kINFO) {
std::cout << msg << std::endl;
}
}
};
// 判断文件扩展名
std::string getFileExtension(const std::string &filename) {
size_t pos = filename.find_last_of(".");
if (pos != std::string::npos) {
return filename.substr(pos + 1);
}
return "";
}
// 加载类别名
std::vector<std::string> load_classes(const std::string &classes_path) {
std::vector<std::string> class_names;
std::ifstream file(classes_path);
if (!file.is_open()) {
std::cerr << "Failed to open classes file: " << classes_path << std::endl;
return class_names;
}
std::string line;
while (std::getline(file, line)) {
if (!line.empty()) {
class_names.push_back(line);
}
}
file.close();
return class_names;
}
// 释放推理资源的函数
void cleanup(cudaStream_t stream, void **buffers, float *input_data, float *output_data,
IExecutionContext *context, ICudaEngine *engine, IRuntime *runtime) {
if (stream) cudaStreamDestroy(stream);
if (buffers) {
// 默认只有一个输入和一个输出
if (buffers[0]) cudaFree(buffers[0]);
if (buffers[1]) cudaFree(buffers[1]);
delete[] buffers;
}
if (input_data) delete[] input_data;
if (output_data) delete[] output_data;
if (context) context->destroy();
if (engine) engine->destroy();
if (runtime) runtime->destroy();
}
std::vector<std::string> getImageFilesInDirectory(const std::string &directory_path,
const std::vector<std::string> &image_extensions) {
std::vector<std::string> image_paths;
for (const auto &entry: std::filesystem::directory_iterator(directory_path)) {
if (entry.is_regular_file()) {
std::string file_ext = entry.path().extension().string();
file_ext.erase(file_ext.begin()); // 去除扩展名前的点字符
if (std::find(image_extensions.begin(), image_extensions.end(), file_ext) != image_extensions.end()) {
image_paths.push_back(entry.path().string());
}
}
}
return image_paths;
}
int main() {
const std::vector<std::string> image_extensions = {"jpg", "jpeg", "png"};
const std::vector<std::string> video_extensions = {"mp4", "avi", "mov"};
const std::vector<std::string> camera_indexes = {"0", "1", "2"};
std::string ext = getFileExtension(input_source);
// 判断输入源的类型
bool is_image = std::find(image_extensions.begin(), image_extensions.end(), ext) != image_extensions.end();
bool is_video = std::find(video_extensions.begin(), video_extensions.end(), ext) != video_extensions.end();
bool is_directory = std::filesystem::is_directory(input_source);
bool is_camera = std::find(camera_indexes.begin(), camera_indexes.end(), input_source) != camera_indexes.end();
if (!is_camera && !std::filesystem::exists(input_source)) {
std::cerr << "Error: Input source is neither a camera nor does it exist." << std::endl;
return -1;
}
// 如果输入源是图像、视频或摄像头,则设置批次大小为1
if (is_image || is_video || is_camera) {
batch_size = 1;
std::cout << "Input source is an image/video/camera. Batch size set to " << batch_size << std::endl;
} else if (is_directory) {
// 获取目录下的所有图像集合
int total_images = getImageFilesInDirectory(input_source, image_extensions).size();
if (total_images < 1) {
std::cout << "Error: No images found in the directory: " << input_source << std::endl;
return -1;
}
if (total_images < batch_size) {
batch_size = total_images;
std::cout << "The number of images in the directory is less than batch size. Batch size set to"
<< batch_size
<< std::endl;
}
}
// 1. 加载 TensorRT 引擎
std::ifstream file(engine_file, std::ios::binary);
if (!file) {
std::cerr << "Failed to open engine file: " << engine_file << std::endl;
return -1;
}
file.seekg(0, file.end);
size_t engine_size = file.tellg();
file.seekg(0, file.beg);
char *engine_data = new char[engine_size];
file.read(engine_data, engine_size);
file.close();
// 2. 创建 TensorRT 运行时(Runtime)
TRTLogger logger;
IRuntime *runtime = createInferRuntime(logger);
if (!runtime) {
std::cerr << "Failed to create TensorRT runtime." << std::endl;
delete[] engine_data;
return -1;
}
// 3. 反序列化引擎
ICudaEngine *engine = runtime->deserializeCudaEngine(engine_data, engine_size, nullptr);
delete[] engine_data;
if (!engine) {
std::cerr << "Failed to create CUDA engine." << std::endl;
cleanup(nullptr, nullptr, nullptr, nullptr, nullptr, engine, runtime);
return -1;
}
// 4. 创建执行上下文
IExecutionContext *context = engine->createExecutionContext();
if (!context) {
std::cerr << "Failed to create execution context." << std::endl;
cleanup(nullptr, nullptr, nullptr, nullptr, context, engine, runtime);
return -1;
}
// 获取输入、输出节点的索引和名称
int input_index = -1;
int output_index = -1;
std::string input_name;
std::string output_name;
int numBindings = engine->getNbBindings();
for (int i = 0; i < numBindings; ++i) {
const char *bindingName = engine->getBindingName(i);
if (engine->bindingIsInput(i)) {
input_index = i;
input_name = bindingName;
} else {
output_index = i;
output_name = bindingName;
}
}
if (numBindings != 2 || input_index == -1 || output_index == -1) {
std::cerr << "Engine must have exactly one input and one output." << std::endl;
cleanup(nullptr, nullptr, nullptr, nullptr, context, engine, runtime);
return -1;
}
if(is_Dynamic){
// 设置动态批次
Dims input_shape = context->getBindingDimensions(input_index);
input_shape.d[0] = batch_size;
input_shape.d[1] = num_channels;
input_shape.d[2] = input_size.height;
input_shape.d[3] = input_size.width;
if (!context->setInputShape(input_name.c_str(), input_shape)) {
std::cerr << "Failed to set input shape." << std::endl;
cleanup(nullptr, nullptr, nullptr, nullptr, context, engine, runtime);
return -1;
}
}
// 5.申请资源
// 申请 GPU 内存
void **buffers = new void *[numBindings];
cudaMalloc(&buffers[input_index], batch_size * num_channels * input_size.area() * sizeof(float));
std::vector<std::string> classes = load_classes(classes_path); // 读取类别的标签信息
int num_classes = classes.size();
int element_size = 5 + num_classes;
cv::Size output_size(num_anchors, element_size);
cudaMalloc(&buffers[output_index], batch_size * output_size.area() * sizeof(float));
// 确保分配的内存不为空
