

大数据之路:阿里巴巴大数据实践——离线数据开发
数据开发平台
统一计算平台
-
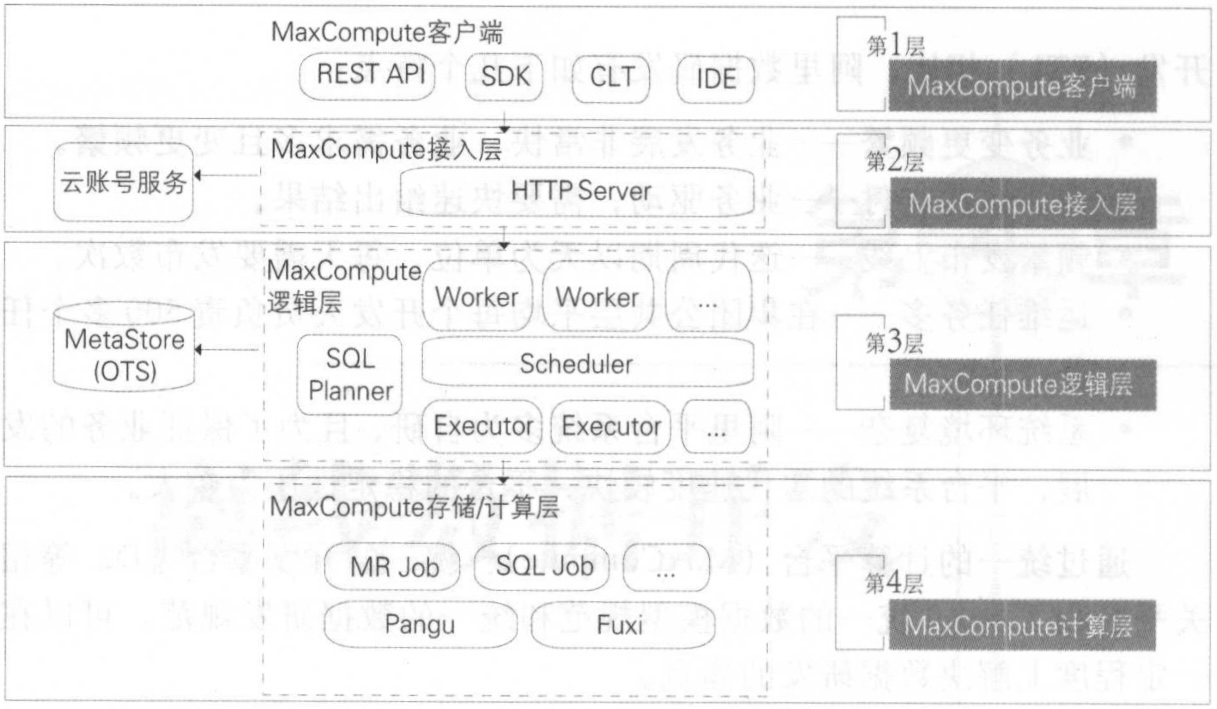
MaxCompute:主要服务于海量数据的存储和计算 ,提供完善的数据导入方案, 以及多种经典的分布式计算模型,提供海量数据仓库的解决方案,能够更快速地解决用户的海量数据计算问题,有效降低企业成本,并保障数据安全。
-
MaxCompute客户端:包括Web、SDK、CLT、IDE等形式完成 Project 管理、数据同步、任务调度、报表生成等常见操作。
-
MaxCompute接入层:提供HTTP服务、Cache、负载均衡,实现用户认证和服务层面的访问控制。
-
MaxCompute控制层:实现用户空间和对象的管理、命令的解析与执行逻辑、数据对象的访问控制与授权等功能。
Worker:处理所有的RESTful 请求,包括用户空间( Project )管理操作、资源( Resource) 管理操作、作业管理等;对于 SQL DML、MR 等需要启动 MapReduce 的作业,会生成 MaxCompute Instance 提交给 Scheduler 一步处理。
Scheduler:负责MaxCompute Instance的调度和拆解,并向计算层的计算集群询问资源占用情况以进行流控。
Executor:负责 MaxCompute Instance 的执行,向计算层的计算集群提交真正的计算任务。
-
MaxCompute计算层:包括分布式文件系统(Pangu)、资源调度系统(Fuxi)、NameSpace服务、监控模块。
-
MaxCompute元数据:主要包括用户空间元数据、 Table Partition Schema、ACL、Job 元数据、安全体系等。
-
MaxCompute架构
![image-20250720144935336]()
统一开放平台
-
D2:集成任务开发、调试及发布,生产任务调度及大数据运维,数据权限申请及管理等功能的一站式数据开发平台。
