机器学习--数据特征分析
文章目录
分析连续变量之间线性相关程度的强弱,并用适当的统计指标表示出来的过程称为相关分析。
判断两个变量是否具有线性相关关系的最直观的方法是直接绘制散点图
绘制散点图矩阵
需要同时考察多个变量间的相关关系时,一一绘制它们间的简单散点图是十分麻烦的。 此时可利用散点图矩阵同时绘制各变量间的散点图,从而快速发现多个变量间的主要相关性,这在进行多元线性回归时显得尤为重要。
为了更加准确地描述变量之间的线性相关程度,可以通过计算相关系数来进行相关分析。在二元变量的相关分析过程中比较常用的有Pearson相关系数、Spearman秩相关系数和判定系数。
(1)Pearson相关系数
一般用于分析两个连续性变量之间的关系,其计算公式如下。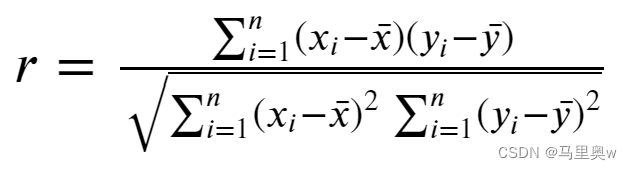
相关系数 𝑟 的取值范围: −1≤𝑟≤1
𝑟>0为正相关,𝑟<0为负相关
|𝑟|=0表示不存在线性关系
|𝑟|=1表示完全线性相关
0<|𝑟|<1表示存在不同程度线性相关:
|𝑟|≤0.3为不存在线性相关
0.3<|𝑟|≤0.5为低度线性相关
0.5<|𝑟|≤0.8为显著线性相关
|𝑟|>0.8为高度线性相关
Pearson线性相关系数要求连续变量的取值服从正态分布。
(2)Spearman秩相关系数
不服从正态分布的变量、分类或等级变量之间的关联性可采用Spearman秩相关系数,也称等级相关系数来描述。 其公式如下。
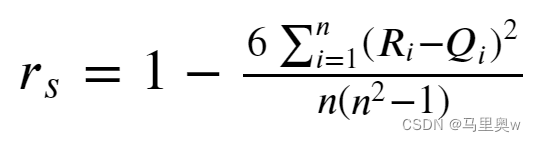
对两个变量成对的取值分别按照从小到大(或者从大到大小)顺序编秩, 𝑅𝑖 代表 𝑥𝑖 的秩次, 𝑄𝑖 代表 𝑦𝑖 的秩次, 𝑅𝑖−𝑄𝑖 为 𝑥𝑖 、 𝑦𝑖 的秩次之差。
只要两个变量具有严格单调的函数关系,那么它们就是完全Spearman相关的,这与Pearson 相关不同,Pearson相关只有在变量具有线性关系时才是完全相关的。
在实际应用计算中,上述两种相关系数都要对其进行假设检验,使用t检验方法检验其显著性水平以确定其相关程度。研究表明,在正态分布假定下,Spearman秩相关系数与Pearson 相关系数在效率上是等价的,而对于连续测量数据,更适合用Pearson相关系数来进行分析。
(3)判定系数
判定系数是相关系数的平方,用 𝑅2 表示;用来衡量回归方程对y的解释程度。判定系数取值范围: 0≤𝑟2≤1 。 𝑟2 越接近于1,表明x与y之间的相关性越强; 𝑟2 越接近于0,表明 两个变量之间几乎没有直线相关关系。
统计特征函数用于计算数据的均值、方差、标准差、分位数、相关系数和协方差等,这些统计特征能反映出数据的整体分布。
sum():计算数据样本的总和(按列计算)
mean():计算数据样本的算术平均数
var():计算数据样本的方差
std():计算数据样本的标准差
corr():计算数据样本的Spearman (Pearson)相关系数矩阵
cov():计算数据样本的协方差矩阵
skew():样本值的偏度(三阶矩)
kurt():样本值的峰度(四阶矩)
describe():给出样本的基本描述(基本统计量如均值、标准差等)
*偏度(skewness),是统计数据分布偏斜方向和程度的度量,是统计数据分布非对称程度的数字特征。定义上偏度是样本的三阶标准化矩
偏度定义中包括正态分布(偏度=0),右偏分布(也叫正偏分布,其偏度>0),左偏分布(也叫负偏分布,其偏度<0)
*峰度(peakedness;kurtosis)又称峰态系数。表征概率密度分布曲线在平均值处峰值高低的特征数。直观看来,峰度反映了峰部的尖度。随机变量的峰度计算方法为:随机变量的四阶中心矩与方差平方的比值。
峰度包括正态分布(峰度值=3),厚尾(峰度值>3),瘦尾(峰度值<3)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号