spark的json数据的读取和保存
1) spark可以读取很多种数据格式,spark.read.按tab键表示显示:
scala>spark.read.
csv format jdbc json load option options orc parquet schema table text textFile
2) spark.read.format("json")方式读取json文件
scala> spark.read.format("json").load("file:///opt/module/data/input/2.json")
res0: org.apache.spark.sql.DataFrame = [age: bigint, name: string]
scala> spark.read.format("json").load("file:///opt/module/data/input/2.json").show
+---+--------+
|age| name|
+---+--------+
| 20|zhangsan|
| 20| lisi|
| 20| wangwu|
+---+--------+
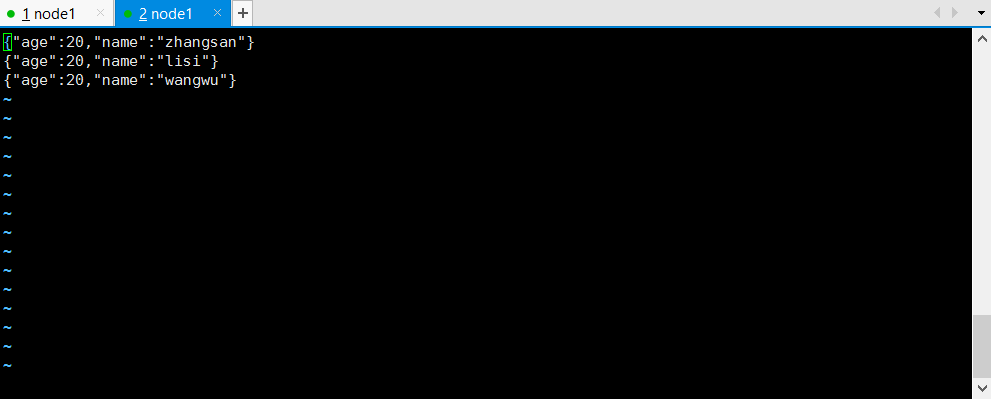
3)上面的方式等同于这种方式 直接spark.read.json
scala> spark.read.json("file:///opt/module/data/input/2.json")
res3: org.apache.spark.sql.DataFrame = [age: bigint, name: string]
scala> spark.read.json("file:///opt/module/data/input/2.json").show
+---+--------+
|age| name|
+---+--------+
| 20|zhangsan|
| 20| lisi|
| 20| wangwu|
+---+--------+
4)因为spark.read.load 默认获取parquet格式文件,所以需要特别关注一下这个点。
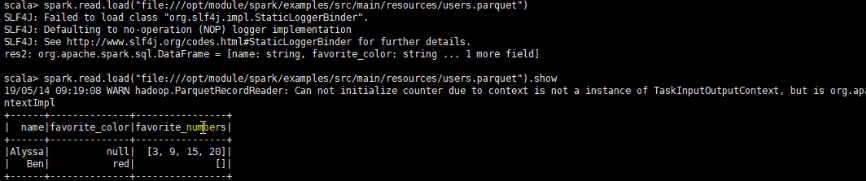
2.1) spark 写数据的方法最直接的常用方式是df一下,因为得有数据,之前啥也没有,所以需要用df来保存
scala> val df = spark.read.json("file:///opt/module/data/input/2.json")
df: org.apache.spark.sql.DataFrame = [age: bigint, name: string]
2)使用df.write.save 加路径就可以了。
scala> df.write.save("file:///opt/module/data/output/one")
SLF4J: Failed to load class "org.slf4j.impl.StaticLoggerBinder".
SLF4J: Defaulting to no-operation (NOP) logger implementation
SLF4J: See http://www.slf4j.org/codes.html#StaticLoggerBinder for further details.
3)这是可以进入/opt/module/data/output/one看一下保存的什么东西
[root@hadoop1 one]# ll
total 4
-rw-r--r-- 1 root root 598 Oct 9 03:01 part-00000-555473fa-02fd-4cda-b5f7-07eb40c4a889.snappy.parquet
-rw-r--r-- 1 root root 0 Oct 9 03:01 _SUCCESS
你会发现保存的就是默认parquet文件

4) 但是,默认parquet的格式不是我想要的,那我应该format一下格式,放在新的文件夹里面output/two即可,注意一旦还放one里面的话,他会提示你已经存在了的错误。
scala> df.write.format("json")save("file:///opt/module/data/output/two")
drwxr-xr-x 2 root root 168 Oct 9 03:09 two
[root@hadoop1 output]# cd two
[root@hadoop1 two]# ll
total 4
-rw-r--r-- 1 root root 81 Oct 9 03:09 part-00000-aea3fbd5-8ec7-46d2-90a5-4330ac35fa24.json
-rw-r--r-- 1 root root 0 Oct 9 03:09 _SUCCESS
[root@hadoop1 two]#
5)接着上面的为什么要系统在建一个文件夹,但是我们公司需要保存的文件放在一个类别就放一个夹子里面。这里就涉及到保存的模式mode问题了,你给他你个mode()参数就可以了。
scala> df.write.format("json").mode("append").save("file:///opt/module/data/output/two")
这里可以说是append追加方式,还有更多saveMode详细介绍如下
scala/Java Any Language Meaning
SaveMode.ErrorIfExists(default默认方式) "error"(给报错) 如果文件存在,则报错
SaveMode.Append ““append” 下面追加
SaveMode.Overwrite "overwrite" 覆盖写入
SaveMode.Ignore "ignore" 数据存在,则忽略
我们如果重复操作append的话,结果是两个。
[root@hadoop1 two]# ll
total 8
-rw-r--r-- 1 root root 81 Oct 9 03:29 part-00000-4a2c0712-ad48-4ca5-ae39-6eb0ee94bd42.json
-rw-r--r-- 1 root root 81 Oct 9 03:31 part-00000-f35ef5bf-e1e5-4262-893f-44a8d0ce9080.json
-rw-r--r-- 1 root root 0 Oct 9 03:31 _SUCCESS


 浙公网安备 33010602011771号
浙公网安备 33010602011771号