LLM 学习笔记-transformers库的 PreTrainedModel 和 ModelOutput 到底是什么?
闲言碎语
我在刚开始接触 huggingface (后简称 hf) 的 transformers 库时候感觉很冗杂,比如就模型而言,有 PretrainedModel, AutoModel,还有各种 ModelForClassification, ModelForCausalLM, AutoModelForPreTraining, AutoModelForCausalLM等等;不仅如此,还设计了多到让人头皮发麻的各种 ModelOutput,比如BaseModelOutput, BaseModelOutputWithPast, CausalLMOutput等等。拥有选择困难症的我选择退出,所以之前一直没怎么用过这个大名鼎鼎的库。今天咬着牙还是决定看看源码,把这些东西搞清楚。
1. 长话短说
今天看了一下源码和官方文档,梳理过后会发现其实也不是很复杂,简单理解就两条:
ModelOutput(transformers.utils.ModelOutput)是所有模型输出的基类。简单理解它就是一个字典,在模型的forward函数里把原本的输出做了一下封装而已,方便用户能直观地知道输出是什么。例如CausalLMOutput顾名思义就是用于像 GPT 这样自回归模型的输出。PreTrainedModel(transformers.modeling_utils.PretrainedModel) 是所有模型的基类。所以你如果看到一个模型取名为LlamaForCausalLM,那你就可以知道这个模型的输出格式大概率就是自回归输出,即前面提到的CausalLMOutput。为什么说大概率呢,因为自回归输出还有蛮多种的,赶时间的朋友看到这就可以切换到其他文章了,至此你应该也能了解 transformers 最核心的模块了。感兴趣的可以继续往下看,下面做一个简单的总结和介绍。
2. 短话长说
2.1 ModelOutput
前面已经介绍过了,ModelOutput是所有模型输出的基类。下面是其源码核心部分,一些具体实现代码删除了,不过不影响理解。
可以看到 ModelOutput 其实就是一个有序的字典(OrderedDict)。
class ModelOutput(OrderedDict):
def __init_subclass__(cls) -> None:
"""
这个方法允许对 ModelOutput 的子类进行定制,使得子类在被创建时能够执行特定的操作或注册到某个系统中。
"""
...
def __init__(self, *args, **kwargs):
"""
初始化 ModelOutput 类的实例。
"""
super().__init__(*args, **kwargs)
def __post_init__(self):
"""
在初始化 ModelOutput 类的实例之后执行的操作,允许进一步对实例进行处理或设置属性。子类需要用 dataclass 装饰器
"""
...
基于 ModelOutput,hf 预先定义了 40 多种不同的 sub-class,这些类是 Hugging Face Transformers 库中用于表示不同类型模型输出的基础类,每个类都提供了特定类型模型输出的结构和信息,以便于在实际任务中对模型输出进行处理和使用。每个 sub-class 都需要用装饰器 @dataclass。我们以CausalLMOutputWithPast为例看一下源码是什么样的:
@dataclass
class CausalLMOutputWithPast(ModelOutput):
loss: Optional[torch.FloatTensor] = None
logits: torch.FloatTensor = None
past_key_values: Optional[Tuple[Tuple[torch.FloatTensor]]] = None
hidden_states: Optional[Tuple[torch.FloatTensor]] = None
attentions: Optional[Tuple[torch.FloatTensor]] = None
为了保持代码规范,我们需要在模型的forward函数中对输出结果进行封装,示例如下:
class MyModel(PretrainedModel):
def __init__(self):
self.model = ...
def forward(self, inputs, labels):
output = self.model(**inputs)
hidden_states = ...
