

Windows环境下搭建Hadoop(2.6.0)+Hive(2.2.0)环境并连接Kettle(6.0)
前提:配置JDK1.8环境,并配置相应的环境变量,JAVA_HOME
一.Hadoop的安装
1.1 下载Hadoop (2.6.0) http://hadoop.apache.org/releases.html
1.1.1 下载对应版本的winutils(https://github.com/steveloughran/winutils)并将其bin目录下的文件,全部复制到hadoop的安装目录的bin文件下,进行替换。
1.2 解压hadoop-2.6.0.tar.gz到指定目录,并配置相应的环境变量。
1.2.1 新建HADOOP_HOME环境变量,并将其添加到path目录(;%HADOOP_HOME%\bin)
1.2.2 打开cmd窗口,输入hadoop version 命令进行验证,环境变量是否正常
1.3 对Hadoop进行配置:(无同名配置文件,可通过其同名template文件复制,再进行编辑)
1.3.1 编辑core-site.xml文件:(在hadoop的安装目录下创建workplace文件夹,在workplace下创建tmp和name文件夹)
<configuration> <property> <name>hadoop.tmp.dir</name> <value>/E:/software/hadoop-2.6.0/workplace/tmp</value> </property> <property> <name>dfs.name.dir</name> <value>/E:/software/hadoop-2.6.0/workplace/name</value> </property> <property> <name>fs.default.name</name> <value>hdfs://127.0.0.1:9000</value> </property> <property> <name>hadoop.proxyuser.gl.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.gl.groups</name> <value>*</value> </property> </configuration>
1.3.4 编辑hdfs-site.xml文件
<configuration> <!-- 这个参数设置为1,因为是单机版hadoop --> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/hadoop/data/dfs/namenode</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/hadoop/data/dfs/datanode</value> </property> </configuration>
1.3.5 编辑mapred-site.xml
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapred.job.tracker</name> <value>127.0.0.1:9001</value> </property> </configuration>
1.3.5 编辑yarn-site.xml文件
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> </configuration>
1.4 初始化并启动Hadoop
1.4.1 在cmd窗口输入: hadoop namenode –format(或者hdfs namenode -format) 命令,对节点进行初始化
1.4.2 进入Hadoop安装目录下的sbin:(E:\software\hadoop-2.6.0\sbin),点击运行 start-all.bat 批处理文件,启动hadoop
1.4.3 验证hadoop是否成功启动:新建cmd窗口,输入:jps 命令,查看所有运行的服务,如果NameNode、NodeManager、DataNode、ResourceManager服务都存在,则说明启动成功。
1.5 文件传输测试
1.5.1 创建输入目录,新建cmd窗口,输入如下命令:(hdfs://localhost:9000 该路径为core-site.xml文件中配置的 fs.default.name 路径)
hadoop fs -mkdir hdfs://localhost:9000/user/
hadoop fs -mkdir hdfs://localhost:9000/user/wcinput
