我的软考复习笔记【中级软件设计师】
- 内聚与耦合
- 统一过程(UP)
- 软件体系结构风格
- 软件能力成熟度模型(CMM)
- 集成测试策略
- 软件测试方法
- 黑盒测试
- 白盒测试
- 需求
- UML
- 设计模式
- 创建模式
- 结构模式
- 行为模式
- 责任链模式(Chain of Responsibility Pattern)
- 解释器模式(Interpreter Pattern)
- 迭代器模式(Iterator Pattern)
- 中介者模式(Mediator Pattern)
- 备忘录模式(Memento Pattern)
- 观察者模式(Observer Pattern)
- 状态模式(State Pattern)
- 空对象模式(Null Object Pattern)
- 策略模式(Strategy Pattern)
- 模板模式(Template Pattern)
- 访问者模式(Visitor Pattern)
- 命令模式(Command Pattern)
- 中介者模式(Mediator Pattern)
- MVC 模式 Model-View-Controller(模型-视图-控制器) 模式
- 算法
- 数据库
- 网络与信息安全
- 风险分析
- 标准化和软件知识产权
- 杂项
内聚与耦合
我们常说,为系统划分模块时,要做到高内聚、低耦合。
内聚
定义:
度量一个模块内部各个元素彼此结合的紧密程度。
内聚类别(内聚性由低到高排列)
偶然内聚:指一个模块内的各处理元素之间没有任何联系。
(类似于把一推不相关的代码都组合在一个类里)
逻辑内聚:指模块内执行若干个逻辑上相似的功能,通过参数确定该模块完成哪一个功能。
(类似于完成加法运算,有多个加法运算代码块,分别处理参数为int或float或double等。这些代码块之所以聚在一起,只是它们都是为了完成加法运算而已)
时间内聚:指把需要同时执行的动作组合在一起形成的模块。
(类似于利用抽象工厂模式生成一碗粥,你可以先放水,也可以先放米,这两个动作之间没有必然的顺序,但为了生成一碗粥,需要同时执行这两个动作)
过程内聚:指一个模块完成多个任务,这些任务必须按照指定的过程执行。
(类似于利用原生JDBC操纵数据库。你需要先连接JDBC获得connection对象,然后才能创建Statement对象,最后才能执行sql语句)
通信内聚:指模块内的所有处理元素都在同一个数据结构上操作,或者各处理使用相同的输入数据或者产生相同的输出数据。
(类似于有一个数组,你只把它作为你遍历数组,增加数组节点,删除数组节点的参数)
顺序内聚:指一个模块中的各个处理元素都密切相关于同一功能且必须顺序执行,前一功能元素的输出就是下一功能元素的输入。
(类似于程序模拟车间生产的某条流水线)
功能内聚:指模块内的所有元素共同作用完成一个功能,缺一不可。
(类似于某排序算法的代码,不能缺少任意一行代码,否则整个排序功能失效)
也就是说,模块功能越单一,内聚性就越高,模块的独立性就越强。一个模块应该做好一个功能就可以了,不要面面俱到,不然难以维护。
需要说明的一点是,不同程度的内聚之间并非是线性关系的。上面的所有内聚类型中,偶然内聚和逻辑内聚是非常糟糕的内聚,而其它内聚都不错。只不过在不错之中,它们又能分出个高下。
耦合
定义:度量模块之间互相连接的紧密程度。
耦合类别:(耦合性由低到高排列)
无直接耦合:指两个模块之间没有直接的关系,它们分别从属于不同模块的控制与调用,它们之间不传递任何消息。
直接耦合:两个模块之间没有直接关系,它们之间的联系完全是通过主模块的控制和调用来实现的。
数据耦合:一个模块访问另一个模块时,彼此之间是通过简单数据参数 (不是控制参数、公共数据结构或外部变量) 来交换输入、输出信息的。
标记耦合 :一组模块通过参数表传递记录信息,就是标记耦合。这个记录是某一数据结构的子结构,而不是简单变量。其实传递的是这个数据结构的地址;
控制耦合:如果一个模块通过传送开关、标志、名字等控制信息,明显地控制选择另一模块的功能,就是控制耦合。
外部耦合:一组模块都访问同一全局简单变量而不是同一全局数据结构,而且不是通过参数表传递该全局变量的信息,则称之为外部耦合。
公共耦合:若一组模块都访问同一个公共数据环境,则它们之间的耦合就称为公共耦合。公共的数据环境可以是全局数据结构、共享的通信区、内存的公共覆盖区等。
内容耦合:如果发生下列情形,两个模块之间就发生了内容耦合
(1)一个模块直接访问另一个模块的内部数据;
(2)一个模块不通过正常入口转到另一模块内部;
(3)两个模块有一部分程序代码重叠(只可能出现在汇编语言中);
(4)一个模块有多个入口。
也就是说,模块之间联系少,耦合性就越低,模块之间的相对独立性就越强。模块应该管理好自己的事情就可以了,这样即不会太复杂,也便于专注的完成自己的事情。微服务的思想也是这样。
对于耦合,如果模块间必须存在耦合,应尽量使用数据耦合,少用控制耦合,限制使用公共耦合的范围,坚决避免使用内容耦合。
统一过程(UP)