-
Dataworks:核心功能与D2一致,D2服务与阿里集团内部业务,Dataworks则为阿里云对外商业化大数据开发治理平台。
-
SQLSCAN:在任务开发中用户编写的SQL质量差、性能低、不遵守规范等问题,总结成规范,通过系统及研发流程保障。
代码规范类规则:表命名规范、生命周期设置、表注释等。
代码质量类规则:调度参数使用检查、分母为 提醒、 NULL 值参与计算影响结果提醒、插入字段顺序错误等。
代码性能类规则:分区裁剪失效、扫描大表提醒、重复计算检测等。
-
DQC:主要关注数据质量, 通过配置数据质量校验规则,自动在数据处理任务过程中进行数据质量方面的监控。
数据监控:监控数据质量并报警,其本身不对数据产出进行处理,需要报警接收人判断并决定如何处理。
数据清洗:将不符合既定规则的数据清洗掉,以保证最终数据产出不含“脏数据”,数据清洗不会触发报警。
监控规则:主键监控、表数据量及波动监控、重要字段的非空监控、重要枚举宇段的离散值监控、 指标值波动监控等。
任务调度系统
核心设计模型
- 调度引擎:根据任务节点属性及依赖关系进行实例化, 生成各类参数的实值,并生成调度树。
- 执行引擎:根据调度引擎生成的具体任务实例和配置信息,分配 CPU 内存、运行节点等资源,在任务对应的环境中运行代码。
任务状态机模型
-
预备阶段:WAITING_DEPENDENCY → READY → WAITING_RESOURCE
-
执行阶段:RUNNING(核心处理节点)
-
终态阶段:SUCCESS/KILLED/SUSPENDED
-
异常回路:FAILED ⇄ WAITING_RETRY
