零基础爬取堆糖网图片(一)
零基础爬取堆糖网图片(一)
全文介绍:
首先堆糖网是一个美图壁纸兴趣社区,有大量的美女图片
今天我们实现搜索关键字爬取堆糖网上相关的美图。
当然我们还可以实现多线程爬虫,加快爬虫爬取速度

涉及内容:
- 爬虫基本流程
- requests库基本使用
- urllib.parse模块
- json包
- jsonpath库
图例说明:
- 请求与响应
sequenceDiagram
浏览器->>服务器: 请求
服务器-->>浏览器: 响应
- 爬虫基本流程
graph TD
A[目标网站] -->|分析网站| B(url)
B --> C[模拟浏览器请求资源]
C -->D[解析网页]
D-->E[保存数据]
正文:
1. 分析网站
1.1 目标网址:https://www.duitang.com/
1.2 关键字:

值得注意的是url当中是不能有汉字的,所以真正的url是这样的:
https://www.duitang.com/search/?kw=美女&type=feed
思路:
import urllib.parse
label = '美女'
label = urllib.parse.quote(label)
# 输出:%E7%BE%8E%E5%A5%B3
1.3 数据源:
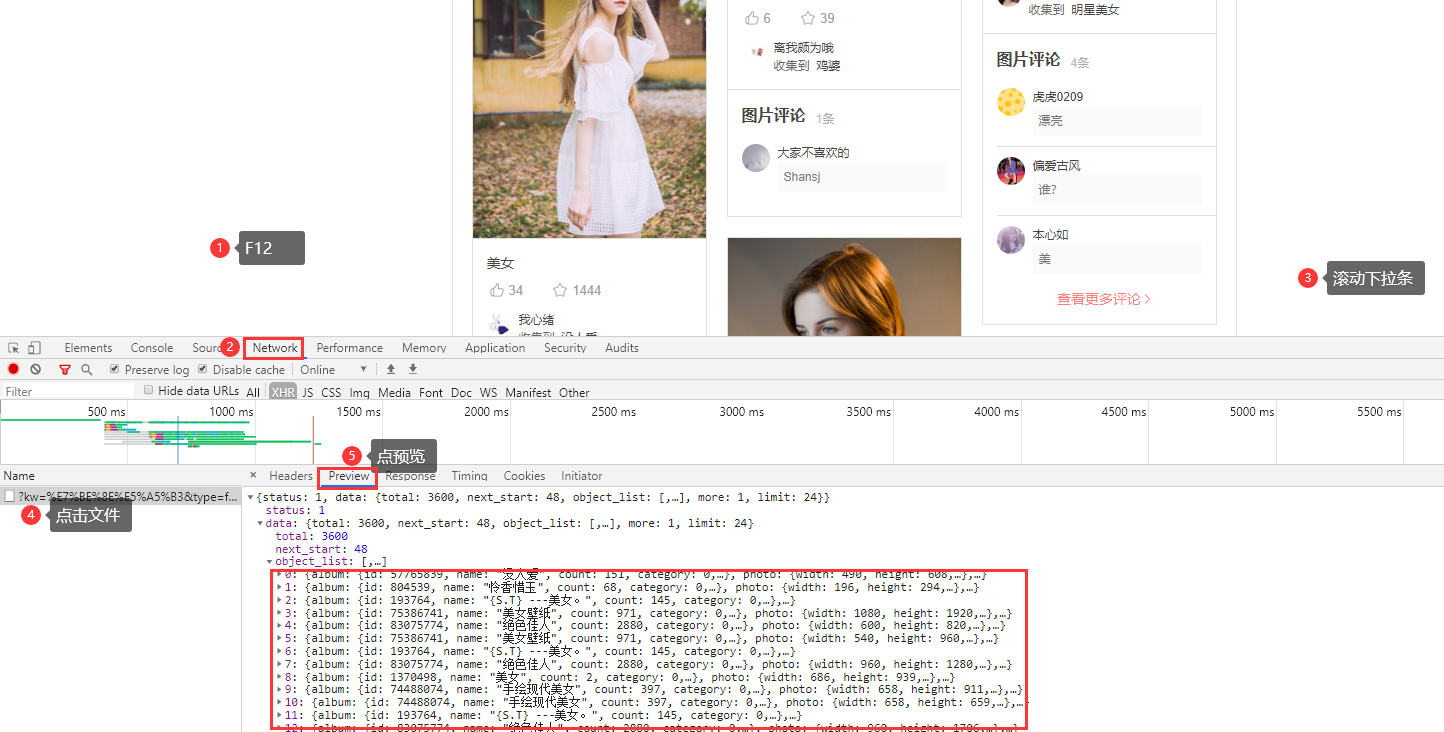
首先,这个网站的数据是瀑布流式的加载方式。
瀑布流举例说明:你去一个饭店,直接开口要十碗烩面,这个时候老板开始下面给你吃😏。然后你发现当你吃完第一碗面,你就吃不下了。这个时候,剩下的面就算白做了。所以,下次你在去饭店,还是直接开口要十碗面,这时,老板聪明了,下一碗面,你吃一碗,你还需要,就在去下面。这样就不会浪费。
针对这种数据加载,需要抓包:
2. 导库
import urllib.parse
import json
import requests
import jsonpath
3. 模拟浏览器请求资源
we_data = requests.get(url).text
4. 解析网页
因为是json文件,所以直接用jsonpath工具提取数据