统一过程(UP)的基本特征是“用例驱动、以架构为中心的和受控的迭代式增量开发”。一个UP可分为若干个周期,每个周期的开发过程被分为4个阶段,每个阶段可进行若干次迭代。 UP将一个周期的开发过程划分为如下的4个阶段。
- 初始阶段(Inception):该阶段的主要意图是建立项目的范围和版本,确定业务实现的可能性和项目目标的稳定性。提交结果包括原始的项目需求和业务用例。
- 精化阶段(Elaboration):该阶段的主要意图是对问题域进行分析,建立系统的需求和架构,确定技术实现的可行性和系统架构的稳定性。提交结果包括系统架构及其相关文档、领域模型、修改后的业务用例和整个项目的开发计划。
- 构建阶段(Construction):主要意图是增量式地开发一个可以交付用户的软件产品。
- 提交阶段(Transition):主要意图是将软件产品提交用户。
软件体系结构风格
13种常见软件体系结构风格定义分析、结构图、优缺点 面向对象的风格架构特点和应用
软件能力成熟度模型(CMM)
-
初始级(initial)。
工作无序,项目进行过程中常放弃当初的计划。
管理无章法,缺乏健全的管理制度。开发项目成效不稳定,项目成功主要依靠项目负责人的经验和能力,他一但离去,工作秩序面目全非。 -
可重复级(Repeatable)。
管理制度化,建立了基本的管理制度和规程,管理工作有章可循。
初步实现标准化,开发工作比较好地按标准实施。
变更依法进行,做到基线化,稳定可跟踪,新项目计划和管理基于过去实践经验,具有重复以前成功项目的环境和条件。
核心:建立基本的项目管理和实践来跟踪项目费用、进度和功能特性 -
已定义级(Defined)。
许多组织追求的目标
开发过程,包括技术工作和管理工作,均已实现标准化、文档化。
建立了完善的培训制度和专家评审制度, 全部技术活动和管理活动均可控制,对项目进行中的过程、岗位和职责均有共同的理解 。
核心:使用标准开发过程(或方法论)构建(或集成)系统 -
已管理级(Managed)。
产品和过程已建立了定量的质量目标。
开发活动中的生产率和质量是可量度的。
已建立过程数据库。
已实现项目产品和过程的控制。
可预测过程和产品质量趋势,如预测偏差,实现及时纠正。
核心:管理层寻求更主动地应对系统的开发问题 -
优化级(Optimizing)。
可集中精力改进过程,采用新技术、新方法。
拥有防止出现缺陷、识别薄弱环节以及加以改进的手段。
可取得过程有效性的统计数据,并可据进行分析,从而得出最佳方法。
核心:连续地监督和改进标准化的系统开发过程
集成测试策略
| 优点 | 缺点 | |
|---|---|---|
| 自底向上 | 对底层组件行为较早验证;工作最初可并行集成,比自顶向下效率高;减少桩的工作量;支持故障隔离 | 驱动的开发工作量大;对高层的验证被推迟,设计上的错误不能被及时发现 |
| 自顶向下 | 能够较早的验证主要的控制点和判断点,如果主控制出现问题能够及时发现。 深度优先:首先实现并验证一个完整的功能需求的正确性 | 桩的开发和维护是该方法的最大问题,底层模块增加,系统越来越复杂,底层模块从测试会越来越不充分。 |
| 三明治 | 较早验证了主要的控制和判断点且较早地验证了底层模块。效率高 | 对中间层的测试不够充分; |
桩:假的返回函数等等结构上需要的东西。
软件测试方法
单元测试:检查单个模块功能。单元测试主要检查的内容包括边界测试、错误处理测试、路径测试、局部数据结构测试、模块接口测试
集成测试:模块组装起来测试它们之间是否正确工作
系统测试:在所有单元、集成测试后,对系统的功能及性能的总体测试。比如压力测试、性能测试。
确认测试:又称有效性测试,是在模拟的环境下,运用黑盒测试的方法,验证被测软件是否满足需求规格说明书列出的需求。任务是验证软件的功能和性能及其他特性是否与用户的要求一致。
黑盒测试
运用黑盒技术设计测试用例常用的方法有:
① 等价类划分
② 边界值分析
③ 因果图分析法
④ 错误推断法 等
白盒测试
语句覆盖:每个语句至少被执行一次。
判定覆盖:使设计的测试用例保证程序中每个判断的每个分支至少经历一次。判定覆盖必定满足语句覆盖。
路径覆盖:是每条可能执行到的路径至少执行一次。(比判定覆盖大,分支可能执行多次)
需求
在一般使用中,需求按照功能性(行为的)和非功能性(其它所有的行为)来分类。
功能性需求是说有具体的完成内容的需求。
例如:比如客户登录、邮箱网站的收发收发邮件、论坛网站的发帖留言等。
非功能性需求是指软件产品为满足用户业务需求而必须具有且除功能需求以外的特性,包括系统的性能、可靠性、可维护性、可扩充性和对技术和对业务的适应性等。
例如:性能要求:要求系统能满足100个人同时使用,页面反应时间不能超过6秒;
可靠性: 系统能7×24小时连续运行,年非计划宕机时间不能高于8小时。要求能快速的部署,特别是在系统出现故障时,能够快速的切换到备用机。
UML
分类

协作图(通信图)的边界类 控制类 实体类怎么区别
协作图是一种交互图。