stateDiagram-v2 direction LR [*] --> WAITING_DEPENDENCY : 任务创建 WAITING_DEPENDENCY --> READY : 上游依赖满足 READY --> WAITING_RESOURCE : 提交执行请求 WAITING_RESOURCE --> RUNNING : 资源分配完成 RUNNING --> SUCCESS : 执行成功 RUNNING --> FAILED : 执行异常 RUNNING --> KILLING : 用户主动终止 FAILED --> WAITING_RETRY : 重试次数未耗尽 WAITING_RETRY --> READY : 到达重试时间 FAILED --> SUSPENDED : 重试次数耗尽 KILLING --> KILLED : 终止完成 SUCCESS --> [*] : 生命周期结束 KILLED --> [*] : 生命周期结束 SUSPENDED --> READY : 人工干预恢复 SUSPENDED --> [*] : 人工确认终止 note right of WAITING_DEPENDENCY 核心依赖检查: 1. 父任务状态(成功/跳过) 2. 跨周期依赖满足 3. 数据分区就绪 4. 业务日期有效性 end note note left of RUNNING 执行引擎交互: - 启动计算引擎(MaxCompute/Hive/Spark) - 实时监控资源水位 - 进度心跳检测(超时自动失败) - 日志实时采集 end note note right of WAITING_RETRY 智能重试策略: 1. 指数退避时间(5s→10s→30s→1m) 2. 资源不足时自动扩容 3. 节点故障自动转移 4. 环境异常自动隔离 end note
工作流状态机模型
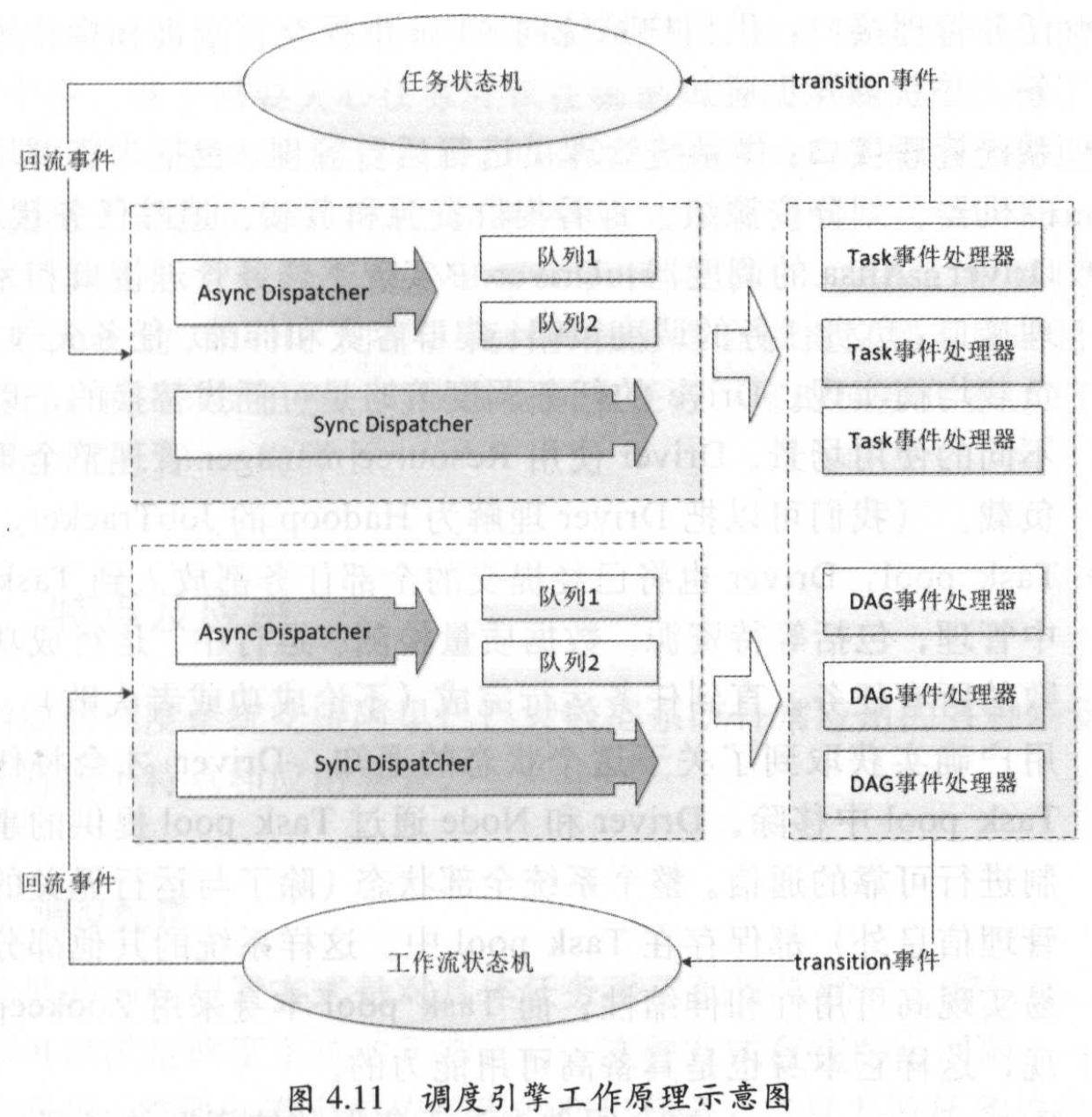
调度引擎工作原理
- Async Dispatcher:异步处理任务调度。
- Sync Dispatcher:同步处理任务调度。
- Task 事件处理器:任务事件处理器,与任务状态机交互。
- DAG 事件处理器:工作流事件处理器,与工作流状态机交互,一个DAG 事件处理器包含若干个 Task 事件处理器。
