FlashAttention算法简介
1. Motivation
不同硬件模块之间的带宽和存储空间有明显差异,例如下图中左边的三角图,最顶端的是GPU种的SRAM,它的容量非常小但是带宽非常大,以A100 GPU为例,它有108个流式多核处理器,每个处理器上的片上SRAM大小只有192KB,因此A100总共的SRAM大小是192KB$\times\(108\)\approx$20MB,但是其吞吐量能高达19TB/s。而A100 GPU HBM(High Bandwidth Memory也就是我们常说的GPU显存大小)大小在40GB~80GB左右,但是带宽只与1.5TB/s。
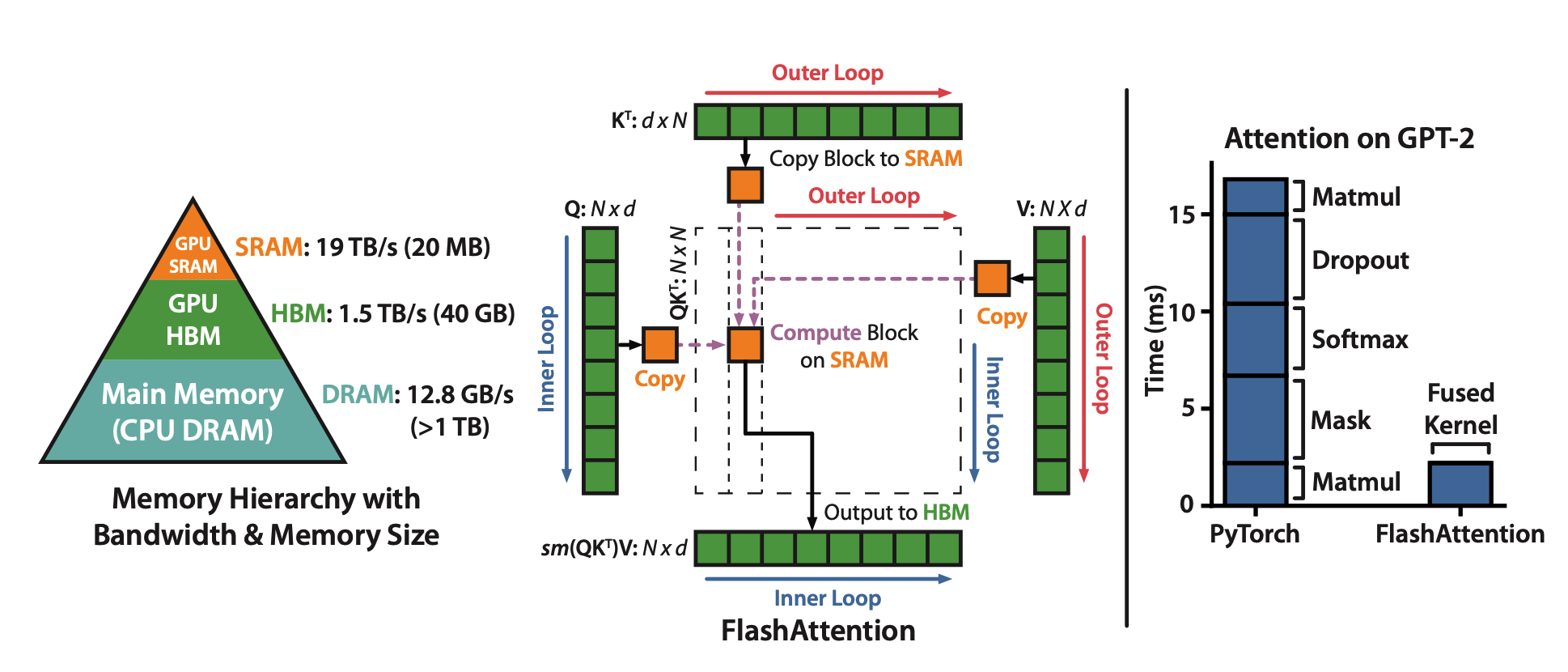
下图给出了标准的注意力机制的实现流程,可以看到因为HBM的大小更大,我们平时写pytorch代码的时候最常用到的就是HBM,所以对于HBM的读写操作非常频繁,而SRAM利用率反而不高。

FlashAttention的主要动机就是希望把SRAM利用起来,但是难点就在于SRAM太小了,一个普通的矩阵乘法都放不下去。FlashAttention的解决思路就是将计算模块进行分解,拆成一个个小的计算任务。
2. Softmax Tiling
在介绍具体的计算算法前,我们首先需要了解一下Softmax Tiling。
- 数值稳定: Softmax包含指数函数,所以为了避免数值溢出问题,可以将每个元素都减去最大值,如下图示,最后计算结果和原来的Softmax是一致的。
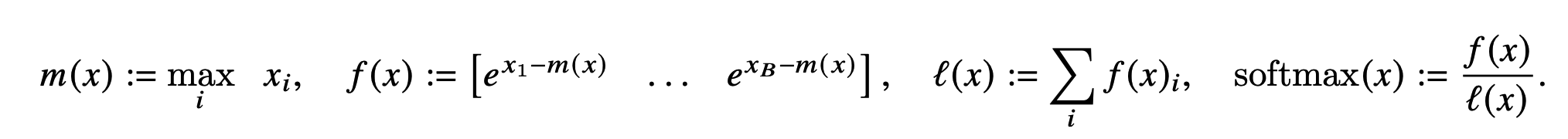
2. 分块计算Softmax
因为Softmax都是按行计算的,所以我们考虑一行切分成两部分的情况,即原本的一行数据\(x\in\mathbb{R}^{2B}=[x^{(1)},x^{(2)}]\)。
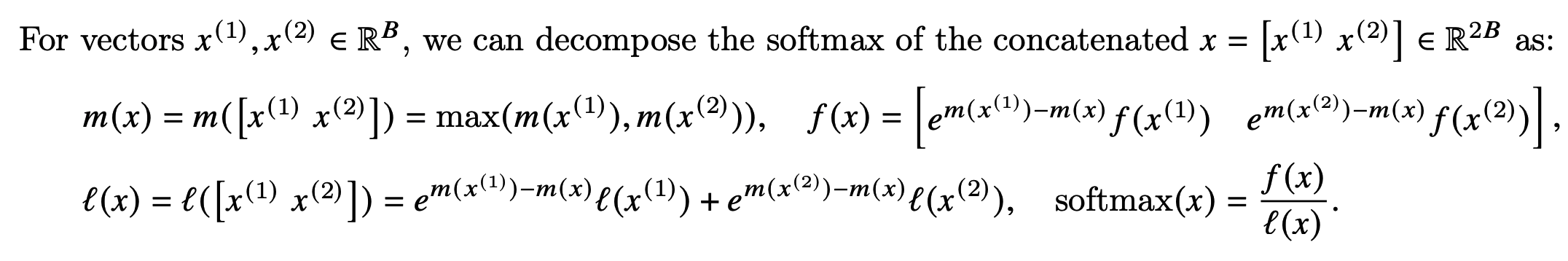
可以看到计算不同块的f(x)值时,乘上的系数是不同的,但是最后化简后的结果都是指数函数减去了整行的最大值。以\(x^{(1)}\)为例,
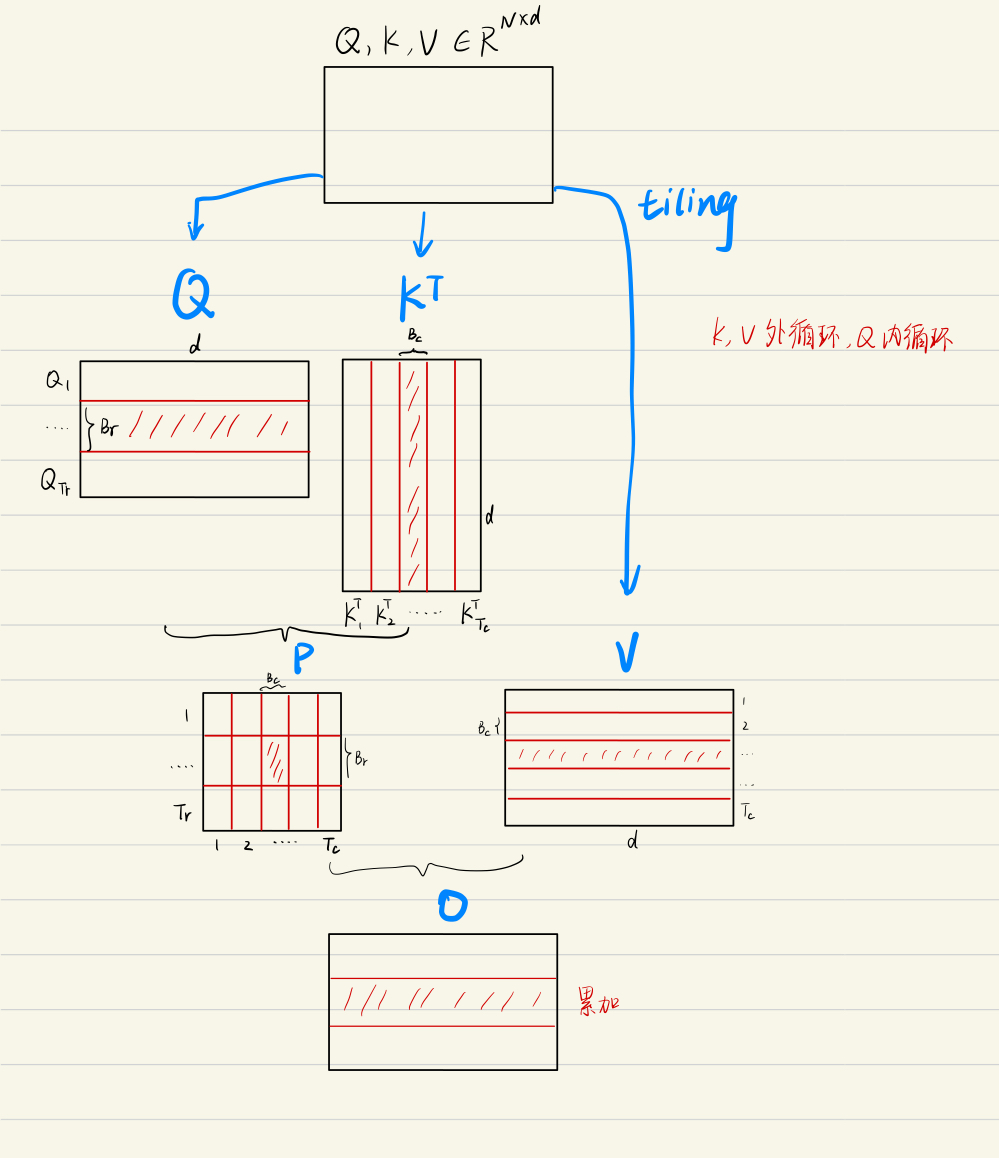
3. FlashAttention算法流程
FlashAttention算法流程如下图所示

为方便理解,下图将FlashAttention的计算流程可视化出来了,简单理解就是每一次只计算一个block的值,通过多轮的双for循环完成整个注意力的计算。
下面是FlashAttention的代码实现,参考自https://github.com/shreyansh26/FlashAttention-PyTorch/tree/master
import torch
import torch.nn as nn
import numpy as np
import sys
import time
from einops import rearrange
BLOCK_SIZE = 1024
NEG_INF = -1e10 # -infinity
EPSILON = 1e-10
def normal_attention_causal(Q, K, V):
scale = 1 / np.sqrt(Q.shape[-1])