- 边界类:边界对象的抽象,通常是用来完成参与者(用户、外部系统)与系统之间交互的对象,例如:From、对话框、菜单、接口等。

-
控制类:控制对象的抽象,主要用来体现应用程序的执行逻辑,将其抽象出来,可以使变化不影响用户界面和数据库中的表。

-
实体类:实体对象的抽象,通常来自域模型(现实世界),用来描述具体的实体,通常映射到数据库表格与文件中。



用例图的关系

泛化(Inheritance)
就是通常理解的继承关系,子用例和父用例相似,但表现出更特别的行为;子用例将继承父用例的所有结构、行为和关系。子用例可以使用父用例的一段行为,也可以重载它。父用例通常是抽象的。在实际应用中很少使用泛化关系,子用例中的特殊行为都可以作为父用例中的备选流存在。
【箭头指向】:指向父用例

扩展(extend):
扩展关系是指用例功能的延伸,相当于为基础用例提供一个附加功能。
【箭头指向】:指向基础用例

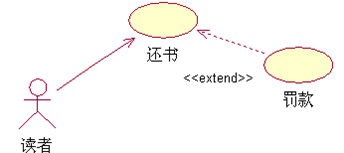
包含(include):
包含关系用来把一个较复杂用例所表示的功能分解成较小的步骤。
【箭头指向】:指向分解出来的功能用例


快速辨认
| 名称 | 图像 |
|---|---|
| 类图 |  |
| 用例图 | 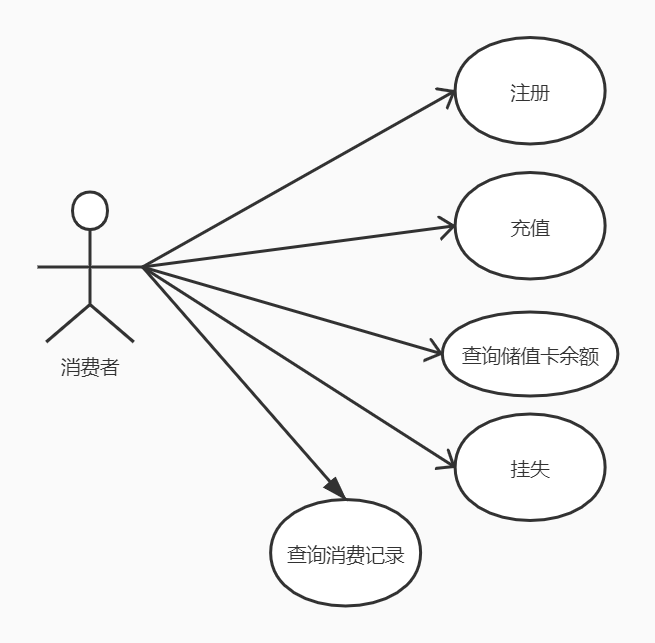 |
| 组件图(构件图) |  |
| 时序图(序列图) |  |
| 部署图 | 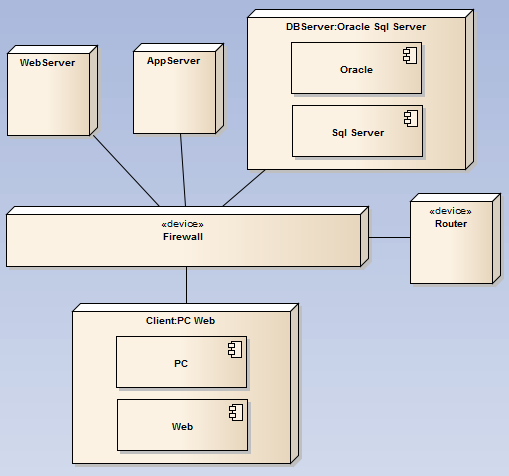 |
| 协作图(通信图) | 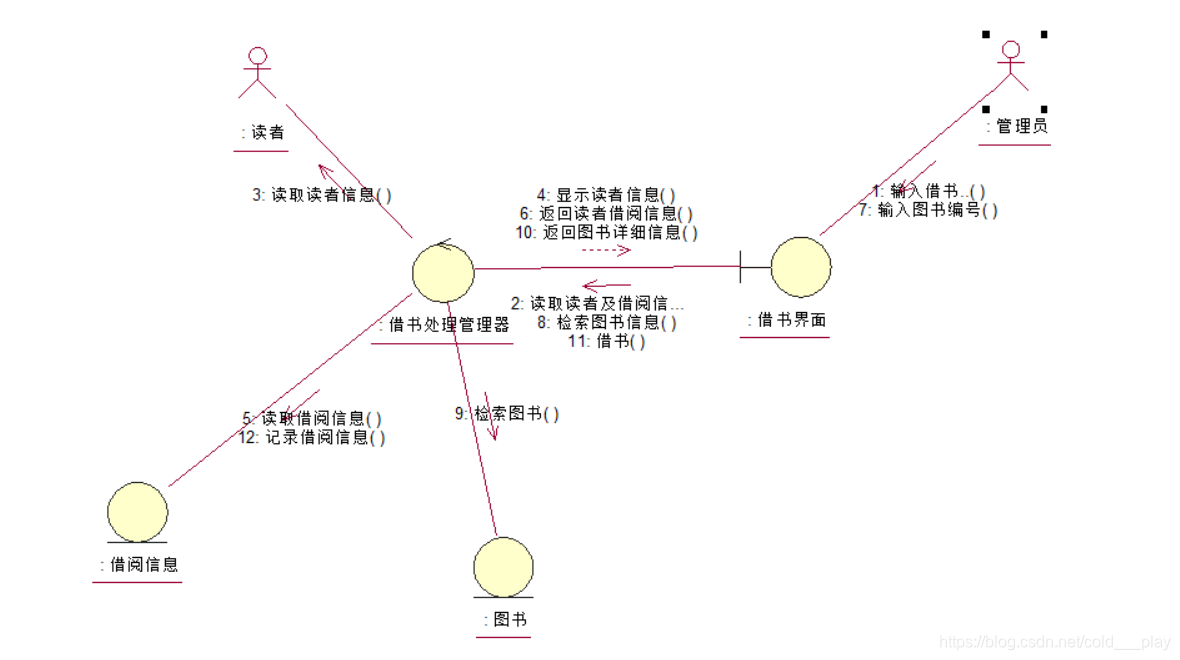 |
| 状态图 | 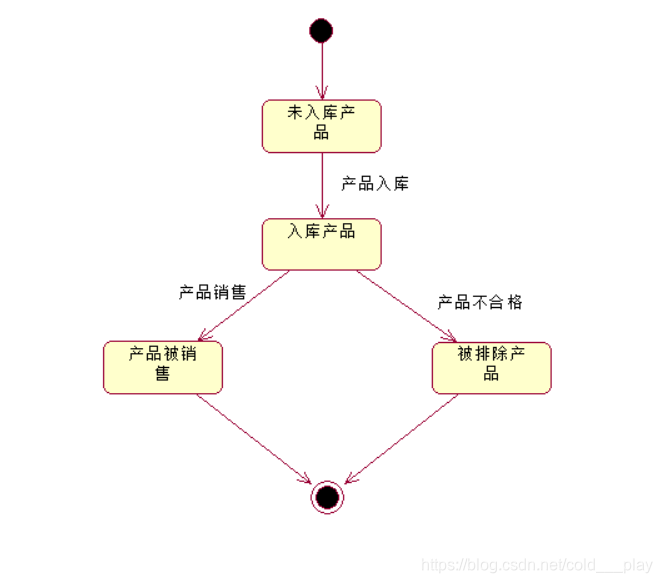 |
| 活动图 | 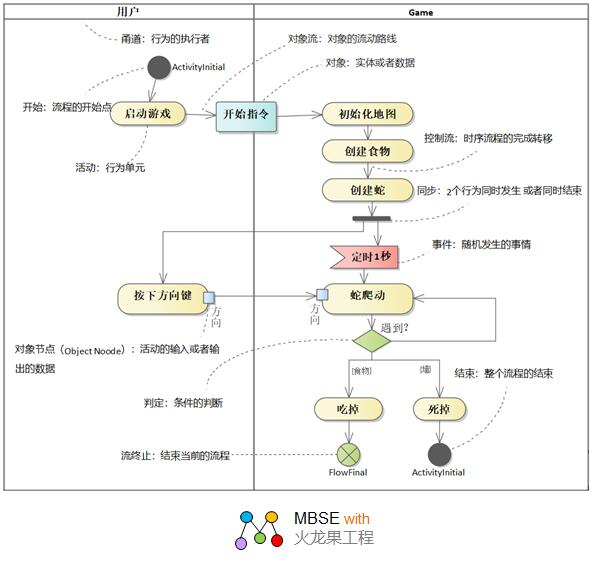 |
类图的符号
1. 关联
关联用不带箭头的实线表示。

关联连接了两个类,体现了一种语义关系。
关联通常用名词词组来标注,如下图中的Analyzes,以说明关系的实质。
类可能与它自己有关联(称为自关联),如PlanAnalyst类的实例之间的协作。注意,这里同时使用了关联端名称和关联名称,目的是提供清晰性。
也可带箭头。

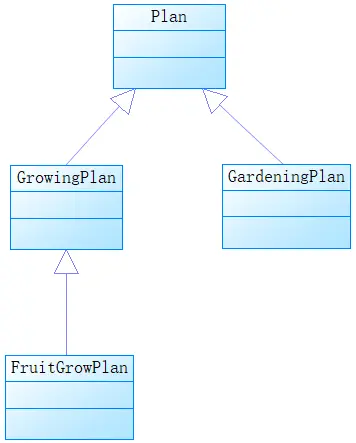
2. 泛化
泛化用带有封闭箭头的实线表示。箭头指向超类,关联的另一端是子类。
下图中的GrowingPlan类是超类,它的子类是FruitGrowingPlan。
3. 聚合
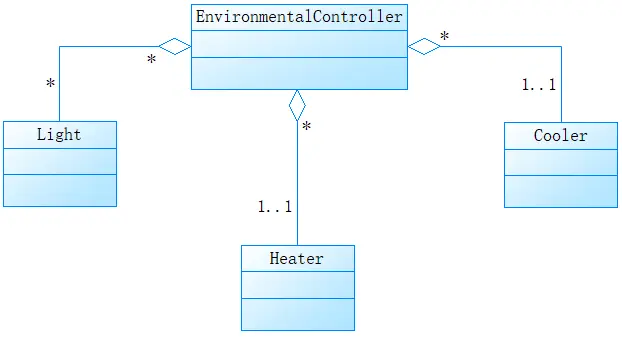
聚合表明一种整体-部分的层次结构。
聚合用带有一个空心菱形的实线表示。菱形所在的一端是聚合体(整体),另一端的类代表它的实例构成了聚合对象的部分。
自聚合和循环聚合关系是可能的。这种整体-部分的层次关系并不意味着物理上的包容:一个专业协会有一些成员,但不表示协会拥有它的成员。就如汽车和轮胎,当汽车销毁的时候,并不意味着轮胎也销毁了。即两个对象的生命周期是相互独立的。
聚合关系末端的*(0个或多个)多重性进一步突出了这不是物理包容关系。
下图中,EnvironmentalController类有Light、Heater和Cooler类作为它的部分。
组件图
- 供接口用“棒棒糖”式的图形表示,即由一个封闭的圆形与一条直线组成。
- 需接口用“插座”式的图形表示,即由一个半圆与一条直线组成。
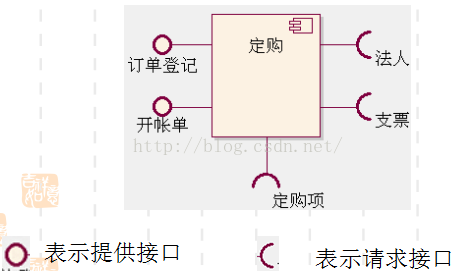
协作图(通信图)元素
通信图由三部分组成:对象(Object),链(Link) 和消息(Message)。
比如下图,黄框是对象,1.x等是消息。

设计模式
组合大于继承。
创建模式
工厂模式(Factory Pattern)
简单工厂:定义了一个创建对象的类,由这个类来封装实例化对象的行为。
工厂模式适用的场合: 大量的产品需要创建,并且这些产品具有共同的接口 。
简单工厂 : 用来生产同一等级结构中的任意产品。(不支持拓展增加产品)
工厂方法 :用来生产同一等级结构中的固定产品。(支持拓展增加产品)
抽象工厂模式(Abstract Factory Pattern) :用来生产不同产品族的全部产品。(支持拓展增加产品;支持增加产品族)
单例模式(Singleton Pattern)
意图:保证一个类仅有一个实例,并提供一个访问它的全局访问点。
主要解决:一个全局使用的类频繁地创建与销毁。
建造者模式(生成器模式)(Builder Pattern)
使用多个简单的对象一步一步构建成一个复杂的对象。
原型模式(Prototype Pattern)
利用已有的一个原型对象,快速地生成和原型对象一样的实例。
关键:clone()
结构模式
适配器模式(Adapter Pattern)
将一个类的接口转换成客户希望的另外一个接口。适配器模式使得原本由于接口不兼容而不能一起工作的那些类可以一起工作。