1.5.2 上传数据到指定目录:在cmd窗口输入如下命令:
hadoop fs -put E:\temp\MM.txt hdfs://localhost:9000/user/wcinput
hadoop fs -put E:\temp\react文档.txt hdfs://localhost:9000/user/wcinput
1.5.3 查看文件是否上传成功,在cmd窗口输入如下命令:
hadoop fs -ls hdfs://localhost:9000/user/wcinput
1.5.4 前台页面显示情况:
1.5.4 在前台查看hadoop的运行情况:(资源管理界面:http://localhost:8088/)
 1.5.5 节点管理界面(http://localhost:50070/)
1.5.5 节点管理界面(http://localhost:50070/)
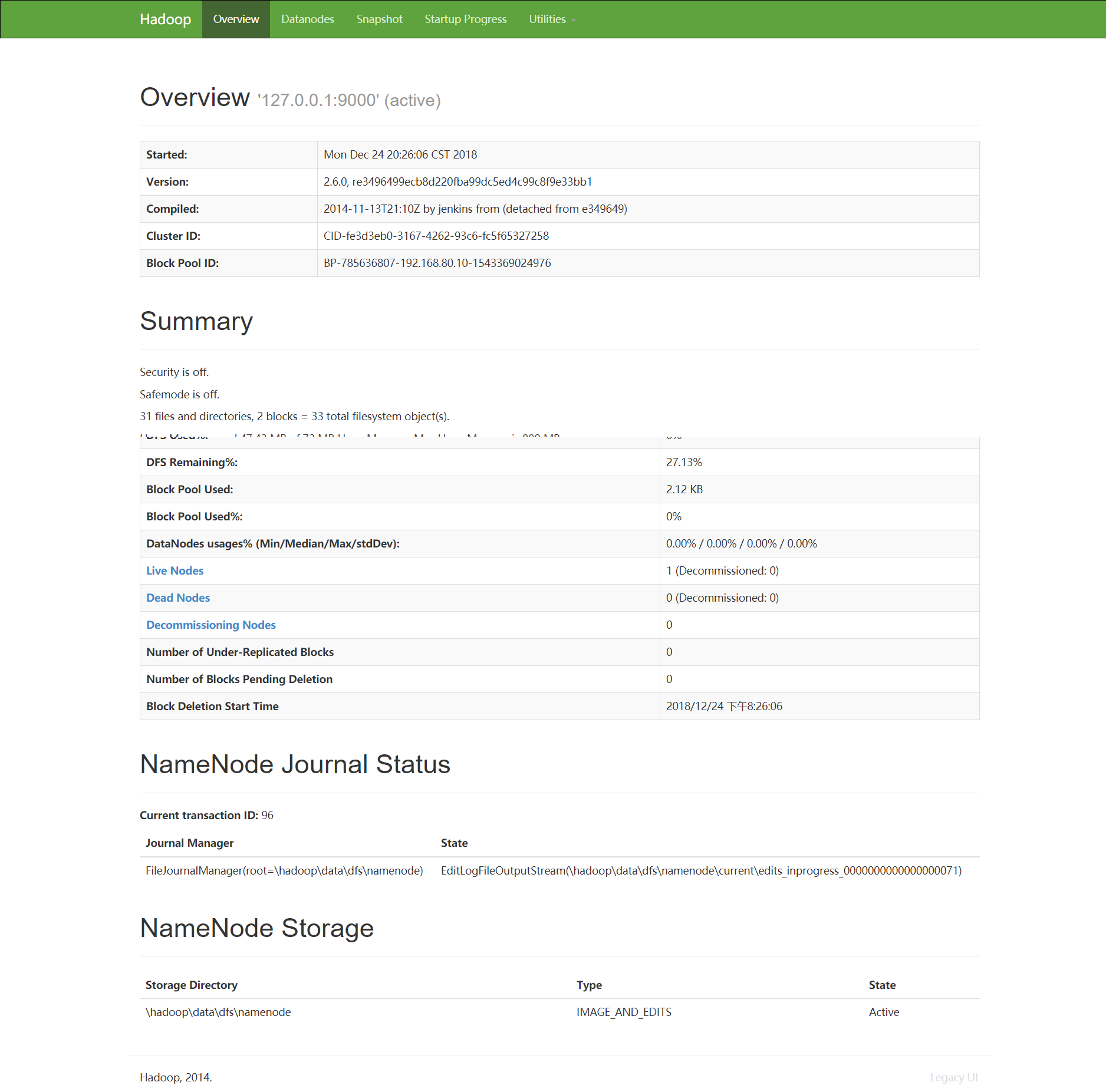
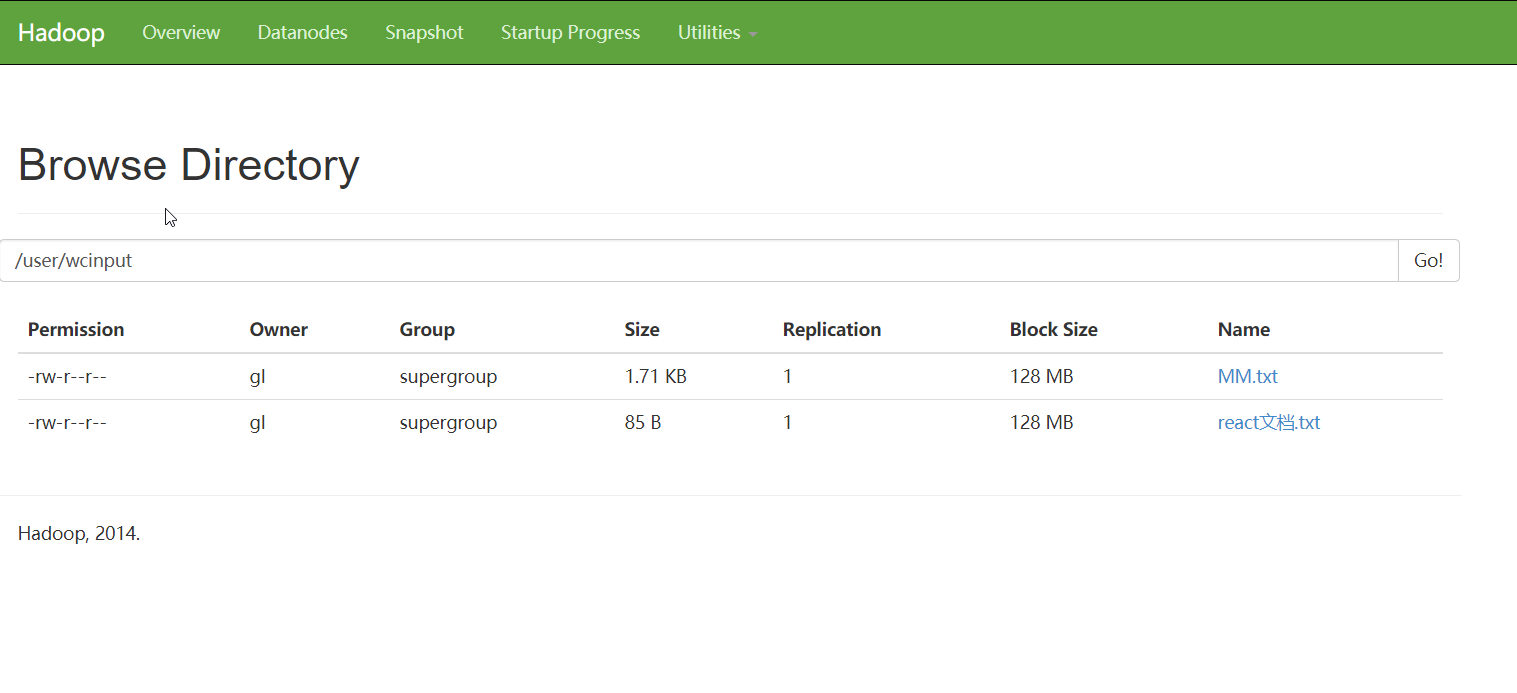
1.5.6 通过前台查看Hadoop的文件系统:(点击进入Utilities下拉菜单,再点击Browse the file system,依次进入user和wcinput,即可查看到上传的文件列表)如下图:
二. 安装并配置Hive
2.1 下载Hive 地址:http://mirror.bit.edu.cn/apache/hive/
2.2 将apache-hive-2.2.0-bin.tar.gz解压到指定的安装目录,并配置环境变量
2.2.1 新建HIVE_HOME环境变量,并将其添加到path目录(;%HIVE_HOME%\bin)
2.2.2 打开cmd窗口,输入hive version 命令进行验证环境变量是否正常
2.3 配置hive-site.xml文件(不解释,可以直接看配置的相关描述)
<property> <name>hive.metastore.warehouse.dir</name> <value>/user/hive/warehouse</value> <description>location of default database for the warehouse</description> </property> <property> <name>hive.exec.scratchdir</name> <value>/tmp/hive</value> <description>HDFS root scratch dir for Hive jobs which gets created with write all (733) permission. For each connecting user, an HDFS scratch dir: ${hive.exec.scratchdir}/<username> is created, with ${hive.scratch.dir.permission}.</description> </property> <property> <name>hive.exec.local.scratchdir</name> <value>E:/software/apache-hive-2.2.0-bin/scratch_dir</value> <description>Local scratch space for Hive jobs</description> </property> <property> <name>hive.downloaded.resources.dir</name> <value>E:/software/apache-hive-2.2.0-bin/resources_dir/${hive.session.id}_resources</value> <description>Temporary local directory for added resources in the remote file system.