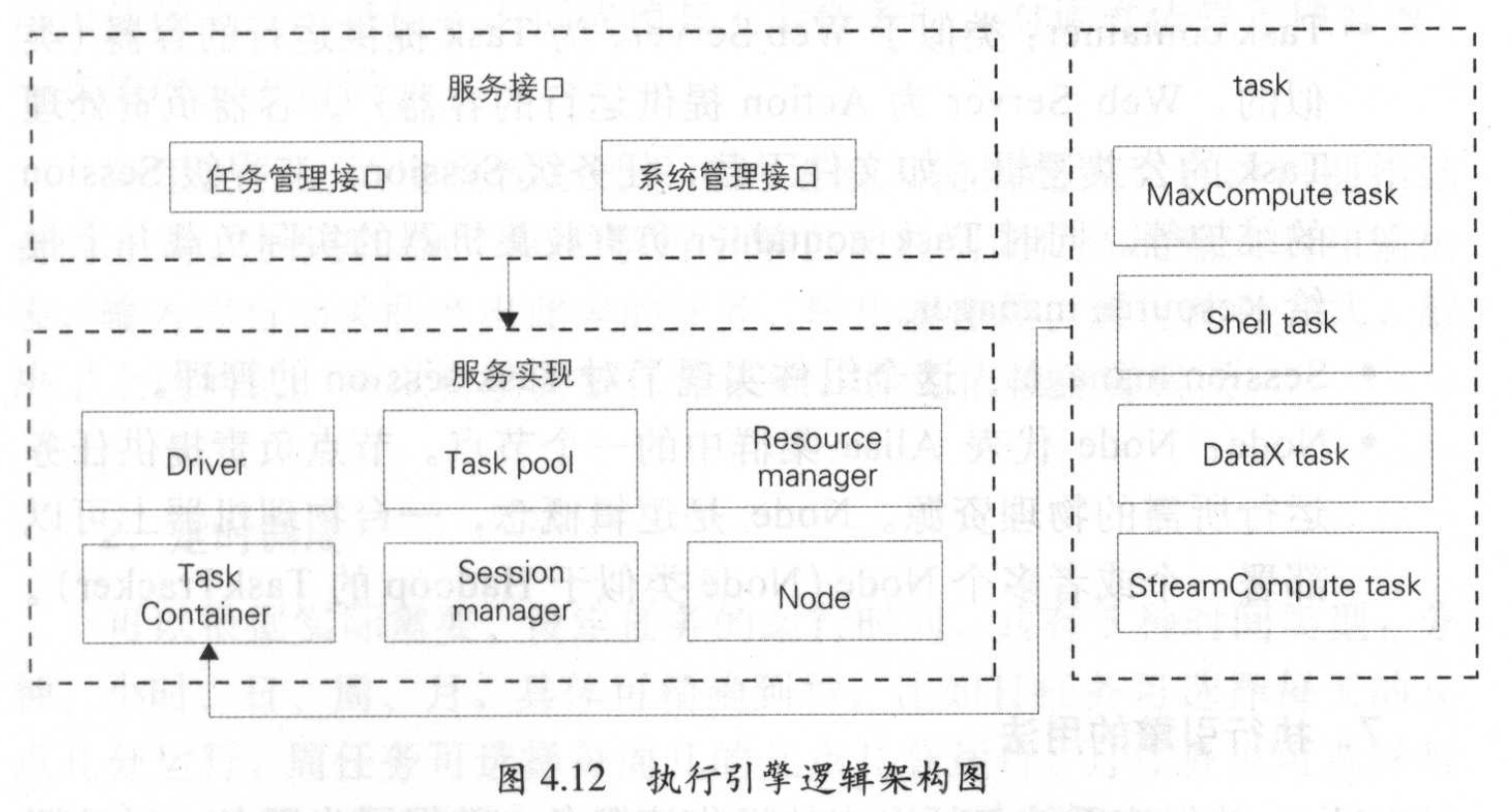
执行引擎工作原理
- 任务管理接口:供用户系统向 Alisa 中提交、查询和操作离线任 务,并获得异步通知。
- 系统管理接口:供系统管理员进行后台管理,包括为集群增加新 的机器、划分资源组、查看集群资源和负载、追踪任务状态等。
- Driver:中实现了任务管理接口和系统管理接口;负责任务的调度策略、集群容灾和伸缩、任务失效备援、 负载均衡实现。
- Task pool:已经提交的任务放入到 Task pool 中管理,包括等待资源、数据质量检测、运行中、运行成功和失败的所有任务。
- Resource manager:组件专注于集群整体资源的管理。
- Task container:容器负责处理 Task 的公共逻辑,如文件下载,任务级 Session 、流程级 Session 的维护等。
- Session manager :组件实现了对 Task session 的管理。
- Node:Node节点负责提供任务运行所需的物理资源,Node 是逻辑概念, 一台物理机器上可部署一个或者多个 Node。
任务调度系统应用
- 调度配置:任务提交时, SQL 解析引擎自动识别此任务的输入表和输出 表,输入表自动关联产出此表的任务 ,输出表亦然。
- 定时调度:可以根据实际需要,设定任务的运行时间,共有5种时间类型:分钟、小时、日、周、月,具体可精确到秒。
- 周期调度:可按照小时、日等时间周期运行任务,与定时调度的区别是无须指定具体的开始运行时间。
- 手动运行:当生产环境数据修复或临时数据操作时,在开发环境中写好脚本后发布到生产环境,再通过手动触发运行。
- 基线管理:基于充分利用计算资源,保证重点业务数据优先产出,合理安排各类优先级任务的运行。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号