类适配器模式:当希望将一个类转换成满足另一个新接口的类时,可以使用类的适配器模式,创建一个新类,继承原有的类,实现新的接口即可。
对象适配器模式:当希望将一个对象转换成满足另一个新接口的对象时,可以创建一个Wrapper类,持有原类的一个实例,在Wrapper类的方法中,调用实例的方法就行。
接口适配器模式:当不希望实现一个接口中所有的方法时,可以创建一个抽象类Wrapper,实现所有方法,我们写别的类的时候,继承抽象类即可。
桥接模式(Bridge)
意图:将抽象部分与实现部分分离,使它们都可以独立的变化。
主要解决:在有多种可能会变化的情况下,用继承会造成类爆炸问题,扩展起来不灵活。
与适配器的区别:如果你拿到两个已有模块,想让他们同时工作,那么你使用的是适配器。如果你还什么都没有,但是想分开实现,那么桥接是一个选择。
过滤器模式(Filter Pattern)
装饰器模式(Decorator Pattern)
允许向一个现有的对象添加新的功能,同时又不改变其结构。
意图:动态地给一个对象添加一些额外的职责。就增加功能来说,装饰器模式相比生成子类更为灵活。
何时使用:在不想增加很多子类的情况下扩展类。
优点:装饰类和被装饰类可以独立发展,不会相互耦合,装饰模式是继承的一个替代模式,装饰模式可以动态扩展一个实现类的功能。
缺点:多层装饰比较复杂。
外观模式(Facade Pattern)
隐藏系统的复杂性,并向客户端提供了一个客户端可以访问系统的接口。
何时使用: 1、客户端不需要知道系统内部的复杂联系,整个系统只需提供一个"接待员"即可。 2、定义系统的入口。
使用场景: 1、为复杂的模块或子系统提供外界访问的模块。 2、子系统相对独立。 3、预防低水平人员带来的风险。
组合模式(Composite Pattern)
意图:将对象组合成树形结构以表示"部分-整体"的层次结构。组合模式使得用户对单个对象和组合对象的使用具有一致性。
优点: 1、高层模块调用简单。 2、节点自由增加。
缺点:在使用组合模式时,其叶子和树枝的声明都是实现类,而不是接口,违反了依赖倒置原则。
使用场景:部分、整体场景,如树形菜单,文件、文件夹的管理。
享元模式(Flyweight Pattern)
主要用于减少创建对象的数量,以减少内存占用和提高性能。
意图:运用共享技术有效地支持大量细粒度的对象。
主要解决:在有大量对象时,有可能会造成内存溢出,我们把其中共同的部分抽象出来,如果有相同的业务请求,直接返回在内存中已有的对象,避免重新创建。
何时使用: 1、系统中有大量对象。 2、这些对象消耗大量内存。 3、这些对象的状态大部分可以外部化。 4、这些对象可以按照内蕴状态分为很多组,当把外蕴对象从对象中剔除出来时,每一组对象都可以用一个对象来代替。 5、系统不依赖于这些对象身份,这些对象是不可分辨的。
如何解决:用唯一标识码判断,如果在内存中有,则返回这个唯一标识码所标识的对象。
关键代码:用 HashMap 存储这些对象。
代理模式(Proxy Pattern)
意图:为其他对象提供一种代理以控制对这个对象的访问。
一个类提供对另一个类的访问。
优点: 1、职责清晰。 2、高扩展性。 3、智能化。
缺点: 1、由于在客户端和真实主题之间增加了代理对象,因此有些类型的代理模式可能会造成请求的处理速度变慢。 2、实现代理模式需要额外的工作,有些代理模式的实现非常复杂。
行为模式
责任链模式(Chain of Responsibility Pattern)
为请求创建了一个接收者对象的链。
意图:避免请求发送者与接收者耦合在一起,让多个对象都有可能接收请求,将这些对象连接成一条链,并且沿着这条链传递请求,直到有对象处理它为止。
主要解决:职责链上的处理者负责处理请求,客户只需要将请求发送到职责链上即可,无须关心请求的处理细节和请求的传递,所以职责链将请求的发送者和请求的处理者解耦了。
解释器模式(Interpreter Pattern)
意图:给定一个语言,定义它的文法表示,并定义一个解释器,这个解释器使用该标识来解释语言中的句子。
主要解决:对于一些固定文法构建一个解释句子的解释器。
迭代器模式(Iterator Pattern)
意图:提供一种方法顺序访问一个聚合对象中各个元素, 而又无须暴露该对象的内部表示。
中介者模式(Mediator Pattern)
提供了一个中介类,该类通常处理不同类之间的通信,并支持松耦合,使代码易于维护。
备忘录模式(Memento Pattern)
保存一个对象的某个状态,以便在适当的时候恢复对象。
意图:在不破坏封装性的前提下,捕获一个对象的内部状态,并在该对象之外保存这个状态。
观察者模式(Observer Pattern)
当一个对象被修改时,则会自动通知依赖它的对象。
状态模式(State Pattern)
类的行为是基于它的状态改变的。
何时使用:代码中包含大量与对象状态有关的条件语句。
空对象模式(Null Object Pattern)
一个空对象取代 NULL 进行实例的检查。