Q = Q * scale
QKt = torch.einsum('... i d, ... j d -> ... i j', Q, K)
Q_LEN = Q.shape[2]
K_LEN = K.shape[2]
causal_mask = torch.triu(torch.ones((Q_LEN, K_LEN)), K_LEN - Q_LEN + 1)
causal_mask = causal_mask.to(device='cuda')
QKt = torch.where(causal_mask > 0, NEG_INF, QKt)
attn = nn.functional.softmax(QKt, dim=-1)
return attn @ V
def flash_attention_causal_forward(Q, K, V):
O = torch.zeros_like(Q, requires_grad=True)
l = torch.zeros(Q.shape[:-1])[...,None]
m = torch.ones(Q.shape[:-1])[...,None] * NEG_INF
O = O.to(device='cuda')
l = l.to(device='cuda')
m = m.to(device='cuda')
Q_BLOCK_SIZE = min(BLOCK_SIZE, Q.shape[-1])
KV_BLOCK_SIZE = BLOCK_SIZE
Q_BLOCKS = torch.split(Q, Q_BLOCK_SIZE, dim=2)
K_BLOCKS = torch.split(K, KV_BLOCK_SIZE, dim=2)
V_BLOCKS = torch.split(V, KV_BLOCK_SIZE, dim=2)
Tr = len(Q_BLOCKS)
Tc = len(K_BLOCKS)
O_BLOCKS = list(torch.split(O, Q_BLOCK_SIZE, dim=2))
l_BLOCKS = list(torch.split(l, Q_BLOCK_SIZE, dim=2))
m_BLOCKS = list(torch.split(m, Q_BLOCK_SIZE, dim=2))
Q_LEN = Q.shape[2]
K_LEN = K.shape[2]
Q_RANGE = torch.arange(Q_LEN)[:,None] + (K_LEN - Q_LEN)
K_RANGE = torch.arange(K_LEN)[None,:]
Q_RANGE = Q_RANGE.to(device='cuda')
K_RANGE = K_RANGE.to(device='cuda')
Q_RANGE_BLOCKS = torch.split(Q_RANGE, Q_BLOCK_SIZE, dim=0)
K_RANGE_BLOCKS = torch.split(K_RANGE, KV_BLOCK_SIZE, dim=1)
for j in range(Tc):
Kj = K_BLOCKS[j]
Vj = V_BLOCKS[j]
K_RANGE_BLOCKSj = K_RANGE_BLOCKS[j]