if (buffers[input_index] == nullptr || buffers[output_index] == nullptr) {
std::cerr << "Error: Failed to allocate GPU memory." << std::endl;
cleanup(nullptr, buffers, nullptr, nullptr, context, engine, runtime);
return -1;
}
// 申请主机内存
float *input_data = new float[batch_size * num_channels * input_size.area()];
float *output_data = new float[batch_size * output_size.area()];
// 黄金预处理、后处理对象
Preprocessor preprocessor(input_size, mean_, std_);
Postprocessor postprocessor(classes, input_size, num_anchors, conf_threshold, nms_threshold);
// 创建 CUDA 流
cudaStream_t stream;
if (cudaStreamCreate(&stream) != cudaSuccess) {
std::cerr << "Error: Failed to create CUDA stream." << std::endl;
cleanup(stream, buffers, input_data, output_data, context, engine, runtime);
return -1;
}
if (is_image) {
// 6. 准备输入数据(预处理)
cv::Mat image = cv::imread(input_source);
cv::Mat blob = preprocessor.process(image);
// 7. 将输入数据拷贝到 GPU
memcpy(input_data, blob.ptr<float>(), batch_size * num_channels * input_size.area() * sizeof(float));
cudaError_t cuda_status = cudaMemcpyAsync(buffers[input_index], input_data,
batch_size * input_size.area() * num_channels * sizeof(float),
cudaMemcpyHostToDevice,
stream);
if (cuda_status != cudaSuccess) {
std::cerr << "CUDA Error: " << cudaGetErrorString(cuda_status) << std::endl;
cleanup(stream, buffers, input_data, output_data, context, engine, runtime);
return -1;
}
// 8. 执行推理
if (!context->enqueueV2(buffers, stream, nullptr)) {
std::cerr << "Error: Inference failed." << std::endl;
cleanup(stream, buffers, input_data, output_data, context, engine, runtime);
return -1;
}
// 9. 获取输出结果到 Host
cuda_status = cudaMemcpy(output_data, buffers[output_index], batch_size * output_size.area() * sizeof(float),
cudaMemcpyDeviceToHost);
if (cuda_status != cudaSuccess) {
std::cerr << "CUDA Error: " << cudaGetErrorString(cuda_status) << std::endl;
cleanup(stream, buffers, input_data, output_data, context, engine, runtime);
return -1;
}
// 9. 后处理
postprocessor.process(image, output_data);
// 显示结果
cv::imshow("Result", image);
cv::waitKey();
} else if (is_camera || is_video) {
// 打开摄像头或视频文件
cv::VideoCapture cap;
if (is_camera) {
int camera_index = std::stoi(input_source);
cap.open(camera_index);
} else if (is_video) {
cap.open(input_source);
}
if (!cap.isOpened()) {
std::cerr << "Error: Failed to open camera or video file: " << input_source << std::endl;
cleanup(stream, buffers, input_data, output_data, context, engine, runtime);
return -1;
}
// 读取帧并进行处理
cv::Mat frame;
while (cap.read(frame)) {
// 预处理帧
cv::Mat blob = preprocessor.process(frame);
// 将输入数据拷贝到 GPU
memcpy(input_data, blob.ptr<float>(), batch_size * num_channels * input_size.area() * sizeof(float));
cudaError_t cuda_status = cudaMemcpyAsync(buffers[input_index], input_data,
batch_size * input_size.area() * num_channels * sizeof(float),
cudaMemcpyHostToDevice,
stream);
if (cuda_status != cudaSuccess) {
std::cerr << "CUDA Error: " << cudaGetErrorString(cuda_status) << std::endl;
cleanup(stream, buffers, input_data, output_data, context, engine, runtime);
return -1;
}
// 执行推理
if (!context->enqueueV2(buffers, stream, nullptr)) {
std::cerr << "Error: Inference failed." << std::endl;
cleanup(stream, buffers, input_data, output_data, context, engine, runtime);
return -1;
}
// 获取输出结果到 Host
cuda_status = cudaMemcpy(output_data, buffers[output_index],
batch_size * output_size.area() * sizeof(float),
cudaMemcpyDeviceToHost);
if (cuda_status != cudaSuccess) {
std::cerr << "CUDA Error: " << cudaGetErrorString(cuda_status) << std::endl;
cleanup(stream, buffers, input_data, output_data, context, engine, runtime);
return -1;
}
// 后处理
postprocessor.process(frame, output_data);
// 显示结果
cv::imshow("Result", frame);
// 等待按键,按下 'q' 退出
if (cv::waitKey(1) == 'q') {
break;
}
}
cap.release(); // 释放摄像头或视频文件
} else if (is_directory && is_Dynamic) {
std::vector<std::string> image_paths = getImageFilesInDirectory(input_source, image_extensions);
int total_images = image_paths.size();
int num_batches = total_images % batch_size ? total_images / batch_size + 1 : total_images / batch_size;
for (int i = 0; i < num_batches; ++i) {
int current_batch_size = std::min(batch_size, total_images - i * batch_size);
// 如果当前批次的大小与之前的批次不一致,需要调整输入和输出内存
if (current_batch_size != batch_size) {
// 释放原有的内存
cudaFree(buffers[input_index]);
cudaFree(buffers[output_index]);
delete[] input_data;
delete[] output_data;
// 申请新的内存
input_data = new float[current_batch_size * num_channels * input_size.area()];
output_data = new float[current_batch_size * output_size.area()];
cudaMalloc(&buffers[input_index],
current_batch_size * num_channels * input_size.area() * sizeof(float));
cudaMalloc(&buffers[output_index], current_batch_size * output_size.area() * sizeof(float));
// 设置动态批次
Dims input_shape = context->getBindingDimensions(input_index);
input_shape.d[0] = current_batch_size;
input_shape.d[1] = num_channels;
input_shape.d[2] = input_size.height;
input_shape.d[3] = input_size.width;
if (!context->setInputShape(input_name.c_str(), input_shape)) {
std::cerr << "Failed to set input shape." << std::endl;
cleanup(nullptr, nullptr, nullptr, nullptr, context, engine, runtime);
return -1;
}
}
// 处理当前批次的图像
for (int j = 0; j < current_batch_size; ++j) {
cv::Mat image = cv::imread(image_paths[i * batch_size + j]);
cv::Mat blob = preprocessor.process(image);
// 拷贝输入数据到 GPU
memcpy(input_data + j * num_channels * input_size.area(), blob.ptr<float>(),
num_channels * input_size.area() * sizeof(float));
}
cudaError_t cuda_status = cudaMemcpyAsync(buffers[input_index], input_data,
current_batch_size * input_size.area() * num_channels * sizeof(
float),
cudaMemcpyHostToDevice, stream);
if (cuda_status != cudaSuccess) {
std::cerr << "CUDA Error: " << cudaGetErrorString(cuda_status) << std::endl;
cleanup(stream, buffers, input_data, output_data, context, engine, runtime);
return -1;
}