策略模式(Strategy Pattern)
意图:定义一系列的算法,把它们一个个封装起来, 并且使它们可相互替换。
主要解决:在有多种算法相似的情况下,使用 if...else 所带来的复杂和难以维护。
何时使用:一个系统有许多许多类,而区分它们的只是他们直接的行为。
优点: 1、算法可以自由切换。 2、避免使用多重条件判断。 3、扩展性良好。
缺点: 1、策略类会增多。 2、所有策略类都需要对外暴露。
模板模式(Template Pattern)
一个抽象类公开定义了执行它的方法的方式/模板。它的子类可以按需要重写方法实现,但调用将以抽象类中定义的方式进行。
意图:定义一个操作中的算法的骨架,而将一些步骤延迟到子类中。模板方法使得子类可以不改变一个算法的结构即可重定义该算法的某些特定步骤。
主要解决:一些方法通用,却在每一个子类都重新写了这一方法。
访问者模式(Visitor Pattern)
我们使用了一个访问者类,它改变了元素类的执行算法。通过这种方式,元素的执行算法可以随着访问者改变而改变。这种类型的设计模式属于行为型模式。(多态)
意图:主要将数据结构与数据操作分离。
主要解决:稳定的数据结构和易变的操作耦合问题。
命令模式(Command Pattern)
请求以命令的形式包裹在对象中,并传给调用对象。调用对象寻找可以处理该命令的合适的对象,并把该命令传给相应的对象,该对象执行命令。
中介者模式(Mediator Pattern)
意图:用一个中介对象来封装一系列的对象交互,中介者使各对象不需要显式地相互引用,从而使其耦合松散,而且可以独立地改变它们之间的交互。
主要解决:对象与对象之间存在大量的关联关系,这样势必会导致系统的结构变得很复杂,同时若一个对象发生改变,我们也需要跟踪与之相关联的对象,同时做出相应的处理。
MVC 模式 Model-View-Controller(模型-视图-控制器) 模式
这种模式用于应用程序的分层开发。
算法
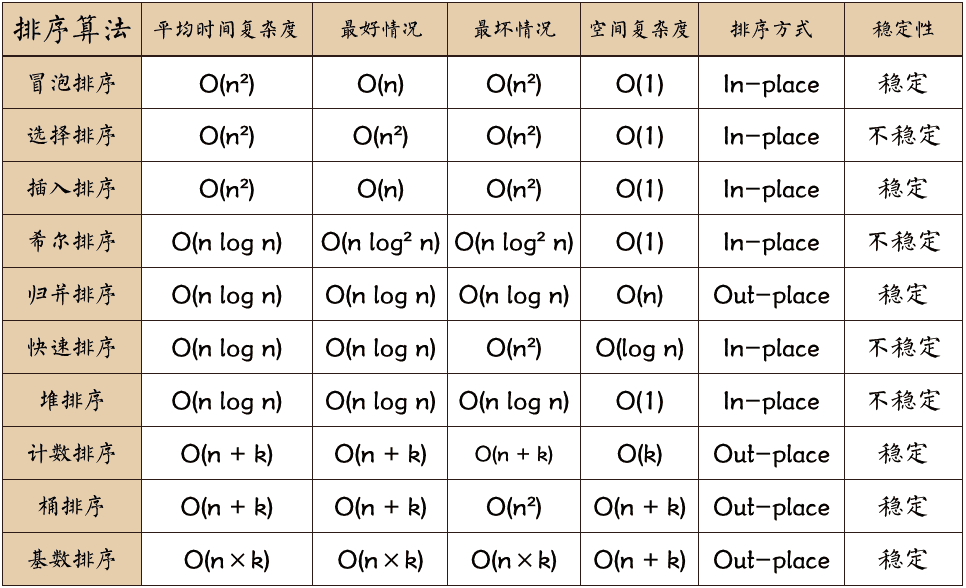
排序算法
最坏情况下,堆排序与归并排序时间复杂度最好。
主定理
已知算法的运行时间函数为:
则对比\(f(n)\)和\(n^{log_ {b} {a}}\), 更大者(渐进比较)即为\(\Theta\)解;若\(f(n)=\Theta (n^{log_ {b}{a}} lg^{k}_ {}{n})\),(k可为0)则解为\(n^{log_ {b}a} lg^{k+1}_ {}{n}\)
手算KMP的next值
得到子串的最长相同前后缀长度,然后前面补-1。舍掉最后一位,即为next值。
比如:子串 abcabccba
| a | b | c | a | b | c | c | b | a | |
|---|---|---|---|---|---|---|---|---|---|
| 最长相同前后缀长度 | 0 | 0 | 0 | 1 | 2 | 3 | 0 | 0 | |
| next | -1 | 0 | 0 | 0 | 1 | 2 | 3 | 0 | 0 |
输出next=[-1,0,0,0,1,2,3,0,0]
最长前后缀长度如何理解?比如对于这个子串,abcab的最长相同前后缀为ab,所以长度为2,所以上表中就填2.
前后缀不用颠倒,比如abba,这个最长相同前后缀长度就是1,不是2
有时候,题目给的是next[j]是如下图所示的,这种情况下,next的开头两个必定是-1和0,因为当$$j=1$$时不存在0和1之间的整数,所以是其他情况。$$j=2$$就要看前后缀了,但是注意,第二行显示$$p_{j-k}...p_{j-1}$$是到$$j-1$$,不是到末位,这个要注意。然后按照题意做就行了。
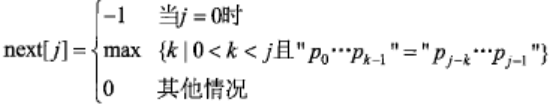
数据库
关系代数运算
笛卡尔积 R X S, “大”连接, 全都连起来
自然连接 R ⨝ S 是一种特殊的等值连接,它要求两个关系进行比较的分量必须是相同的属性组,并且在结果集中将重复属性列去掉。
事务的特性
原子性: 要么做,要么不做
一致性:事务执行的结果要保证数据库从一个一致性状态变到另一个一致性状态。
隔离性:事务之间互相不可见。
持久性:一旦事务提交成功,即使数据库崩溃,对数据库的更新操作的结果也不会消失
模式
视图-外模式,存储文件-内模式,基本表-模式。
一、模式(Schema)
定义:模式又称概念模式或逻辑模式,是数据库中全体数据的逻辑结构和特征的描述,是所有用户的公共数据视图。
理解: ① 一个数据库只有一个模式; ② 是数据库数据在逻辑级上的视图; ③ 数据库模式以某一种数据模型为基础; ④ 定义模式时不仅要定义数据的逻辑结构(如数据记录由哪些数据项构成,数据项的名字、类型、取值范围等),而且要定义与数据有关的安全性、完整性要求,定义这些数据之间的联系。
二、外模式(External Schema)
定义:也称子模式(Subschema)或用户模式,是数据库用户(包括应用程序员和最终用户)能够看见和使用的局部数据的逻辑结构和特征的描述,是数据库用户的数据视图,是与某一应用有关的数据的逻辑表示。