loss = loss_fn(outputs, labels)
return CausalLMOutputWithPast(
loss=loss,
logits=logits,
past_key_values=outputs.past_key_values,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
这里简单介绍以下几种,更多的可以查看官方文档和源码:
BaseModelOutput: 该类是许多基本模型输出的基础,包含模型的一般输出,如 logits、hidden_states 等。BaseModelOutputWithNoAttention: 在模型输出中不包含注意力(attention)信息。BaseModelOutputWithPast: 包含过去隐藏状态的模型输出,适用于能够迭代生成文本的模型,例如语言模型。BaseModelOutputWithCrossAttentions: 在模型输出中包含交叉注意力(cross attentions)信息,通常用于特定任务中需要跨注意力的情况,比如机器翻译。BaseModelOutputWithPastAndCrossAttentions: 同时包含过去隐藏状态和交叉注意力的模型输出。MoEModelOutput: 包含混合专家模型(Mixture of Experts)输出的模型。MoECausalLMOutputWithPast: 混合专家语言模型的输出,包括过去隐藏状态。Seq2SeqModelOutput: 序列到序列模型输出的基类,适用于需要生成序列的模型。CausalLMOutput: 用于生成式语言模型输出的基础类,提供生成文本的基本信息。CausalLMOutputWithPast: 生成式语言模型输出的类,包含过去隐藏状态,用于连续生成文本的模型。
2.2 PretraiedModel
PreTrainedModel 是 Hugging Face Transformers 库中定义预训练模型的基类。它继承了 nn.Module,同时混合了几个不同的 mixin 类,如 ModuleUtilsMixin、GenerationMixin、PushToHubMixin 和 PeftAdapterMixin。这个基类提供了创建和定义预训练模型所需的核心功能和属性。
以下是 PreTrainedModel 中的部分代码:
class PreTrainedModel(nn.Module, ModuleUtilsMixin, GenerationMixin, PushToHubMixin, PeftAdapterMixin):
config_class = None
base_model_prefix = ""
main_input_name = "input_ids"
_auto_class = None
_no_split_modules = None
_skip_keys_device_placement = None
_keep_in_fp32_modules = None
...
def __init__(self, config: PretrainedConfig, *inputs, **kwargs):
super().__init__()
...
在这个基类中,我们可以看到一些重要的属性和方法:
config_class:指向特定预训练模型类的配置文件,用于定义模型的配置。base_model_prefix:基本模型前缀,在模型的命名中使用,例如在加载预训练模型的权重时使用。main_input_name:指定模型的主要输入名称,通常是 input_ids。_init_weights方法:用于初始化模型权重的方法。
在这个基类中,大多数属性都被定义为 None 或空字符串,这些属性在具体的预训练模型类中会被重写或填充。接下来我们将看到如何使用 PretrainedModel 类定义 llama 模型。
class LlamaPreTrainedModel(PreTrainedModel):
config_class = LlamaConfig
base_model_prefix = "model"
supports_gradient_checkpointing = True
_no_split_modules = ["LlamaDecoderLayer"]
_skip_keys_device_placement = "past_key_values"
_supports_flash_attn_2 = True
def _init_weights(self, module):
std = self.config.initializer_range
if isinstance(module, nn.Linear):
module.weight.data.normal_(mean=0.0, std=std)
if module.bias is not None:
module.bias.data.zero_()
elif isinstance(module, nn.Embedding):
module.weight.data.normal_(mean=0.0, std=std)
if module.padding_idx is not None:
module.weight.data[module.padding_idx].zero_()
在这个例子中,首先定义了 LlamaPreTrainedModel 类作为 llama 模型的基类,它继承自 PreTrainedModel。在这个基类中,我们指定了一些 llama 模型特有的属性,比如配置类 LlamaConfig、模型前缀 model、支持梯度检查点(gradient checkpointing)、跳过的模块列表 _no_split_modules 等等。
然后,我们基于这个基类分别定义了 LlamaModel、LlamaForCausalLM 和 LlamaForSequenceClassification。这些模型的逻辑关系如下图所示:
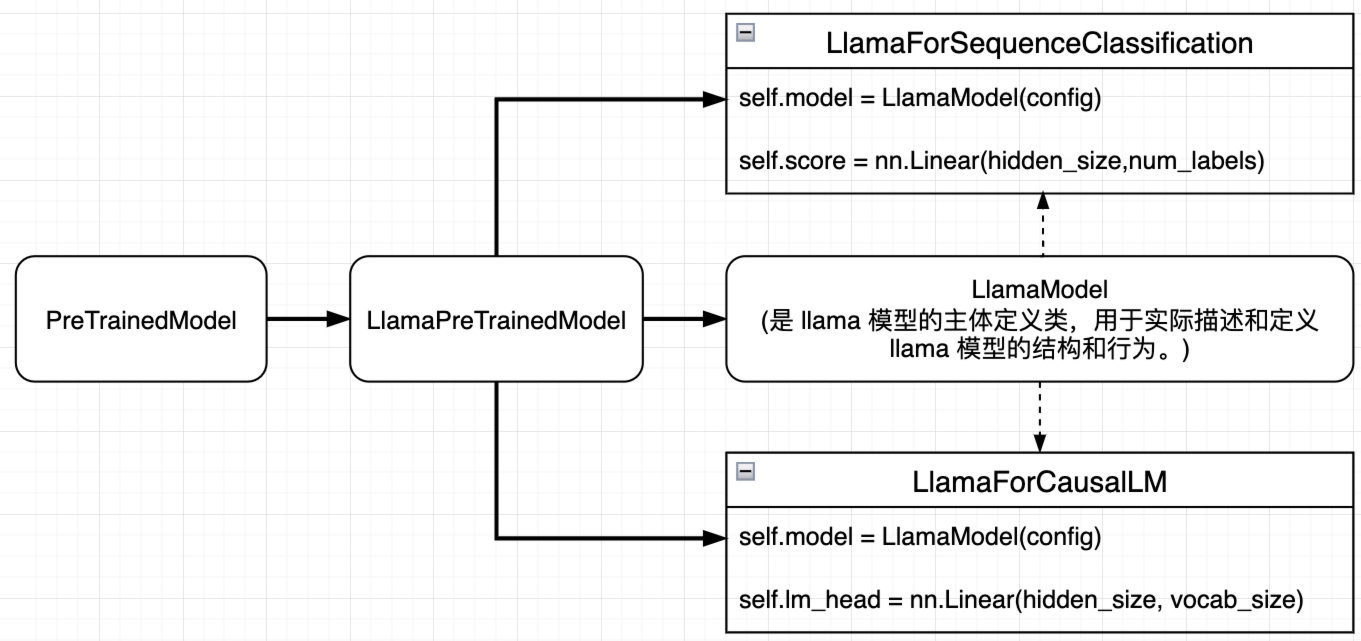
LlamaModel是 llama 模型的主体定义类,也就是我们最常见的普pytorch 定义模型的方法、默认的输出格式为BaseModelOutputWithPast;
class LlamaModel(LlamaPreTrainedModel):
def __init__(self, config: LlamaConfig):
super().__init__(config)
self.padding_idx = config.pad_token_id
self.vocab_size = config.vocab_size
self.embed_tokens = nn.Embedding(config.vocab_size, config.hidden_size, self.padding_idx)
self.layers = nn.ModuleList([LlamaDecoderLayer(config) for _ in range(config.num_hidden_layers)])
self.norm = LlamaRMSNorm(config.hidden_size, eps=config.rms_norm_eps)
...
def forward(self, ...):
...
return BaseModelOutputWithPast(...)
LlamaForCausalLM适用于生成式语言模型的 llama 模型,可以看到 backbone 就是LlamaModel,增加了lm_head作为分类器,输出长度为词汇表达大小,用来预测下一个单词。输出格式为CausalLMOutputWithPast;
class LlamaForCausalLM(LlamaPreTrainedModel):
# 适用于生成式语言模型的 Llama 模型定义
def __init__(self, config):
super().__init__(config)
self.model = LlamaModel(config)
self.vocab_size = config.vocab_size
self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
...
def forward(self, ...):
outputs = self.model(...)
... # 后处理 outputs,以满足输出格式要求
return CausalLMOutputWithPast(...)
LlamaForSequenceClassification适用于序列分类任务的 llama 模型,同样把LlamaModel作为 backbone, 不过增加了score作为分类器,输出长度为 label 的数量,用来预测类别。输出格式为SequenceClassifierOutputWithPast
class LlamaForSequenceClassification(LlamaPreTrainedModel):
# 适用于序列分类任务的 Llama 模型定义
def __init__(self, config):
super().__init__(config)
self.num_labels = config.num_labels
self.model = LlamaModel(config)
self.score = nn.Linear(config.hidden_size, self.num_labels, bias=False)
...
def forward(self, ...):
outputs = self.model(...)
... # 后处理 outputs,以满足输出格式要求
return SequenceClassifierOutputWithPast(...)
每个子类根据特定的任务或应用场景进行了定制,以满足不同任务的需求。另外可以看到 hf 定义的模型都是由传入的 config参数定义的,所以不同模型对应不同的配置啦,这也是为什么我们经常能看到有像 BertConfig,GPTConfig这些预先定义好的类。例如我们可以很方便地通过指定的字符串或者文件获取和修改不同的参数配置:
config = BertConfig.from_pretrained(
"bert-base-uncased"
) # Download configuration from huggingface.co and cache.
config = BertConfig.from_pretrained(
"./test/saved_model/"
) # E.g. config (or model) was saved using *save_pretrained('./test/saved_model/')*
config = BertConfig.from_pretrained("./test/saved_model/my_configuration.json")
config = BertConfig.from_pretrained("bert-base-uncased", output_attentions=True, foo=False)
hf 为了造福懒人,提供了更加简便的 API,即 Auto 系列 API。至于有多简便,看看下面的 demo 就知道了:
from transformers import AutoConfig, AutoModel
# Download configuration from huggingface.co and cache.
config = AutoConfig.from_pretrained("bert-base-cased")
model = AutoModel.from_config(config)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号