// 执行推理
if (!context->enqueueV2(buffers, stream, nullptr)) {
std::cerr << "Error: Inference failed." << std::endl;
cleanup(stream, buffers, input_data, output_data, context, engine, runtime);
return -1;
}
// 获取输出结果到 Host
cuda_status = cudaMemcpy(output_data, buffers[output_index],
current_batch_size * output_size.area() * sizeof(float),
cudaMemcpyDeviceToHost);
if (cuda_status != cudaSuccess) {
std::cerr << "CUDA Error: " << cudaGetErrorString(cuda_status) << std::endl;
cleanup(stream, buffers, input_data, output_data, context, engine, runtime);
return -1;
}
// 后处理并显示结果
for (int j = 0; j < current_batch_size; ++j) {
cv::Mat image = cv::imread(image_paths[i * batch_size + j]);
postprocessor.process(image, output_data + j * output_size.area());
cv::imshow("Result" + j, image);
}
cv::waitKey();
}
} else {
// 输入源类型不支持
std::cerr << "Error: Unsupported input source type: " << input_source << std::endl;
return -1;
}
// 10. 释放资源
cleanup(stream, buffers, input_data, output_data, context, engine, runtime);
return 0;
}
4.4.4 preprocess.h
#ifndef PREPROCESS_H
#define PREPROCESS_H
#include <opencv2/opencv.hpp>
// 在不同平台下处理动态链接库(DLL)的导出
#ifdef _WIN32
#define DLL_EXPORT __declspec(dllexport)
#else
#define DLL_EXPORT
#endif
class DLL_EXPORT Preprocessor {
public:
Preprocessor(const cv::Size &input_size, const cv::Scalar &mean, const cv::Scalar &std)
: input_size_(input_size), mean_(mean), std_(std) {
}
cv::Mat process(const cv::Mat &image);
cv::Mat process(const std::vector<cv::Mat> &images);
private:
cv::Size input_size_;
cv::Scalar mean_;
cv::Scalar std_;
};
#endif // PREPROCESS_H
4.4.5 preprocess.cpp
#include "preprocess.h"
cv::Mat Preprocessor::process(const cv::Mat &image) {
cv::Mat resized_img, padded_img, blob_img;
int new_w, new_h;
// 根据宽高比计算新的宽和高
if ((float) image.cols / image.rows >= (float) input_size_.width / input_size_.height) {
new_w = input_size_.width;
new_h = image.rows * input_size_.width / image.cols;
} else {
new_h = input_size_.height;
new_w = image.cols * input_size_.height / image.rows;
}
// 调整图像大小
cv::resize(image, resized_img, cv::Size(new_w, new_h));
// 计算填充边界
int top = (input_size_.height - new_h) / 2;
int bottom = input_size_.height - new_h - top;
int left = (input_size_.width - new_w) / 2;
int right = input_size_.width - new_w - left;
// 为调整大小的图像添加边界
cv::copyMakeBorder(resized_img, padded_img, top, bottom, left, right, cv::BORDER_CONSTANT, cv::Scalar(0, 0, 0));
// 将图像转换为适合深度学习模型输入的 blob 格式
blob_img = cv::dnn::blobFromImage(padded_img, 1 / 255.0, input_size_, mean_, true, false);
// 对每个通道进行标准差归一化
std::vector<cv::Mat> channels(3);
cv::split(blob_img, channels);
for (int i = 0; i < channels.size(); i++) {
channels[i] = (channels[i] - mean_[i]) / std_[i];
}
cv::merge(channels, blob_img);
return blob_img;
}
cv::Mat Preprocessor::process(const std::vector<cv::Mat> &images) {
// 实现批处理的预处理逻辑
std::vector<cv::Mat> processed_images;
for (const auto &image: images) {
processed_images.push_back(process(image));
}
// 合并处理后的图像为一个 Mat 对象
return cv::Mat(processed_images.size(), processed_images[0].rows, processed_images[0].type(),
processed_images.data());
}
4.4.6 postprocess.h
#ifndef POSTPROCESSOR_H
#define POSTPROCESSOR_H
#include <opencv2/opencv.hpp>
#include <vector>
#include <string>
// 在不同平台下处理动态链接库(DLL)的导出
#ifdef _WIN32
#define DLL_EXPORT __declspec(dllexport)
#else
#define DLL_EXPORT
#endif
class DLL_EXPORT Postprocessor {
public:
Postprocessor(const std::vector<std::string> &classes, const cv::Size &input_size, int num_anchors,
float conf_threshold, float nms_threshold)
: classes_(classes), input_size_(input_size), num_anchors_(num_anchors),
conf_threshold_(conf_threshold), nms_threshold_(nms_threshold) {
generateColors();
}
void process(cv::Mat &img, float *output_data);
void process(const std::vector<cv::Mat> &images, float *output_data);
private:
std::vector<std::string> classes_;
cv::Size input_size_;
int num_anchors_;
float conf_threshold_;
float nms_threshold_;
std::vector<cv::Scalar> colors_;
void generateColors();
};
#endif // POSTPROCESSOR_H
4.4.7 postprocess.cpp
#include "postprocess.h"
void Postprocessor::generateColors() {
cv::RNG rng(42); // Initialize a random number generator
for (size_t i = 0; i < classes_.size(); i++) {
colors_.emplace_back(rng.uniform(0, 256), rng.uniform(0, 256), rng.uniform(0, 256));
}
}
// 处理单张图像
void Postprocessor::process(cv::Mat &img, float *output_data) {
int num_classes = classes_.size();
int element_size = 5 + num_classes;
cv::Mat output_mat = cv::Mat(num_anchors_, element_size, CV_32F, output_data);
std::vector<cv::Rect> boxes;
std::vector<int> class_ids;
std::vector<float> confidences;
// 计算宽高比和缩放比例
float scale = std::min(static_cast<float>(input_size_.width) / img.cols,
static_cast<float>(input_size_.height) / img.rows);
int new_w = img.cols * scale;
int new_h = img.rows * scale;
int x_offset = (input_size_.width - new_w) / 2;
int y_offset = (input_size_.height - new_h) / 2;
for (int i = 0; i < output_mat.rows; i++) {
float confidence = output_mat.at<float>(i, 4);
if (confidence >= conf_threshold_) {
float *classes_scores = &output_mat.at<float>(i, 5);
int class_id = std::max_element(classes_scores, classes_scores + num_classes) - classes_scores;
float max_class_score = classes_scores[class_id];
if (max_class_score > conf_threshold_) {
int cx = output_mat.at<float>(i, 0);
int cy = output_mat.at<float>(i, 1);
int w = output_mat.at<float>(i, 2);
int h = output_mat.at<float>(i, 3);
// 反算回原图坐标
int original_cx = static_cast<int>((cx - x_offset) / scale);
int original_cy = static_cast<int>((cy - y_offset) / scale);
int original_w = static_cast<int>(w / scale);
int original_h = static_cast<int>(h / scale);
int left = original_cx - original_w / 2;
int top = original_cy - original_h / 2;
boxes.emplace_back(left, top, original_w, original_h);
class_ids.push_back(class_id);