理解: ① 一个数据库可以有多个外模式; ② 外模式就是用户视图; ③ 外模式是保证数据安全性的一个有力措施。
三、内模式(Internal Schema)
定义:也称存储模式(Storage Schema),它是数据物理结构和存储方式的描述,是数据在数据库内部的表示方式(例如,记录的存储方式是顺序存储、按照B树结构存储还是按hash方法存储;索引按照什么方式组织;数据是否压缩存储,是否加密;数据的存储记录结构有何规定)。
理解: ① 一个数据库只有一个内模式; ② 一个表可能由多个文件组成,如:数据文件、索引文件。 它是数据库管理系统(DBMS)对数据库中数据进行有效组织和管理的方法 其目的有: ① 为了减少数据冗余,实现数据共享; ② 为了提高存取效率,改善性能。
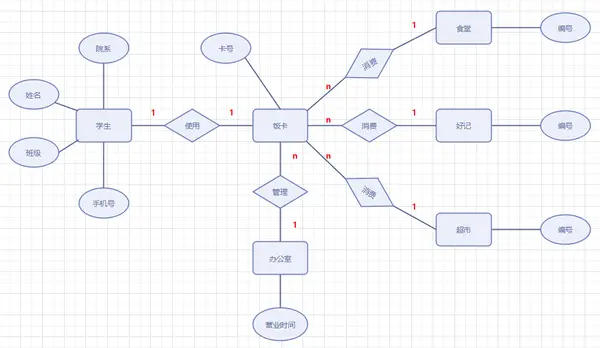
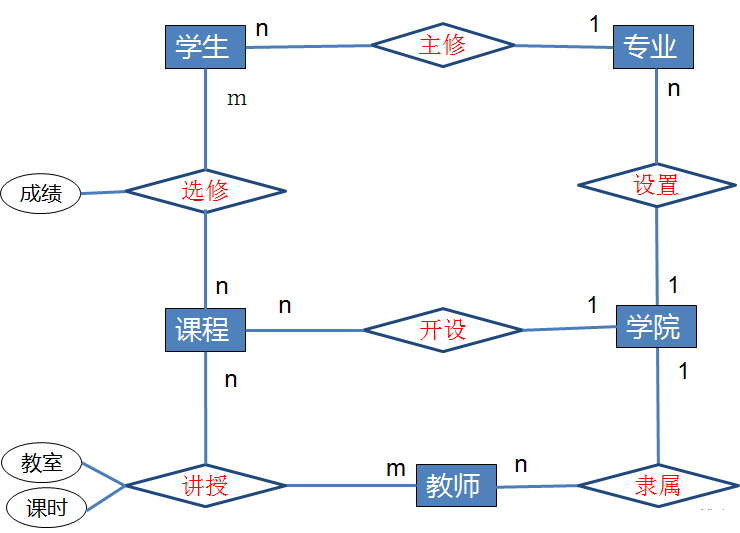
E-R图
1)矩形框:表示实体,在框中记入实体名。
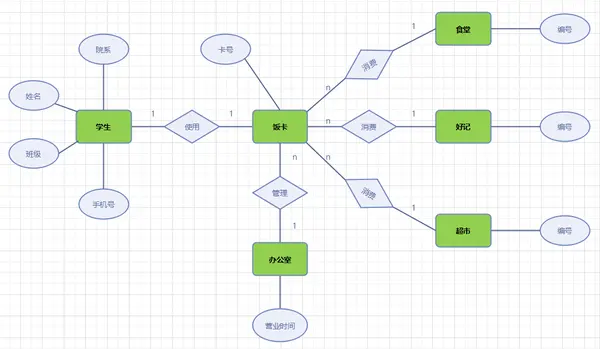
2)菱形框:表示联系,在框中记入联系名。
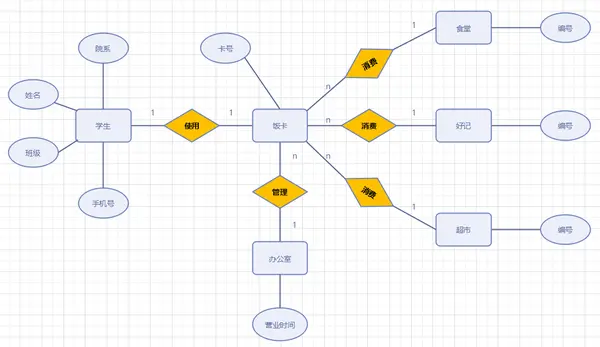
3)椭圆形框:表示实体或联系的属性,将属性名记入框中。对于主属性名,则在其名称下划一下划线。
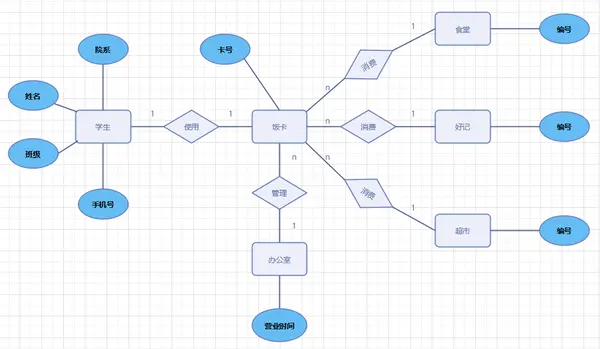
4)连线:实体与属性之间;实体与联系之间;联系与属性之间用直线相连,并在直线上标注联系的类型。(对于一对一联系,要在两个实体连线方向各写1; 对于一对多联系,要在一的一方写1,多的一方写N;对于多对多关系,则要在两个实体连线方向各写N,M。)
SQL查询语句
HAVING 和 WHERE 的区别
having是在分组(GROUP BY)后对数据进行过滤,where是在分组前对数据进行过滤
having后面可以使用聚合函数,where后面不可以使用聚合
聚合函数包括sum,min,max,avg,count等
范式
第一范式(1NF):每个属性都不可再分。1NF是所有关系型数据库的最基本要求
2NF在1NF的基础之上,消除了非主属性对于码的部分函数依赖。(部分函数依赖:B依赖A,但是不完全依赖A)
3NF在2NF的基础之上,消除了非主属性对于码的传递函数依赖。
BCNF
4NF
5NF
分布式数据库
分片透明(用户不必知道关系数据是如何分片的),复制透明(用户不用关系数据库在网络中各个节点的复制情况),位置透明(用户不必直到所操作的数据放在何处),逻辑透明(用户不必关心局部DBMS支持哪种数据类型)
无损连接与保持函数依赖
无损连接性:
-
把分解的两个表(设为R1和R2)的交集找出来。
-
判断这个交集是否为R1的超码或者是R2的超码(只要是其中一个集合的超码即可)(超码:一个或多个属性的集合,这些属性的组合可以使我们在一个实体集中唯一地标识一个实体。比如对于学生,学号就是超码)。
如果满足,那么有无损连接性
保持函数依赖:
F上的全部函数依赖都能在分解后的关系上成立。设数据库模式ρ={R1,R2,…,Rk}是关系模式R的一个分解,F是R上的函数依赖集,ρ中每个模式Ri上的FD集是Fi。如果{F1,F2,…,Fk}与F是等价的(即相互逻辑蕴涵),那么称分解ρ保持函数依赖。
杂项
主键全码(all-key),即全部属性都为主键。
网络与信息安全
网络安全控制技术包括防火墙技术、入侵检测技术、访问控制技术等
OSI参考模型
物理层:集线器、中继器
数据链路层:网桥
网络层:路由器
传输层
会话层
表示层
应用层
TCP/IP建立可靠连接在传输层完成。
IP地址分类
A:0开头
B:10开头
C:110开头
D:1110开头,用作多点广播
E:1111开头,仅用作实验和开发用
特殊IP:末尾段为全0,表示空IP;全1,表示广播地址。
协议
网络层协议:
ARP(是根据IP地址获取物理地址的一个TCP/IP协议),
ICMP(用于 TCP/IP 网络中发送控制消息,提供可能发生在通信环境中的各种问题反馈,通过这些信息,使网络管理者可以对所发生的问题作出诊断,然后采取适当的措施解决问题。)
数据链路层协议:X.25
应用层协议:HTTP等,它们分别基于:
TCP:POP3,HTTP, FTP, Telnet, SMTP
UDP: DNS, TFTP, DHCP, SNMP
端口
端口范围
一般用到的是1到65535,其中0一般不使用。端口号可分为3大类:
- 公认端口(Well Known Ports):从0到1023,它们紧密绑定(binding)于一些服务。通常这些端口的通讯明确表明了某种服务的协议。
- 注册端口(Registered Ports):从1024到49151。它们松散地绑定于一些服务。也就是说有许多服务绑定于这些端口,这些端口同样用于许多其它目的。例如:许多系统处理动态端口从1024左右开始。
