Phoenix的二级索引
前言
在Hbase中,只有一个单一的按照字典序排序的rowKey索引,当使用rowKey来进行数据查询的时候速度较快,但是如果不使用rowKey来查询的话就会使用filter来对全表进行扫描,很大程度上降低了检索性能。而Phoenix提供了二级索引技术来应对这种使用rowKey之外的条件进行检索的场景。
Phoenix支持两种类型的索引技术:Global Indexing和Local Indexing,这两种索引技术分别适用于不同的业务场景(主要是偏重于读还是偏重于写)
Global Indexing
Global indexing适用于多读少写的业务场景。使用Global indexing的话在写数据的时候会消耗大量开销,因为所有对数据表的更新操作(DELETE, UPSERT VALUES and UPSERT SELECT),会引起索引表的更新,而索引表是分布在不同的数据节点上的,跨节点的数据传输带来了较大的性能消耗。在读数据的时候Phoenix会选择索引表来降低查询消耗的时间。在默认情况下如果想查询的字段不是索引字段的话索引表不会被使用,也就是说不会带来查询速度的提升。
配置hbase-site.xml
使用Global Indexing的话需要配置hbase-site.xml,在HBase集群的每个regionserver节点的hbase-site.xml中加入如下配置并重启HBase集群。
<property><name>hbase.regionserver.wal.codec</name><value>org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec</value></property>
创建索引
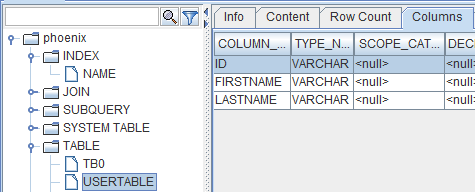
create index my_name on usertable (lastname);
Linux shell

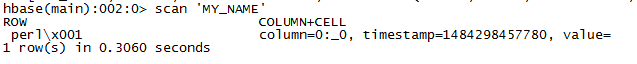
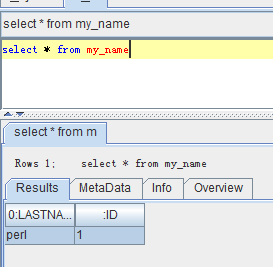
三种方式使Phoenix使用二级索引
强制使用索引表
select /*+ INDEX(USERTABLE MY_NAME) */ * from my_name where lastname = 'perl';
创建covered index
drop index my_name on usertable;create index my_name on USERTABLE(LASTNAME) include (FIRSTNAME)

使用Local Indexing创建索引
Local indexing适用于写操作频繁的场景。
与Global indexing一样,Phoenix会自动判定在进行查询的时候是否使用索引。使用Local indexing时,索引数据和数据表的数据是存放在相同的服务器中的避免了在写操作的时候往不同服务器的索引表中写索引带来的额外开销。
使用Local indexing的时候即使查询的字段不是索引字段索引表也会被使用,这会带来查询速度的提升,这点跟Global indexing不同。
一个数据表的所有索引数据都存储在一个单一的独立的可共享的表中。在读取数据的时候,标红的那句话不会翻译大意就是在读数据的时候因为存储数据的region的位置无法预测导致性能有一定损耗。
配置hbase-site.xml
<property><name>hbase.master.loadbalancer.class</name><value>org.apache.phoenix.hbase.index.balancer.IndexLoadBalancer</value></property><property><name>hbase.coprocessor.master.classes</name><value>org.apache.phoenix.hbase.index.master.IndexMasterObserver</value></property>
<property><name>hbase.coprocessor.regionserver.classes</name><value>org.apache.hadoop.hbase.regionserver.LocalIndexMerger</value></property>
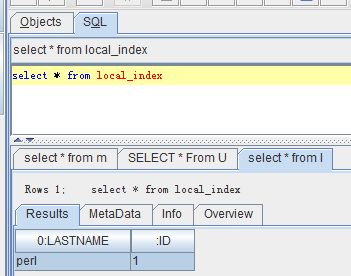
创建local index
create local index local_index on usertable(lastname);
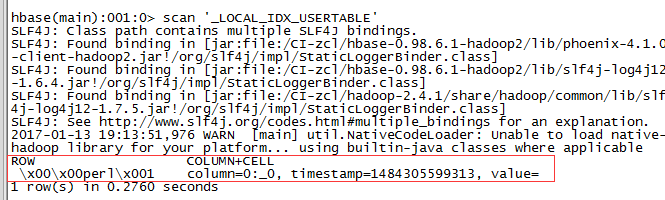
更新表
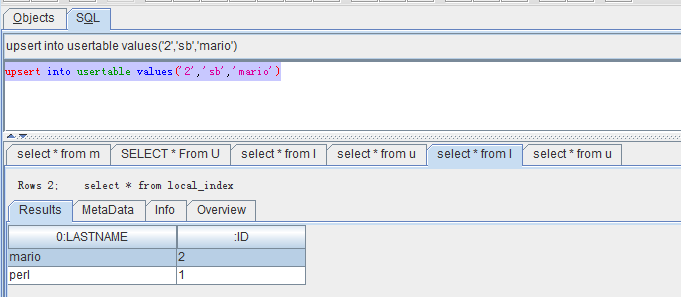
索引表自动更新
mutable 与 inmutable
phoenix将其二级索引技术划分为global and local indexing 2种,但是如果继续往下细分的话又分为
mutable global indexing、mutable local indexing、immutable global indexing、immutable local indexing
一共四种。
默认创建的二级索引为mutable的(mutable global ing或者mutable local indexing)。
immutable类型的索引主要针对的是数据一次入库之后永不改变的场景(only written once and never updated)。
创建Inmutable表
create table company_immutable(id varchar primary key, name varchar, address varchar) IMMUTABLE_ROWS=true;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号