confidences.push_back(confidence);
}
}
}
std::vector<int> indices;
cv::dnn::NMSBoxes(boxes, confidences, conf_threshold_, nms_threshold_, indices);
std::vector<cv::Rect> final_boxes;
std::vector<int> final_class_ids;
std::vector<float> final_confidences;
for (int idx: indices) {
final_boxes.push_back(boxes[idx]);
final_class_ids.push_back(class_ids[idx]);
final_confidences.push_back(confidences[idx]);
}
// 绘制检测框、类别和置信度
for (size_t i = 0; i < final_boxes.size(); i++) {
cv::Rect box = final_boxes[i];
int class_id = final_class_ids[i];
cv::Scalar color = colors_[class_id];
cv::rectangle(img, box, color, 2);
// 组合类别和置信度的标签
std::string label = cv::format("%s: %.2f", classes_[class_id].c_str(), final_confidences[i]);
// 设置文本标签的位置
int baseLine;
cv::Size labelSize = cv::getTextSize(label, cv::FONT_HERSHEY_SIMPLEX, 0.5, 1, &baseLine);
int top = std::max(box.y, labelSize.height);
cv::rectangle(img, cv::Point(box.x, top - labelSize.height),
cv::Point(box.x + labelSize.width, top + baseLine),
color, cv::FILLED);
cv::putText(img, label, cv::Point(box.x, top),
cv::FONT_HERSHEY_SIMPLEX, 0.5, cv::Scalar(0, 0, 0), 1);
}
}
// 处理多张图像
void Postprocessor::process(const std::vector<cv::Mat> &images, float *output_data) {
// 每张图像的输出大小
int single_output_size = num_anchors_ * (5 + classes_.size());
for (size_t i = 0; i < images.size(); ++i) {
// 获取指向当前图像输出数据的指针
float *current_output = output_data + i * single_output_size;
// 处理单张图像
process(images[i], current_output);
}
}
5 Jetson Nano 部署
- 参考文档:jetson相关软件安装说明.pdf
5.1 烧录操作系统
Jetson Nano 官方参考文档:https://developer.nvidia.com/embedded/learn/get-started-jetson-nano-devkit#intro

5.1.1 硬件准备
- Jetson Nano 4G 内存版
- Windows 电脑
- 32G 以上空间的 TF 存储卡
- TF 读卡器
5.1.2 下载 OS 镜像
Jetson Nano 开发者套件 SD 卡镜像地址:https://developer.nvidia.com/jetson-nano-sd-card-image
5.1.3 格式化 TF 卡
使用 SD 协会的 SD 存储卡格式化程序格式化您的 microSD 卡:

- 下载、安装并启动适用于 Windows 的 SD 存储卡格式化程序。
- 选择卡驱动器
- 选择 "Quick format"
- 将 "Volume label" 留空
- 单击 "format" 开始格式化,然后单击警告对话框中的 "yes"
5.1.4 将镜像写入 TF 卡
在格式化 TF 卡后,再使用 Etcher 将 Jetson Nano 开发者套件 SD 卡镜像写入 TF 卡(TF 开保存插入状态):
-
下载、安装并启动 Etcher。
-
单击 "从文件烧录",然后选择之前下载的压缩图像文件。
-
单击 "选择目标磁盘" 并选择正确的设备。
-
点击 "现在烧录! " 如果您的 TF 卡是通过 USB3 连接的,Etcher 大约需要 10 分钟来写入和验证镜像。
-
Etcher 完成后,Windows 可能会让格式化 TF 卡,只需点击 "取消" 并取出 TF 卡即可。
5.1.5 初始化 OS
- 插上键盘、鼠标、TF卡
- 插上网线(nano不带无线网卡,且不建议用USB网卡,不稳定)
- 插上电
- 使用 HDMI 线外接显示屏
- 设置好用户名密码




注意
在 Ubuntu 系统中,root无法作为普通用户的用户名使用,因为root是系统保留的超级用户账户。
在等待系统安装完成后,登录自己创建的账号即可:


使用 ifconfig 命令查看 Jetson Nano 所处的局域网 IP 地址,我的案例中是 192.168.1.140:

5.2 远程控制 Jetson Nano
如果你有外接显示器、键盘和鼠标,就可以直接将这些外设连接到 Jetson Nano 上,像操作普通电脑一样操作它。
如果无法直接通过外接显示器来操作 Jetson Nano,但 Jetson Nano 已经连接到网络(局域网),则可以考虑以下几种方式:
- 如果仅需使用命令行,则可以使用 SSH 远程登录工具:FinalShell
- 如果需要图形化界面,则可以使用图像化的登录工具:NoMachine
对于第一种方式不过多赘述,接下来将介绍如何使用图形化工具 NoMachine 进行远程操作:
-
在你的电脑上安装 NoMachine 客户端
前往 NoMachine 官网,选择适合你操作系统的客户端版本:

-
在 Jetson Nano 上安装 NoMachine
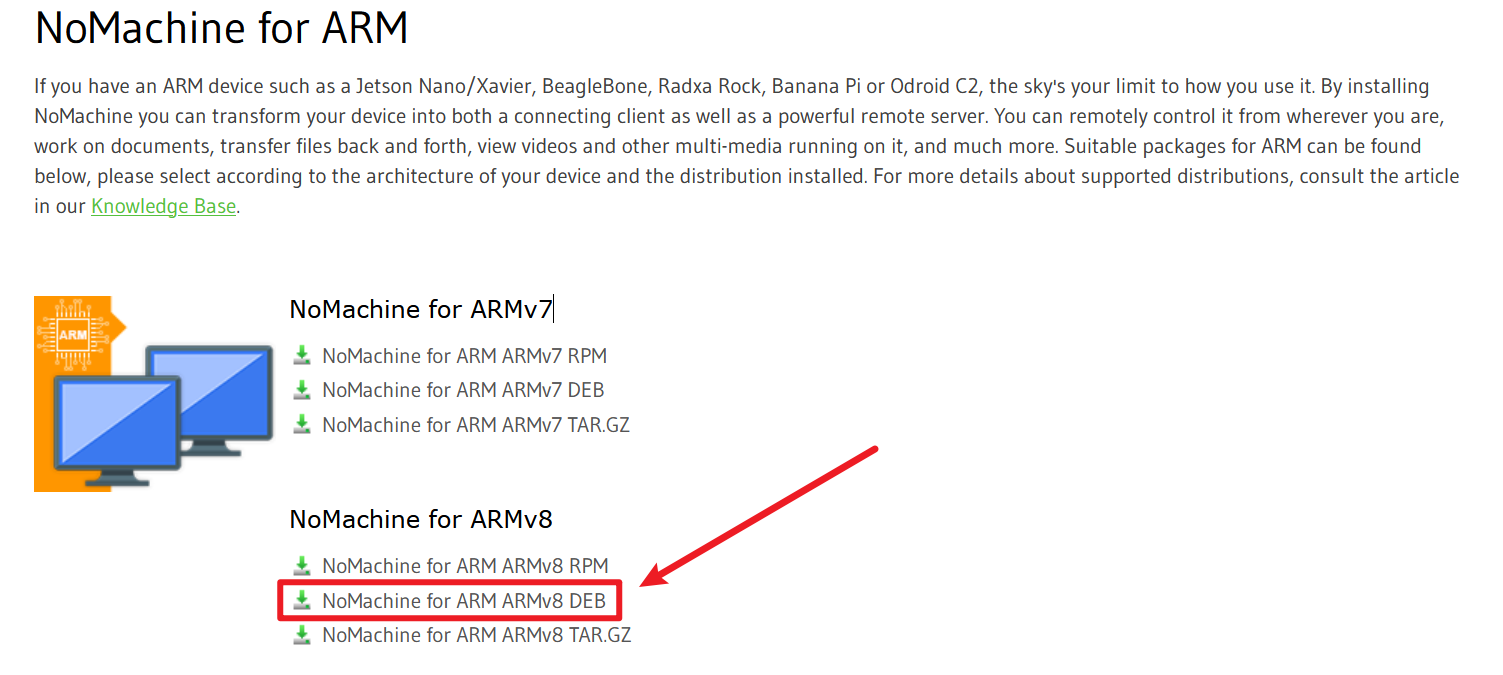
前往 NoMachine 官网选择和 Jetson Nano 的 64 位 ARMv8 架构 SoC 兼容的版本,又由于系统是 Ubuntu 的,所以最终选择 NoMachine for ARM ARMv8 DEB 手动进行下载:
手动下载完成后还需要将安装包上传到 Jetson Nano 中。当然也可以直接使用命令进行安装:
wget https://download.nomachine.com/download/8.13/Arm/nomachine_8.13.1_1_arm64.deb当 Jetson Nano 中存在 NoMachine 安装包后,执行以下命令进行安装:
sudo dpkg -i nomachine_8.13.1_1_arm64.deb安装完成后,NoMachine 服务器会自动启动,你可以通过访问局域网内的 IP 地址进行远程连接。
-
获取 Jetson Nano 的 IP 地址
可以在 Jetson Nano 的终端输入以下命令,查看其在局域网中的 IP 地址:ifconfig记下显示的
eth0或wlan0接口的 IP 地址。 -
使用 NoMachine 客户端连接到 Jetson Nano
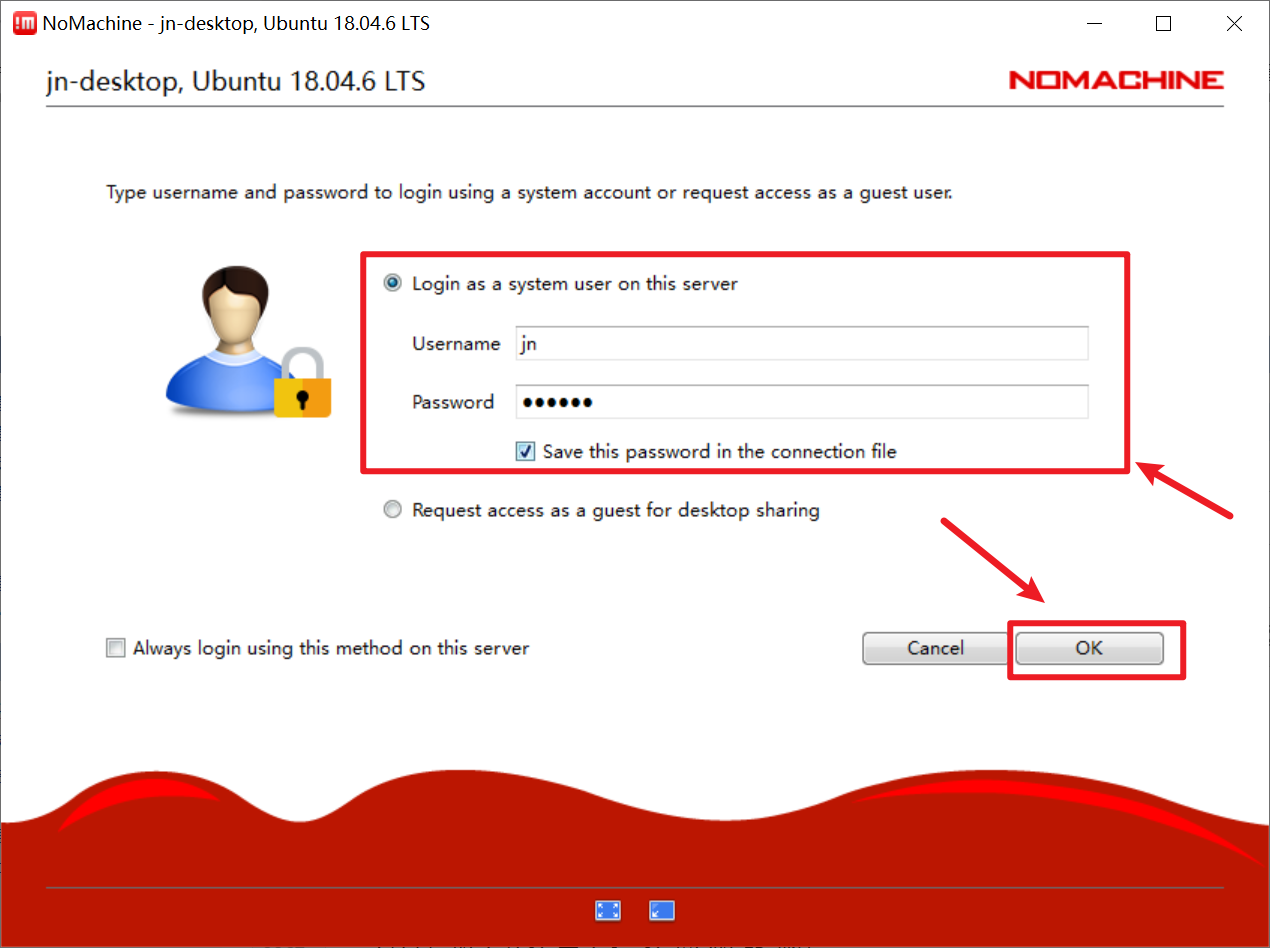
在输入用户名密码连接成功后,你将能够通过 NoMachine 在你的电脑上操作 Jetson Nano,就像通过直接连接显示器一样进行图形化操作:


5.3 更换镜像源
为了加快软件和库的下载速度,我们需要将 Jetson Nano 的软件源和 pip 的 Python 包源切换到清华大学的镜像源。(如果有**就不需要还原,国内的网络还是推荐换源后再使用)
5.3.1 更换 Ubuntu 软件源
-
备份原有的 sources.list 文件
为了确保在更换源出现问题时可以恢复到默认状态,我们需要提前备份 sources.list 文件:sudo cp /etc/apt/sources.list /etc/apt/sources.list.bak -
修改 sources.list 文件
打开 sources.list 文件进行编辑:sudo vim /etc/apt/sources.list在 Vim 编辑器中,按
dG删除文件中所有内容(这将删除从光标位置到文件末尾的所有行)。然后复制并粘贴以下内容,将清华大学的镜像源地址添加到文件中:deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ bionic main multiverse restricted universe deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ bionic-security main multiverse restricted universe deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ bionic-updates main multiverse restricted universe deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ bionic-backports main multiverse restricted universe deb-src http://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ bionic main multiverse restricted universe deb-src http://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ bionic-security main multiverse restricted universe deb-src http://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ bionic-updates main multiverse restricted universe deb-src http://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ bionic-backports main multiverse restricted universe最后按
Esc键退出编辑模式,输入:wq保存文件并退出 Vim。 -
更新软件包列表并升级系统
首先更新软件包列表:sudo apt-get update然后升级系统中的所有软件包到最新版本:
sudo apt-get upgrade
5.3.2 更换 pip 包源
-
创建 .pip 目录
如果用户目录下还没有 .pip 目录,需要创建它:mkdir -p ~/.pip -
创建或编辑 pip.conf 文件
进入 .pip 目录并创建或编辑 pip.conf 文件:cd ~/.pip vim pip.conf将以下内容粘贴到文件中,以使用清华大学的镜像源:
[global] index-url = https://pypi.tuna.tsinghua.edu.cn/simple/ [install] trusted-host = pypi.tuna.tsinghua.edu.cn按
Esc键退出编辑模式,输入:wq保存文件并退出 Vim。 -
升级 pip
确保系统中的 pip 是最新版本:python3 -m pip install --upgrade pip如果你在执行上述命令时遇到 "no module named pip" 错误,可能是因为系统中没有安装 pip 或者 pip 还没有正确配置。首先尝试重新安装 pip:
sudo apt-get install python3-pip如果 pip 安装成功,你可以再尝试执行升级 pip 的命令。
5.4 安装 jtop 监控工具
jtop 是一个监控工具,可以帮助你在 NVIDIA Jetson 设备上实时监控 CPU、GPU、内存和电源等使用情况。下面是安装 jtop 的步骤:
-
安装 jetson-stats 包
确保系统的软件包列表是最新后,执行以下命令:sudo -H pip3 install -U jetson-stats -
验证安装
安装完成后,你可以通过运行以下命令来验证jtop是否已正确安装:jtop如果验证过程中遇到权限问题可以使用
sudo jtop或者重启解决。
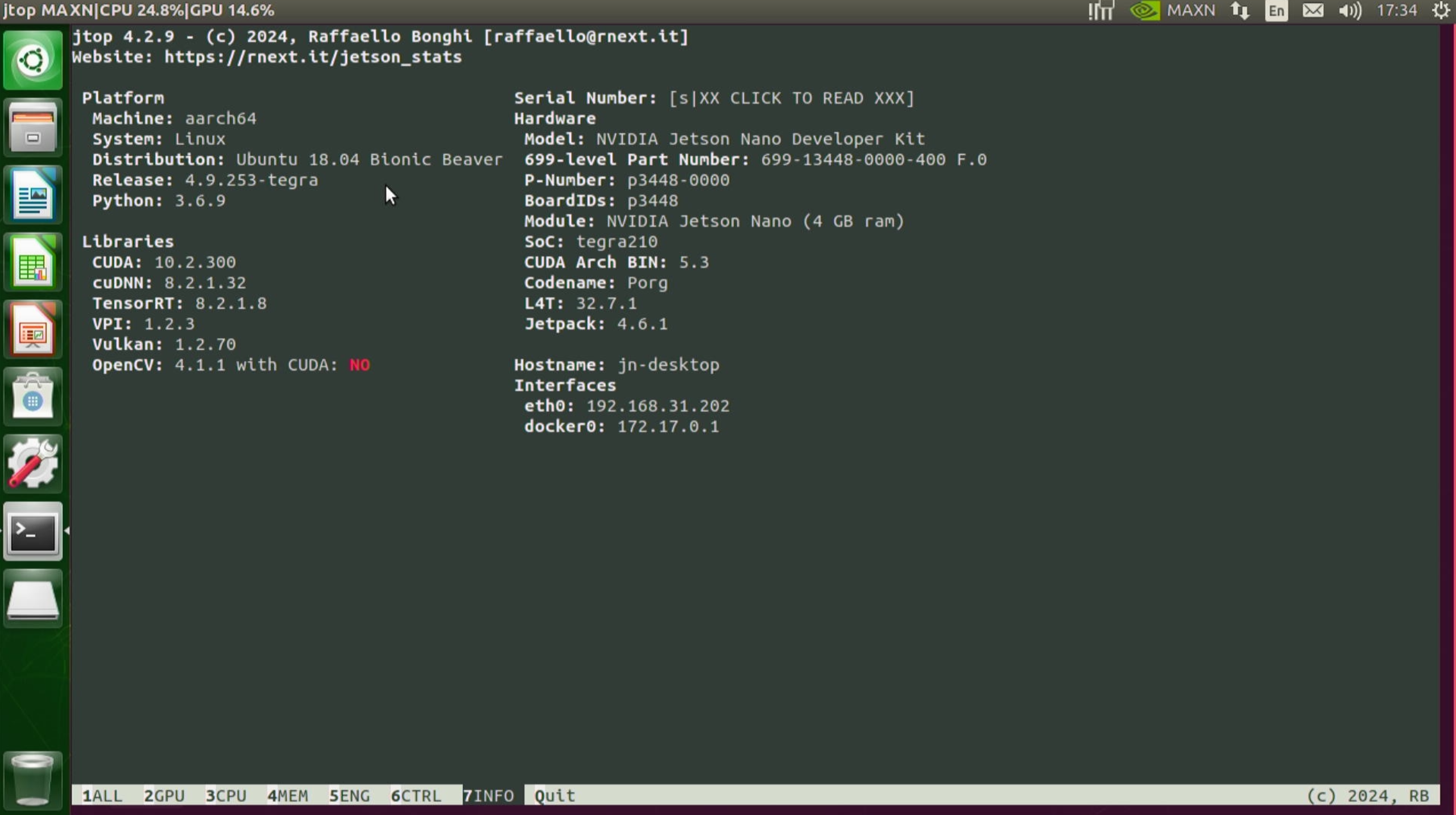
如果 jtop 已成功安装,命令会打开一个基于命令行的监控界面,显示 Jetson 设备的各项资源使用情况和预装的软件依赖:

5.4 更新 CMake
当项目要求的 CMake 版本高于系统默认安装的版本时,需要手动更新 CMake。以下步骤将指导你如何在 Jetson Nano 上更新 CMake 版本:
-
检查当前 CMake 版本
首先,检查系统中当前安装的 CMake 版本:cmake --version -
卸载旧版本的 CMake
如果你的 CMake 版本较旧,并且需要安装最新版本,首先可以卸载旧版本:sudo apt-get remove --purge cmake -
下载最新的 CMake
访问 CMake官网 或直接使用wget命令下载最新的 CMake 版本。例如,下载 CMake 3.28.0:wget https://github.com/Kitware/CMake/releases/download/v3.28.0/cmake-3.28.0-linux-aarch64.tar.gz -
解压安装包
执行以下命令解压下载的安装包文件:tar -zxvf cmake-3.28.0-linux-aarch64.tar.gz -
将解压的 CMake 目录移动到系统目录
移动解压后的 CMake 目录到系统目录/opt中,并命名为 cmake-3.28.0:sudo mv cmake-3.28.0-linux-aarch64 /opt/cmake-3.28.0 -
创建软连接
为了方便在终端中使用 CMake,可以创建一个软连接,将它链接到/usr/bin:sudo ln -sf /opt/cmake-3.28.0/bin/* /usr/bin/ -
验证安装
编译和安装完成后,验证 CMake 是否正确安装,并检查其版本号是否更新:cmake --version如果显示的是最新版本的 CMake,那么更新过程已经成功完成。
5.5 升级 G++
如果你需要使用 C++17 中的 <filesystem> 库,那么确实需要将 G++ 升级到 8.0 或更高版本,因为 <filesystem> 在 G++8 中得到了全面支持。具体升级步骤如下所示:
升级 G++ 版本可以解决 CMake 编译过程中出现的
fatal error:filesystem:No such file or directory错误。
-
查看当前G++版本
在终端中运行以下命令来查看当前安装的 G++ 版本:
g++ --version -
安装 G++8
使用以下命令安装 G++8:
sudo apt-get update sudo apt-get install g++-8 -
将 G++8 添加到
update-alternatives中将 G++8添加到
update-alternatives管理中,以便可以选择默认使用哪个版本:sudo update-alternatives --install /usr/bin/g++ g++ /usr/bin/g++-8 60这里的
60是优先级,你可以根据需求设置不同的优先级值。 -
更新默认G++版本
通过运行以下命令手动选择默认的 G++ 版本:
sudo update-alternatives --config g++系统会列出可用的 G++ 版本,你可以输入相应的编号来选择 G++8 作为默认版本。
-
验证 G++ 版本
再次运行以下命令,验证 G++ 是否已经成功更新到所需版本:
g++ --version
5.6 配置 CUDA 环境变量
Jetson Nano 虽然已经安装了 CUDA,但未配置 CUDA 相关的环境变量。以下是 CUDA 环境变量的配置步骤:
-
打开并编辑 .bashrc 文件
使用以下命令编辑用户目录下的 .bashrc 文件:sudo vim ~/.bashrc -
添加 CUDA 环境变量
在打开的 .bashrc 文件中,滚动到文档的最底部,然后添加以下内容:export CUDA_HOME=/usr/local/cuda-10.2 export LD_LIBRARY_PATH=/usr/local/cuda-10.2/lib64:$LD_LIBRARY_PATH export PATH=/usr/local/cuda-10.2/bin:$PATH按
Esc键退出编辑模式,输入:wq保存文件并退出 Vim。 -
使环境变量生效
在终端中执行以下命令,使新配置的环境变量立即生效:source ~/.bashrc -
验证 CUDA 配置
要验证 CUDA 是否配置成功,可以运行以下命令检查 CUDA 编译器 (nvcc) 的版本:nvcc -V如果配置成功,终端将显示 CUDA 编译器的版本信息:
5.7 部署 YOLOv5 项目(C++版)
整个项目的目录结构如下所示:
5.6.1 CMakeLists.txt
# 指定项目名称
set(PROJECT_NAME yolov5_trt)
# 设置 CMake 的最低版本要求
cmake_minimum_required(VERSION 3.28)
# 定义项目名称并指定使用 CUDA 和 C++ 语言
project(${PROJECT_NAME} CUDA CXX)
# 设置 C++ 标准为 C++17
set(CMAKE_CXX_STANDARD 17)
set(CMAKE_CXX_STANDARD_REQUIRED ON)
# 查找 CUDA 库
find_package(CUDAToolkit REQUIRED)
# 包含 CUDA 的头文件路径
include_directories(${CUDAToolkit_INCLUDE_DIRS})
# 设置 TensorRT 的库和头文件路径
set(TENSORRT_LIB_DIR "/usr/lib/aarch64-linux-gnu/")
set(TENSORRT_INCLUDE_DIR "/usr/include/aarch64-linux-gnu/")
# 包含 TensorRT 的头文件路径
include_directories("${TENSORRT_INCLUDE_DIR}")
# 将 TensorRT 库目录添加到链接器的搜索路径中
link_directories("${TENSORRT_LIB_DIR}")
# 查找 OpenCV 库
find_package(OpenCV REQUIRED)
# 包含 OpenCV 的头文件路径
include_directories(${OpenCV_INCLUDE_DIRS})
# 指定包含文件的目录路径
set(INCLUDE_DIR "include")
# 定义项目头文件
file(GLOB HEADERS "${INCLUDE_DIR}/*.h")
# 定义项目的源文件(指定源文件或全部源文件)
file(GLOB SOURCES "${INCLUDE_DIR}/*.cpp" yolov5_trt.cpp)
# 创建一个名为 yolov5_trt 的可执行文件,并指定要编译的源文件和头文件
add_executable(${PROJECT_NAME} ${SOURCES} ${HEADERS})
# 链接库文件到可执行文件 yolov5_trt 中,确保链接 TensorRT 和 CUDA 库
target_link_libraries(${PROJECT_NAME} PRIVATE
stdc++fs # 文件系统库
nvinfer # TensorRT 推理库
nvonnxparser # TensorRT ONNX 解析库
${OpenCV_LIBS} # OpenCV 库
${CUDA_LIBRARIES} # CUDA 库
${CUDA_cublas_LIBRARY} # CUDA BLAS 库
${CUDA_cudart_LIBRARY} # CUDA Runtime 库
${CUDA_cudnn_LIBRARY} # CUDA cuDNN 库
${CUDAToolkit_LIBRARIES} # CUDA Toolkit 库
)
# 设置可执行文件的输出路径
set(EXECUTABLE_OUTPUT_PATH "${CMAKE_BINARY_DIR}/bin")
# 设置资源文件的源目录
set(RESOURCE_DIR "${CMAKE_SOURCE_DIR}/resources")
# 将资源文件复制到可执行文件所在目录
file(COPY ${RESOURCE_DIR} DESTINATION ${EXECUTABLE_OUTPUT_PATH})
这段 CMake 代码配置了一个名为 yolov5_trt 的项目,主要目的是为 Jetson Nano 平台上的 YOLOv5 模型推理创建一个可执行文件。关键步骤包括:
- 设置 CMake 的最低版本要求和项目名称。
- 配置项目使用的 C++17 标准,并查找 CUDA、TensorRT 和 OpenCV 库。
- 包含这些库的头文件和库文件路径。
- 定义并添加项目的源文件和头文件,生成可执行文件 yolov5_trt。
- 将 TensorRT、CUDA、OpenCV 等必要的库链接到生成的可执行文件中。
- 设置可执行文件的输出目录,并将资源文件(如模型和标签文件)复制到该目录下。
5.6.2 yolov5_trt.cpp
需要注意以下几点:
- Jetson Nano 不支持动态批次,所以在推理过程中不能设置输入张量的形状
- yolov5_trt.cpp 是将 yolov5_build.cpp 的代码 yolov5_runtime.cpp 结合到一起得到的。
- postprocess.h/cpp和preprocess.h/cpp 的代码和第 4 章中 4.4.4~4.4.7 中的代码完全一致。
resources/images中是用于测试的图像。resources/best.onnx是用于构建 engine 模型文件的 onnx 模型。resources/classes.txt中记录的是类别列表,不同类别用换行符进行分隔离。
#include <iostream>
#include <fstream>
#include <NvInfer.h>
#include <NvOnnxParser.h>
#include <vector>
#include <cassert>
#include <cuda_runtime.h>
#include <opencv2/opencv.hpp>
#include "include/postprocess.h"
#include "include/preprocess.h"
#include <filesystem>
using namespace nvinfer1;
/**
* 构建阶段配置
***/
// ONNX 模型和 TensorRT engine 文件的路径
std::string onnx_model_path = "resources/best.onnx";
std::string trt_model_path = "resources/yolov5.engine";
// 是否使用 fp16 量化
bool is_fp16 = true;
// 是否使用动态输入
bool is_Dynamic = false;
// 使用动态输入时允许的最小、最优和最大输入尺寸
Dims min_shape{4, {1, 3, 320, 320}};
Dims opt_shape{4, {64, 3, 640, 640}};
Dims max_shape{4, {128, 3, 640, 640}};
/**
* 推理阶段配置
***/
// 检测源路径,可以是图像、视频、摄像头(0)、图像目录
std::string input_source = "resources/images/0_8w7mkX-PHcfMM5s6_jpeg.rf.039eb72a4757882968537a6ae94d198f.jpg";
// std::string input_source = "0";
// std::string input_source = "resources/images";
// 预处理设置
cv::Scalar mean_ = cv::Scalar(0, 0, 0); // 均值
cv::Scalar std_ = cv::Scalar(1, 1, 1); // 标准差
// 模型输入输出信息
int batch_size = 8;
int num_channels = 3; // yolov5只支持3通道
cv::Size input_size(640, 640);
int num_anchors = 25200;
std::string classes_path = "resources/classes.txt";
// 后处理设置
float conf_threshold = 0.25f;
float nms_threshold = 0.45f;
// 定义一个自定义的日志记录器类 TRTLogger,继承自 TensorRT 的 ILogger 接口
class TRTLogger : public ILogger {
void log(Severity severity, const char *msg) noexcept override {
// 屏蔽掉 INFO 等级的日志消息
if (severity != Severity::kINFO) {
std::cout << msg << std::endl;
}
}
};
// 判断文件扩展名
std::string getFileExtension(const std::string &filename) {