- 动态和/或私有端口(Dynamic and/or Private Ports):从49152到65535。理论上,不应为服务分配这些端口。实际上,机器通常从1024起分配动态端口。但也有例外:SUN的RPC端口从32768开始。
端口对应协议
| 协议 | 端口 | 功能 |
|---|---|---|
| HTTP | 80 | |
| HTTPS | 443 | |
| SMTP | 25 | 简单邮件协议。 |
| POP3 | 110 | 接收邮件 |
| FTP | 21用于连接。20用于传输数据。 | |
| DHCP | 67 | 动态主机配置协议:给内部网络或网络服务供应商自动分配IP地址 |
| TFTP | 69 | 简单文件传输协议是用来在客户机与服务器之间进行简单文件传输的协议 |
| DNS | 53 | |
| SNMP | 161 | 简单网络管理协议,主要用在局域网中对设备进行管理,应用最为广泛的是对路由器交换机等网络设备的管理。 |
| MIME | 多用途互联网邮件拓展。可包含文本、图像、音频等。与安全无关。 |
加密算法与信息摘要算法
非对称加密又称为公开密钥加密,而共享密钥加密指对称加密。
常见的对称加密算法有:DES,三重DES、RC-5、IDEA、AES。
常见的非对称加密算法有:RSA、ECC(移动设备用)、Diffie-Hellman、El Gamal、DSA(数字签名用)
加密算法:
RSA:非对称加密。用CA的私钥加密,CA的公钥解密
RC5:适合大量明文的加密
PGP:是一套用于讯息加密、验证的应用程序。
信息摘要算法:
MD5
SHA-1
用户A和B要进行安全通信,通信过程需确认双方身份和消息不可否认。A和B通信时可使用数字证书来对用户的身份进行认证;使用数字签名确保消息不可否认。
病毒
木马:在用户的计算机中隐藏以实现远程控制用户计算机的目的。
蠕虫:利用系统漏洞,不断自我复制、传播。比如熊猫烧香。
路由
主机路由:目的地址是一个完整的主机地址,子网掩码为255.255.255.255
静态路由:包括目标节点和目标网络的IP地址,对应的子网掩码一般为255.255.255.0
默认路由:是一种特殊的静态路由,指的是当路由表中与包的目的地址之间没有匹配的表项时路由器能够做出的选择,和静态路由格式一样,但目的地IP和子网掩码为0.0.0.0
媒体
感觉媒体:指的是能直接作用于人的感官的媒体,比如文字、声音、图像
表现媒体:把电信号和感觉媒体互相转换的设备,比如键盘、鼠标、显示器
表示媒体:各种对感觉媒体的编码方式,如文本编码、图像编码
存储媒体:硬盘、光盘等
传输媒体:电缆和光缆等
IPv4过渡IPv6技术
双协议栈技术:网络中的节点同时支持IPv4和IPv6协议栈,使纯IPv6节点可以和纯IPv4节点通信。
隧道技术:两个IPv6节点可以通过现有的IPv4网络进行通信。
翻译技术:IP报文在IPv4和IPv6之间进行转化。
杂项
域名查询记录顺序:本地DNS缓存,HOSTS表,本地DNS服务器,根域名服务器,顶级域名服务器,权限域名服务器
DMZ区:防火墙和内部服务器的缓冲区,常用来存放必须公开的服务器,比如web服务器、FTP服务器、论坛等。
PPP的安全认证协议是CHAP,它使用三次握手的会话过程传递密文。
风险分析
风险识别:试图系统化地确定对项目估算、进度、资源分配等的威胁
风险预测:又称风险估算。对风险的损失进行度量。
风险评估:主要任务是确定风险发生的概率和后果
风险控制:对风险发生的监督和对风险管理的监督
标准化和软件知识产权
烟草制品必须使用注册商标。
商标发音和功能近似,存在侵权风险,两个如果同时注册,只能抽签决定其中一个获得注册。如果有先使用的,先使用的能获准注册。
著作权法规定,作者的署名权、修改权、保护作品完整权的保护期不受限制;发表权、著作财产权的保护期为作者终生及其死亡后五十年。
在中国销售产品,如果其专利未在中国注册,则不需要向专利的注册国支付专利许可使用费。
商标权可以通过续注延长拥有期限,而著作权、专利权和设计权的保护期限都是有限期的。
杂项
默认网关的IP地址应与主机IP地址在同一网段
描述矢量图的基本组成单位是图元,构成视频信息的基本单元是帧。
相加混色:发射光,如电子屏幕
相减混色:反射光,如油墨或颜料
结构化开发方法中,数据流图是需求分析阶段产生的成果。
UNIX操作系统中,输入输出设备看做是特殊文件。
Windows操作系统中,使用tracert命令来测试到达目标锁经过的路由器数目及IP地址。
迪杰斯特拉(Dijkstra)算法运用了贪心策略。
金融系统设计看重有效性、安全性、高可用性(停工时间少)。
CPU主要由运算器、控制器、寄存器组和内部总线等部件构成:
控制器:程序计数器PC、指令寄存器IR、程序状态字寄存器PSW、中断机构等。
运算器:算术逻辑单元ALU、累加寄存器、数据缓冲寄存器和状态条件寄存器。
树的高从叶子开始数。深度从根开始数。从1开始数,下图的树的高度和深度都为4!!!