for i in range(Tr):
Qi = Q_BLOCKS[i]
Oi = O_BLOCKS[i]
li = l_BLOCKS[i]
mi = m_BLOCKS[i]
Q_RANGE_BLOCKSi = Q_RANGE_BLOCKS[i]
scale = 1 / np.sqrt(Q.shape[-1])
Qi_scaled = Qi * scale
S_ij = torch.einsum('... i d, ... j d -> ... i j', Qi_scaled, Kj)
# Masking
causal_mask = Q_RANGE_BLOCKSi >= K_RANGE_BLOCKSj
S_ij = torch.where(causal_mask > 0, S_ij, NEG_INF)
m_block_ij, _ = torch.max(S_ij, dim=-1, keepdims=True)
P_ij = torch.exp(S_ij - m_block_ij)
# Masking
P_ij = torch.where(causal_mask > 0, P_ij, 0)
l_block_ij = torch.sum(P_ij, dim=-1, keepdims=True) + EPSILON
P_ij_Vj = torch.einsum('... i j, ... j d -> ... i d', P_ij, Vj)
mi_new = torch.maximum(m_block_ij, mi)
li_new = torch.exp(mi - mi_new) * li + torch.exp(m_block_ij - mi_new) * l_block_ij
O_BLOCKS[i] = (li/li_new) * torch.exp(mi - mi_new) * Oi + (torch.exp(m_block_ij - mi_new) / li_new) * P_ij_Vj
l_BLOCKS[i] = li_new
m_BLOCKS[i] = mi_new
O = torch.cat(O_BLOCKS, dim=2)
l = torch.cat(l_BLOCKS, dim=2)
m = torch.cat(m_BLOCKS, dim=2)
return O, l, m
def flash_attention_causal_backward(Q, K, V, O, l, m, dO):
Q_BLOCK_SIZE = min(BLOCK_SIZE, Q.shape[-1])
KV_BLOCK_SIZE = BLOCK_SIZE
Q_BLOCKS = torch.split(Q, Q_BLOCK_SIZE, dim=2)
K_BLOCKS = torch.split(K, KV_BLOCK_SIZE, dim=2)
V_BLOCKS = torch.split(V, KV_BLOCK_SIZE, dim=2)
Tr = len(Q_BLOCKS)
Tc = len(K_BLOCKS)
O_BLOCKS = list(torch.split(O, Q_BLOCK_SIZE, dim=2))