size_t pos = filename.find_last_of(".");
if (pos != std::string::npos) {
return filename.substr(pos + 1);
}
return "";
}
// 加载类别名
std::vector<std::string> load_classes(const std::string &classes_path) {
std::vector<std::string> class_names;
std::ifstream file(classes_path);
if (!file.is_open()) {
std::cerr << "Failed to open classes file: " << classes_path << std::endl;
return class_names;
}
std::string line;
while (std::getline(file, line)) {
if (!line.empty()) {
class_names.push_back(line);
}
}
file.close();
return class_names;
}
// 运行时阶段释放推理资源的函数
void runtimeCleanup(cudaStream_t stream, void **buffers, float *input_data, float *output_data,
IExecutionContext *context, ICudaEngine *engine, IRuntime *runtime) {
if (stream) cudaStreamDestroy(stream);
if (buffers) {
// 默认只有一个输入和一个输出
if (buffers[0]) cudaFree(buffers[0]);
if (buffers[1]) cudaFree(buffers[1]);
delete[] buffers;
}
if (input_data) delete[] input_data;
if (output_data) delete[] output_data;
if (context) context->destroy();
if (engine) engine->destroy();
if (runtime) runtime->destroy();
}
// 构建阶段释放资源的函数
void buildCleanup(IHostMemory *serializedModel, ICudaEngine *engine, IBuilderConfig *config,
nvonnxparser::IParser *parser,
INetworkDefinition *network, IBuilder *builder) {
if (serializedModel) serializedModel->destroy();
if (engine) engine->destroy();
if (config) config->destroy();
if (parser) parser->destroy();
if (network) network->destroy();
if (builder) builder->destroy();
}
std::vector<std::string> getImageFilesInDirectory(const std::string &directory_path,
const std::vector<std::string> &image_extensions) {
std::vector<std::string> image_paths;
for (const auto &entry: std::filesystem::directory_iterator(directory_path)) {
if (entry.is_regular_file()) {
std::string file_ext = entry.path().extension().string();
file_ext.erase(file_ext.begin()); // 去除扩展名前的点字符
if (std::find(image_extensions.begin(), image_extensions.end(), file_ext) != image_extensions.end()) {
image_paths.push_back(entry.path().string());
}
}
}
return image_paths;
}
// 判断engine文件是否存在
bool doesEngineFileExist(const std::string &filePath) {
std::ifstream file(filePath);
return file.good();
}
int createAndSaveTRTEngine() {
// 1. 创建 builder
TRTLogger logger;
IBuilder *builder = createInferBuilder(logger);
if (!builder) {
std::cerr << "Failed to create TensorRT builder." << std::endl;
return -1;
}
// 2. 创建网络定义
INetworkDefinition *network = builder->createNetworkV2(
1U << static_cast<uint32_t>(NetworkDefinitionCreationFlag::kEXPLICIT_BATCH)
);
if (!network) {
std::cerr << "Failed to create TensorRT network definition." << std::endl;
buildCleanup(nullptr, nullptr, nullptr, nullptr, network, builder);
return -1;
}
// 使用 ONNX Parser 构建网络模型
nvonnxparser::IParser *parser = nvonnxparser::createParser(*network, logger);
if (!parser) {
std::cerr << "Failed to create TensorRT parser." << std::endl;
buildCleanup(nullptr, nullptr, nullptr, parser, network, builder);
return -1;
}
// 解析 ONNX 模型文件
bool success = parser->parseFromFile(onnx_model_path.c_str(), static_cast<int>(ILogger::Severity::kWARNING));
if (!success) {
std::cerr << "Failed to parse the ONNX model: " << onnx_model_path << std::endl;
for (int i = 0; i < parser->getNbErrors(); ++i) {
auto *error = parser->getError(i);
std::cerr << "Error [" << i << "] "
<< "Severity: " << static_cast<int>(error->code()) << " "
<< "Message: " << error->desc() << std::endl;
}
buildCleanup(nullptr, nullptr, nullptr, parser, network, builder);
return -1;
}
std::cout << "Successfully parsed the ONNX model: " << onnx_model_path << std::endl;
// 3. 创建配置参数
IBuilderConfig *config = builder->createBuilderConfig();
if (!config) {
std::cerr << "Failed to create TensorRT builder configuration." << std::endl;
buildCleanup(nullptr, nullptr, nullptr, parser, network, builder);
return -1;
}
// 设置最大工作空间大小为 1 GB
config->setMaxWorkspaceSize(1 << 30);
// 设置启用 fp16 量化模式
if (is_fp16 && builder->platformHasFastFp16()) {
config->setFlag(BuilderFlag::kFP16);
}
// 创建优化配置文件(用于动态输入)
if (is_Dynamic) {
IOptimizationProfile *profile = builder->createOptimizationProfile();
if (!profile) {
std::cerr << "Failed to create optimization profile." << std::endl;
buildCleanup(nullptr, nullptr, config, parser, network, builder);
return -1;
}
ITensor *input_tensor = network->getInput(0);
const char *input_name = input_tensor->getName();
profile->setDimensions(input_name, OptProfileSelector::kMIN, min_shape);
profile->setDimensions(input_name, OptProfileSelector::kOPT, opt_shape);
profile->setDimensions(input_name, OptProfileSelector::kMAX, max_shape);
config->addOptimizationProfile(profile);
}
// 5. 生成引擎
ICudaEngine *engine = builder->buildEngineWithConfig(*network, *config);
if (!engine) {
std::cerr << "Failed to build the TensorRT engine." << std::endl;
buildCleanup(nullptr, nullptr, config, parser, network, builder);
return -1;
}
// 6. 序列化并保存 engine 文件
IHostMemory *serializedModel = engine->serialize();
if (!serializedModel) {
std::cerr << "Failed to serialize the TensorRT engine." << std::endl;
buildCleanup(nullptr, engine, config, parser, network, builder);
return -1;
}
std::ofstream engineFile(trt_model_path, std::ios::binary);
if (!engineFile) {
std::cerr << "Failed to open file for writing the TensorRT engine." << std::endl;
buildCleanup(serializedModel, engine, config, parser, network, builder);
return -1;
}
engineFile.write(reinterpret_cast<const char *>(serializedModel->data()), serializedModel->size());
engineFile.close();
// 释放资源
buildCleanup(serializedModel, engine, config, parser, network, builder);
std::cout << "TensorRT engine built and saved successfully." << std::endl;
return 0;
}
int main() {
if (!doesEngineFileExist(trt_model_path)) {
std::cout << "Engine file does not exist. Creating a new engine..." << std::endl;
if (createAndSaveTRTEngine() != 0) {