两个同符号数相加或异符号的数相减,所得结果的符号位进位标志SF和数据位高位进位标志CF进行异或运算为1时,表示运算的结果产生溢出。
同步多媒体集成语言,称为SMIL
源代码的错误只有两种:语法错误与语义错误(逻辑错误)(比如除0)
模型-视图-控制器(MVC)模式:视图表示用户界面,模型用来描述核心业务逻辑
<title style="italic">science</title>中, title是元素标记名称,style是元素标记属性名称,italic是元素标记属性值,science是元素内容。
子网内可以有多个DHCP,用户以收到的第一个DHCP应答信号为准。
单模光纤:成本高、芯线窄、需要激光源、高效,适用于高速、长距离通信。
多模光纤:成本低、芯线宽、耗散大、低效,适用于低速、短距离通信。
词法分析器的任务是把字符流转换成信号流;语法分析器识别记号流中的结构,并构造语法树。
IO软件隐藏物理设备细节。
MVC模式不能提高系统的运行效率。
测试设计和测试用例在需求分析阶段撰写。
在面向对象设计时,对于多对多的联系,这个关系模式需要设计新的类。
直接主存存取(Direct Memory Access,DMA)是指数据在主存与I/O设备间(即主存与外设之间)直接成块传送。
程序的局限性表现在时间局部性和空间局部性:
(1)时间局部性是指如果程序中的某条指令一旦被执行,则不久的将来该指令可能再次被执行;
(2)空间局部性是指一旦程序访问了某个存储单元,则在不久的将来,其附近的存储单元也最有可能被访问。
1、原型方法适用于用户需求不清、需求经常变化的情况,可以帮助导出系统需求并验证需求的有效性;
2、探索型原型的目的是弄清目标的要求,确定所希望的特性,并探讨多种方案的可行性,可以用来探索特殊的软件解决方案;
3、原型法能够迅速地开发出一个让用户看得见的系统框架,可以用来支持用户界面设计。
原型法不能用来指导代码优化
在设计测试用例时,一个好的无效等价类,应该只从一个角度违反规则。
题目要求补充完整性约束即要求说明主键和外键。
用例描述,列出所有基本事件流和备选事件流。用序号表示,备选用3a、3b、4a等表示。
N位二进制数原码,反码,所能表示的十进制数的范围都是是-2(N-1)-1~+2(N-1)-1。
N位二进制数补码能表示的十进制数的范围是-2(N-1)~+2(N-1)-1。
二叉排序树的关键码序列:根节点必须为首个元素。然后把后面的元素依次添加到树中,最终能正确还原原来的二叉树的即为正确的关键码序列。
我国保护计算机软件著作权的两个基本法律文件是《中华人民共和国著作权法》和《计算机软件保护条例》。
结构化方法的分析结果由以下几部分组成:一套分层的数据流图、一本数据词典、一组小说明(也称加工逻辑说明)、补充材料。
极限编程
只处理当前的需求,使设计保持简单
编写完程序之后编写测试代码
系统最终用户代表应该全程配合XP团队
极限编程提倡小型版本发布,每一轮迭代大约2周
进程状态
单处理机系统中,如果采用先来先服务调度算法 ,那么:同时只有一个程序运行;运行的程序时间片到达后,会转为就绪状态。
等待状态,是指在等待IO等,即使此时CPU空闲,该进程也不能运行。
编译时不同阶段的分析
词法分析阶段依据语言的词法规则,对源程序进行逐个字符地扫描,从中识别出一个个“单词”符号,主要是针对词汇的检查。
语法分析的任务是在词法分析的基础上,根据语言的语法规则将单词符号序列分解成各类语法单位,如“表达式”“语句”和“程序”等。语法规则
就是各类语法单位的构成规则,主要是针对结构的检查。
语义分析阶段分析各语法结构的含义,检查源程序是否包含语义错误,主要针对句子含义的检查。
校验
海明码:设数据有n位,校验码有x位。则校验码一共有\(2^x\)种取值方式。其中需要一种取值方式表示数据正确,剩下\(2^{x}-1\)种取值方式表示有一位数据出错。因为编码后的二进制串有n+x位,因此x应该满足\(2^{x} -1 ≥ n+x\)
循环冗余检验CRC: 采用模二除法运算
奇偶校验:奇校验:总共有奇数个1,则校验位为1;偶校验同理。
结构化语言
IF ^^^^^^^ THEN
^^^^^^^
ELSE IF ^^^^^^^ THEN
^^^^^^^
ELSE
ENDIF
WHILE( ^^^^^^^ )
DO{
^^^^^^^
}ENDDO
面向对象设计的原则
共同重用:如果重用了包中的一个类,那么要重用包中的所有类。
开放封闭:类要对拓展开放,对修改封闭
接口分离:统一接口,但方法可以多样
共同封闭:某个原因要修改的所有类,应当封闭进同一个包里。
寻址方式
获取操作数最快的方式是立即寻址。操作数直接就在指令中,不用去找它的地址。
若操作数的地址包含在指令中,为直接寻址。
图的英文缩写
UML
DFD:数据流图
ERD:数据库实体关系图,也可以说是E-R图。
PERT:用网络图来表达项目中各项活动的进度和它们之间的相互关系,并在此基础上进行网络分析和时间估计,用于协调整个计划的完成。也可用甘特图(Gantt图)完成该任务。
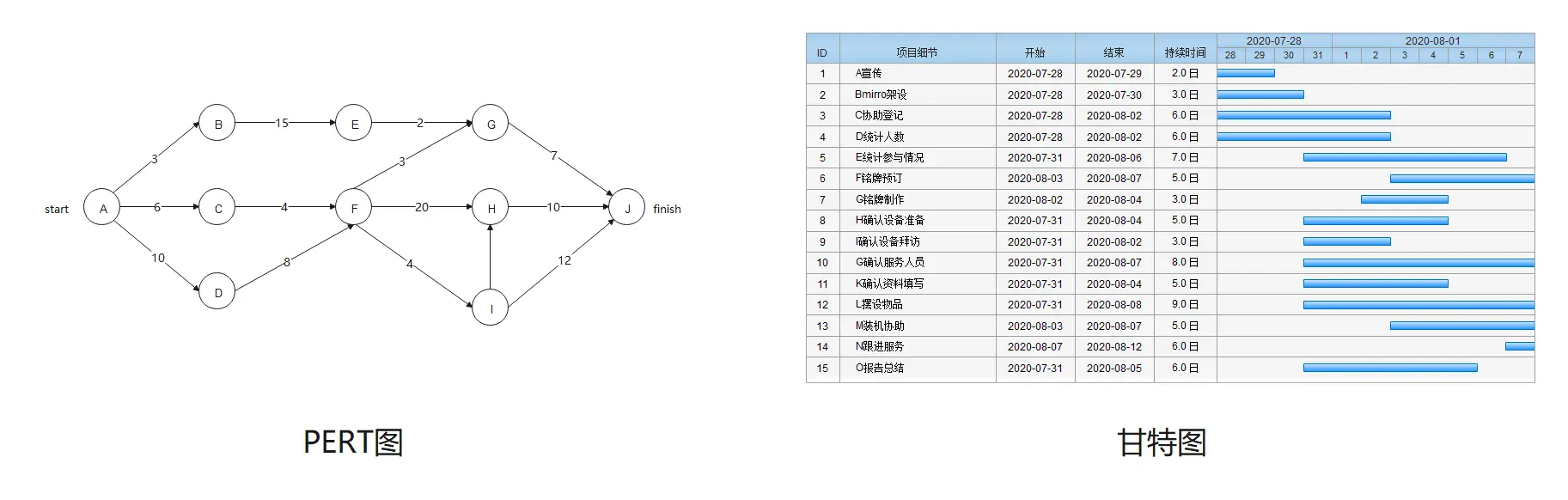
ERD图:
多态
通用多态:参数多态(静态的,即模板类)和包含多态(函数重载,virtual/override这些)。
特殊多态:强制多态(隐式强制转换,比如int强制转double)和过载多态(同名函数或操作符在不同上下文有不同类型)。
迪米特原则(最少知道原则): 一个对象应该对其他对象保持最少的了解。
狭义的迪米特法则:如果两个类不必彼此直接通信,那么这两个类就不应当发生直接的相互作用。如果其中一个类需要调用另一类的某一个方法的话,可以通过第三者转发这个调用。
本文来自博客园,作者:mariocanfly,转载请注明原文链接:https://www.cnblogs.com/mariocanfly/p/17429415.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号