# 类型转换
html = json.loads(we_data)
photo = jsonpath.jsonpath(html,"$..path")
print(photo)
得到图片的链接
5. 保存数据
num = 0
for i in photo:
a = requests.get(i)
with open(r'tupian\{}.jpg'.format(num),'wb') as f:
# content 二进制流
f.write(a.content)
num += 1
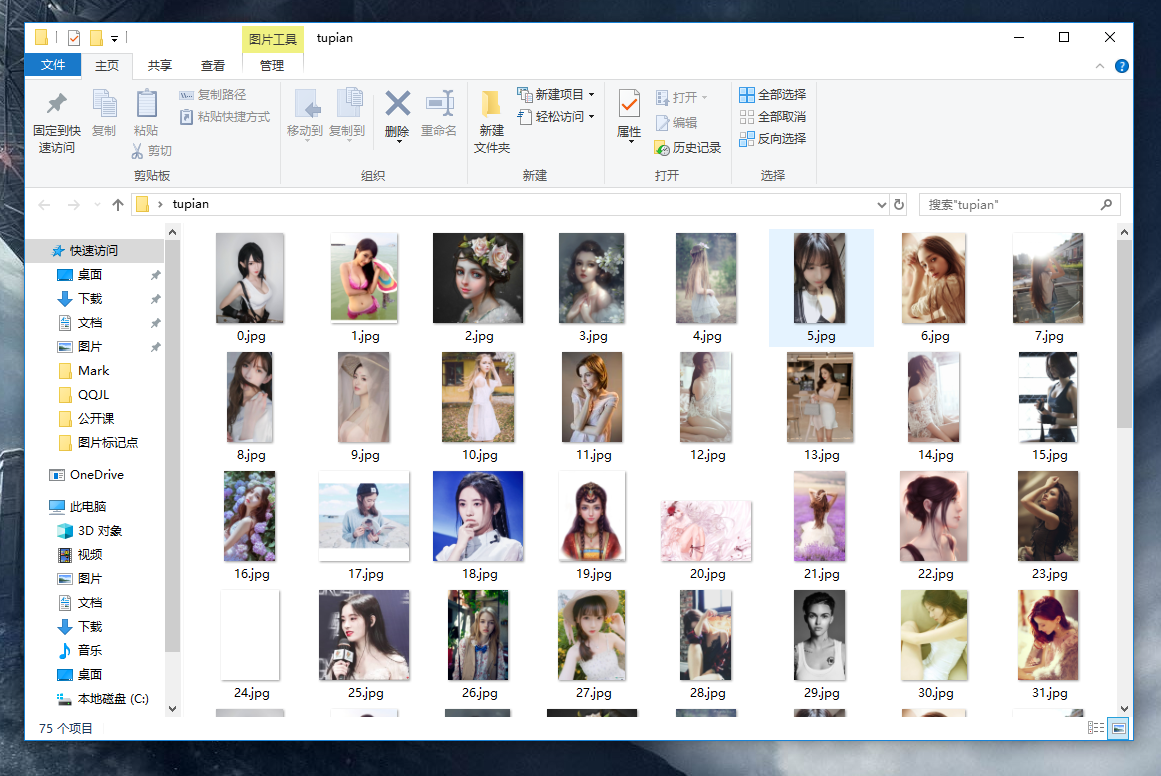
效果:


完整代码:
所以,以此为动力,又实现了翻页,下面是简单的全部代码(代码为了零基础小白看懂,大神勿喷)
import urllib.parse
import json
import requests
import jsonpath
url =
'https://www.duitang.com/napi/blog/list/by_search/?kw={}&start={}'
label = '美女'
# 关键字
label = urllib.parse.quote(label)
num = 0
# 翻页 24的间隔
for index in range(0,2400,24):
u = url.format(label,index)
we_data = requests.get(u).text
html = json.loads(we_data)
photo = jsonpath.jsonpath(html,"$..path")
# 遍历每页的图片链接
for i in photo:
a = requests.get(i)
# wb 二进制写入
with open(r'tupian\{}.jpg'.format(num),'wb') as f:
# content 二进制流
f.write(a.content)
num +=1
PS:
问题可以评论区提出


 浙公网安备 33010602011771号
浙公网安备 33010602011771号