std::cout << "Failed to create and save the TensorRT engine." << std::endl;
return -1;
}
std::cout << "Engine file created successfully." << std::endl;
}
const std::vector<std::string> image_extensions = {"jpg", "jpeg", "png"};
const std::vector<std::string> video_extensions = {"mp4", "avi", "mov"};
const std::vector<std::string> camera_indexes = {"0", "1", "2"};
std::string ext = getFileExtension(input_source);
// 判断输入源的类型
bool is_image = std::find(image_extensions.begin(), image_extensions.end(), ext) != image_extensions.end();
bool is_video = std::find(video_extensions.begin(), video_extensions.end(), ext) != video_extensions.end();
bool is_directory = std::filesystem::is_directory(input_source);
bool is_camera = std::find(camera_indexes.begin(), camera_indexes.end(), input_source) != camera_indexes.end();
if (!is_camera && !std::filesystem::exists(input_source)) {
std::cerr << "Error: Input source is neither a camera nor does it exist." << std::endl;
return -1;
}
// 如果输入源是图像、视频或摄像头,则设置批次大小为1
if (is_image || is_video || is_camera) {
batch_size = 1;
std::cout << "Input source is an image/video/camera. Batch size set to " << batch_size << std::endl;
} else if (is_directory) {
// 获取目录下的所有图像集合
int total_images = getImageFilesInDirectory(input_source, image_extensions).size();
if (total_images < 1) {
std::cout << "Error: No images found in the directory: " << input_source << std::endl;
return -1;
}
if (total_images < batch_size) {
batch_size = total_images;
std::cout << "The number of images in the directory is less than batch size. Batch size set to"
<< batch_size
<< std::endl;
}
}
// 1. 加载 TensorRT 引擎
std::ifstream file(trt_model_path, std::ios::binary);
if (!file) {
std::cerr << "Failed to open engine file: " << trt_model_path << std::endl;
return -1;
}
file.seekg(0, file.end);
size_t engine_size = file.tellg();
file.seekg(0, file.beg);
char *engine_data = new char[engine_size];
file.read(engine_data, engine_size);
file.close();
// 2. 创建 TensorRT 运行时(Runtime)
TRTLogger logger;
IRuntime *runtime = createInferRuntime(logger);
if (!runtime) {
std::cerr << "Failed to create TensorRT runtime." << std::endl;
delete[] engine_data;
return -1;
}
// 3. 反序列化引擎
ICudaEngine *engine = runtime->deserializeCudaEngine(engine_data, engine_size, nullptr);
delete[] engine_data;
if (!engine) {
std::cerr << "Failed to create CUDA engine." << std::endl;
runtimeCleanup(nullptr, nullptr, nullptr, nullptr, nullptr, engine, runtime);
return -1;
}
// 4. 创建执行上下文
IExecutionContext *context = engine->createExecutionContext();
if (!context) {
std::cerr << "Failed to create execution context." << std::endl;
runtimeCleanup(nullptr, nullptr, nullptr, nullptr, context, engine, runtime);
return -1;
}
// 获取输入、输出节点的索引和名称
int input_index = -1;
int output_index = -1;
std::string input_name;
std::string output_name;
int numBindings = engine->getNbBindings();
for (int i = 0; i < numBindings; ++i) {
const char *bindingName = engine->getBindingName(i);
if (engine->bindingIsInput(i)) {
input_index = i;
input_name = bindingName;
} else {
output_index = i;
output_name = bindingName;
}
}
if (numBindings != 2 || input_index == -1 || output_index == -1) {
std::cerr << "Engine must have exactly one input and one output." << std::endl;
runtimeCleanup(nullptr, nullptr, nullptr, nullptr, context, engine, runtime);
return -1;
}
if(is_Dynamic){
// 设置动态批次
Dims input_shape = context->getBindingDimensions(input_index);
input_shape.d[0] = batch_size;
input_shape.d[1] = num_channels;
input_shape.d[2] = input_size.height;
input_shape.d[3] = input_size.width;
if (!context->setInputShapeBinding(input_index, input_shape.d)) {
std::cerr << "Failed to set input shape." << std::endl;
runtimeCleanup(nullptr, nullptr, nullptr, nullptr, context, engine, runtime);
return -1;
}
}
// 5.申请资源
// 申请 GPU 内存
void **buffers = new void *[numBindings];
cudaMalloc(&buffers[input_index], batch_size * num_channels * input_size.area() * sizeof(float));
std::vector<std::string> classes = load_classes(classes_path); // 读取类别的标签信息
int num_classes = classes.size();
int element_size = 5 + num_classes;
cv::Size output_size(num_anchors, element_size);
cudaMalloc(&buffers[output_index], batch_size * output_size.area() * sizeof(float));
// 确保分配的内存不为空
if (buffers[input_index] == nullptr || buffers[output_index] == nullptr) {
std::cerr << "Error: Failed to allocate GPU memory." << std::endl;
runtimeCleanup(nullptr, buffers, nullptr, nullptr, context, engine, runtime);
return -1;
}
// 申请主机内存
float *input_data = new float[batch_size * num_channels * input_size.area()];
float *output_data = new float[batch_size * output_size.area()];
// 黄金预处理、后处理对象
Preprocessor preprocessor(input_size, mean_, std_);
Postprocessor postprocessor(classes, input_size, num_anchors, conf_threshold, nms_threshold);
// 创建 CUDA 流
cudaStream_t stream;
if (cudaStreamCreate(&stream) != cudaSuccess) {
std::cerr << "Error: Failed to create CUDA stream." << std::endl;
runtimeCleanup(stream, buffers, input_data, output_data, context, engine, runtime);
return -1;
}
if (is_image) {
// 6. 准备输入数据(预处理)
cv::Mat image = cv::imread(input_source);
cv::Mat blob = preprocessor.process(image);
// 7. 将输入数据拷贝到 GPU
memcpy(input_data, blob.ptr<float>(), batch_size * num_channels * input_size.area() * sizeof(float));
cudaError_t cuda_status = cudaMemcpyAsync(buffers[input_index], input_data,
batch_size * input_size.area() * num_channels * sizeof(float),
cudaMemcpyHostToDevice,
stream);
if (cuda_status != cudaSuccess) {
std::cerr << "CUDA Error: " << cudaGetErrorString(cuda_status) << std::endl;
runtimeCleanup(stream, buffers, input_data, output_data, context, engine, runtime);
return -1;
}
// 8. 执行推理
if (!context->enqueueV2(buffers, stream, nullptr)) {
std::cerr << "Error: Inference failed." << std::endl;
runtimeCleanup(stream, buffers, input_data, output_data, context, engine, runtime);
return -1;