dO_BLOCKS = list(torch.split(dO, Q_BLOCK_SIZE, dim=2))
l_BLOCKS = list(torch.split(l, Q_BLOCK_SIZE, dim=2))
m_BLOCKS = list(torch.split(m, Q_BLOCK_SIZE, dim=2))
dQ = torch.zeros_like(Q, requires_grad=True).to(device='cuda')
dK = torch.zeros_like(K, requires_grad=True).to(device='cuda')
dV = torch.zeros_like(V, requires_grad=True).to(device='cuda')
dQ_BLOCKS = list(torch.split(dQ, Q_BLOCK_SIZE, dim=2))
dK_BLOCKS = list(torch.split(dK, KV_BLOCK_SIZE, dim=2))
dV_BLOCKS = list(torch.split(dV, KV_BLOCK_SIZE, dim=2))
Q_LEN = Q.shape[2]
K_LEN = K.shape[2]
Q_RANGE = torch.arange(Q_LEN)[:,None] + (K_LEN - Q_LEN)
K_RANGE = torch.arange(K_LEN)[None,:]
Q_RANGE = Q_RANGE.to(device='cuda')
K_RANGE = K_RANGE.to(device='cuda')
Q_RANGE_BLOCKS = torch.split(Q_RANGE, Q_BLOCK_SIZE, dim=0)
K_RANGE_BLOCKS = torch.split(K_RANGE, KV_BLOCK_SIZE, dim=1)
for j in range(Tc):
Kj = K_BLOCKS[j]
Vj = V_BLOCKS[j]
K_RANGE_BLOCKSj = K_RANGE_BLOCKS[j]
dKj_block = torch.zeros_like(dK_BLOCKS[j], requires_grad=True).to(device='cuda')
dVj_block = torch.zeros_like(dV_BLOCKS[j], requires_grad=True).to(device='cuda')
for i in range(Tr):
Qi = Q_BLOCKS[i]
Oi = O_BLOCKS[i]
dOi = dO_BLOCKS[i]
li = l_BLOCKS[i]
mi = m_BLOCKS[i]
Q_RANGE_BLOCKSi = Q_RANGE_BLOCKS[i]
scale = 1 / np.sqrt(Q.shape[-1])
Qi_scaled = Qi * scale
S_ij = torch.einsum('... i d, ... j d -> ... i j', Qi_scaled, Kj)
# Masking
causal_mask = Q_RANGE_BLOCKSi >= K_RANGE_BLOCKSj
S_ij = torch.where(causal_mask > 0, S_ij, NEG_INF)
P_ij = (1/li) * torch.exp(S_ij - mi)
# Masking
P_ij = torch.where(causal_mask > 0, P_ij, 0)
dVj_block = dVj_block + torch.einsum('... r c, ... r d -> ... c d', P_ij, dOi)
dP_ij = torch.einsum('... r d, ... c d -> ... r c', dOi, Vj)
Di = torch.sum(dOi * Oi, dim=-1, keepdims=True)
dS_ij = P_ij * (dP_ij - Di)
dQ_BLOCKS[i] = dQ_BLOCKS[i] + scale * torch.einsum('... r c, ... c d -> ... r d', dS_ij, Kj)
dKj_block = dKj_block + scale * torch.einsum('... r c, ... r d -> ... c d', dS_ij, Qi)
dK_BLOCKS[j] = dKj_block
dV_BLOCKS[j] = dVj_block
dQ = torch.cat(dQ_BLOCKS, dim=2)
dK = torch.cat(dK_BLOCKS, dim=2)
dV = torch.cat(dV_BLOCKS, dim=2)
return dQ, dK, dV
def flash_attention_causal(Q, K, V):
out = flash_attention_causal_forward(Q, K, V)
return out[0]
if __name__ == "__main__":
Q = torch.randn(1, 2, 4096, 1024, requires_grad=True).to(device='cuda')
K = torch.randn(1, 2, 4096, 1024, requires_grad=True).to(device='cuda')
V = torch.randn(1, 2, 4096, 1024, requires_grad=True).to(device='cuda')
for i in range(10):
start1 = time.time_ns()
out1 = flash_attention_causal(Q, K, V)
end1 = time.time_ns()
start2 = time.time_ns()
out2 = normal_attention_causal(Q, K, V)
end2 = time.time_ns()
t1 = (end1 - start1) / 1000000
t2 = (end2 - start2) / 1000000
print(f'{t1}ms, {t2}ms')
print(torch.allclose(out1, out2, atol=1e-5))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号