}
// 9. 获取输出结果到 Host
cuda_status = cudaMemcpy(output_data, buffers[output_index], batch_size * output_size.area() * sizeof(float),
cudaMemcpyDeviceToHost);
if (cuda_status != cudaSuccess) {
std::cerr << "CUDA Error: " << cudaGetErrorString(cuda_status) << std::endl;
runtimeCleanup(stream, buffers, input_data, output_data, context, engine, runtime);
return -1;
}
// 9. 后处理
postprocessor.process(image, output_data);
// 显示结果
cv::imshow("Result", image);
cv::waitKey();
} else if (is_camera || is_video) {
// 打开摄像头或视频文件
cv::VideoCapture cap;
if (is_camera) {
int camera_index = std::stoi(input_source);
cap.open(camera_index);
} else if (is_video) {
cap.open(input_source);
}
if (!cap.isOpened()) {
std::cerr << "Error: Failed to open camera or video file: " << input_source << std::endl;
runtimeCleanup(stream, buffers, input_data, output_data, context, engine, runtime);
return -1;
}
// 读取帧并进行处理
cv::Mat frame;
while (cap.read(frame)) {
// 预处理帧
cv::Mat blob = preprocessor.process(frame);
// 将输入数据拷贝到 GPU
memcpy(input_data, blob.ptr<float>(), batch_size * num_channels * input_size.area() * sizeof(float));
cudaError_t cuda_status = cudaMemcpyAsync(buffers[input_index], input_data,
batch_size * input_size.area() * num_channels * sizeof(float),
cudaMemcpyHostToDevice,
stream);
if (cuda_status != cudaSuccess) {
std::cerr << "CUDA Error: " << cudaGetErrorString(cuda_status) << std::endl;
runtimeCleanup(stream, buffers, input_data, output_data, context, engine, runtime);
return -1;
}
// 执行推理
if (!context->enqueueV2(buffers, stream, nullptr)) {
std::cerr << "Error: Inference failed." << std::endl;
runtimeCleanup(stream, buffers, input_data, output_data, context, engine, runtime);
return -1;
}
// 获取输出结果到 Host
cuda_status = cudaMemcpy(output_data, buffers[output_index],
batch_size * output_size.area() * sizeof(float),
cudaMemcpyDeviceToHost);
if (cuda_status != cudaSuccess) {
std::cerr << "CUDA Error: " << cudaGetErrorString(cuda_status) << std::endl;
runtimeCleanup(stream, buffers, input_data, output_data, context, engine, runtime);
return -1;
}
// 后处理
postprocessor.process(frame, output_data);
// 显示结果
cv::imshow("Result", frame);
// 等待按键,按下 'q' 退出
if (cv::waitKey(1) == 'q') {
break;
}
}
cap.release(); // 释放摄像头或视频文件
} else if (is_directory && is_Dynamic) {
std::vector<std::string> image_paths = getImageFilesInDirectory(input_source, image_extensions);
int total_images = image_paths.size();
int num_batches = total_images % batch_size ? total_images / batch_size + 1 : total_images / batch_size;
for (int i = 0; i < num_batches; ++i) {
int current_batch_size = std::min(batch_size, total_images - i * batch_size);
// 如果当前批次的大小与之前的批次不一致,需要调整输入和输出内存
if (current_batch_size != batch_size) {
// 释放原有的内存
cudaFree(buffers[input_index]);
cudaFree(buffers[output_index]);
delete[] input_data;
delete[] output_data;
// 申请新的内存
input_data = new float[current_batch_size * num_channels * input_size.area()];
output_data = new float[current_batch_size * output_size.area()];
cudaMalloc(&buffers[input_index],
current_batch_size * num_channels * input_size.area() * sizeof(float));
cudaMalloc(&buffers[output_index], current_batch_size * output_size.area() * sizeof(float));
// 设置动态批次
Dims input_shape = context->getBindingDimensions(input_index);
input_shape.d[0] = current_batch_size;
input_shape.d[1] = num_channels;
input_shape.d[2] = input_size.height;
input_shape.d[3] = input_size.width;
if (!context->setInputShapeBinding(input_index, input_shape.d)) {
std::cerr << "Failed to set input shape." << std::endl;
runtimeCleanup(nullptr, nullptr, nullptr, nullptr, context, engine, runtime);
return -1;
}
}
// 处理当前批次的图像
for (int j = 0; j < current_batch_size; ++j) {
cv::Mat image = cv::imread(image_paths[i * batch_size + j]);
cv::Mat blob = preprocessor.process(image);
// 拷贝输入数据到 GPU
memcpy(input_data + j * num_channels * input_size.area(), blob.ptr<float>(),
num_channels * input_size.area() * sizeof(float));
}
cudaError_t cuda_status = cudaMemcpyAsync(buffers[input_index], input_data,
current_batch_size * input_size.area() * num_channels * sizeof(
float),
cudaMemcpyHostToDevice, stream);
if (cuda_status != cudaSuccess) {
std::cerr << "CUDA Error: " << cudaGetErrorString(cuda_status) << std::endl;
runtimeCleanup(stream, buffers, input_data, output_data, context, engine, runtime);
return -1;
}
// 执行推理
if (!context->enqueueV2(buffers, stream, nullptr)) {
std::cerr << "Error: Inference failed." << std::endl;
runtimeCleanup(stream, buffers, input_data, output_data, context, engine, runtime);
return -1;
}
// 获取输出结果到 Host
cuda_status = cudaMemcpy(output_data, buffers[output_index],
current_batch_size * output_size.area() * sizeof(float),
cudaMemcpyDeviceToHost);
if (cuda_status != cudaSuccess) {
std::cerr << "CUDA Error: " << cudaGetErrorString(cuda_status) << std::endl;
runtimeCleanup(stream, buffers, input_data, output_data, context, engine, runtime);
return -1;
}
// 后处理并显示结果
for (int j = 0; j < current_batch_size; ++j) {
cv::Mat image = cv::imread(image_paths[i * batch_size + j]);
postprocessor.process(image, output_data + j * output_size.area());
cv::imshow("Result" + j, image);
}
cv::waitKey();
}
} else {
// 输入源类型不支持
std::cerr << "Error: Unsupported input source type: " << input_source << std::endl;
return -1;
}
// 10. 释放资源
runtimeCleanup(stream, buffers, input_data, output_data, context, engine, runtime);
return 0;
}
5.6.3 编译并运行
-
压缩并上传
首先将整个 yolov5_trt 项目打包成 zip 压缩包后,利用 FinalShell 或 WinSCP 等工具上传到 Jetson Nano 中。 -
解压并进入
然后对其进行解压 yolov5_trt.zip 压缩包进行解压,并进入解压后的目录:unzip yolov5_trt.zip cd yolov5_trt -
编译项目
进入解压后的 yolov5_trt 目录,运行以下命令来创建构建目录并编译项目:make build && cd build cmake .. make这将生成项目的可执行文件,并将资源文件复制到相应的目录中。
-
运行可执行文件
编译完成后,你可以在build/bin目录下找到生成的 yolov5_trt 可执行文件。运行它来进行模型推理:./bin/yolov5_trt这将启动 YOLOv5 模型的推理过程,处理指定的图像或视频文件。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号