</description> </property> <property> <name>hive.querylog.location</name> <value>E:/software/apache-hive-2.2.0-bin/querylog_dir</value> <description>Location of Hive run time structured log file</description> </property> <property> <name>hive.server2.logging.operation.log.location</name> <value>E:/software/apache-hive-2.2.0-bin/operation_dir</value> <description>Top level directory where operation logs are stored if logging functionality is enabled</description> </property> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://127.0.0.1:3306/hive?createDatabaseIfNotExist=true</value> <description> JDBC connect string for a JDBC metastore. To use SSL to encrypt/authenticate the connection, provide database-specific SSL flag in the connection URL. For example, jdbc:postgresql://myhost/db?ssl=true for postgres database. </description> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> <description>Driver class name for a JDBC metastore</description> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> <description>Username to use against metastore database</description> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>123</value> <description>password to use against metastore database</description> </property> <property> <name>hive.metastore.schema.verification</name> <value>false</value> <description> Enforce metastore schema version consistency. True: Verify that version information stored in is compatible with one from Hive jars. Also disable automatic schema migration attempt. Users are required to manually migrate schema after Hive upgrade which ensures proper metastore schema migration. (Default) False: Warn if the version information stored in metastore doesn't match with one from in Hive jars. </description> </property> <!--配置用户名和密码--> <property> <name>hive.jdbc_passwd.auth.zhangsan</name> <value>123</value> </property>
2.4 在安装目录下创建配置文件中相应的文件夹:
E:\software\apache-hive-2.2.0-bin\scratch_dir
E:\software\apache-hive-2.2.0-bin\resources_dir
E:\software\apache-hive-2.2.0-bin\querylog_dir
E:\software\apache-hive-2.2.0-bin\operation_dir
2.5 对Hive元数据库进行初始化:(将mysql-connector-java-*.jar拷贝到安装目录lib下)
进入安装目录:apache-hive-2.2.0-bin/bin/,在新建cmd窗口执行如下命令(MySql数据库中会产生相应的用户和数据表)
hive --service schematool
(程序会自动进入***apache-hive-2.2.0-bin\scripts\metastore\upgrade\mysql\文件中读取对应版本的sql文件)
2.6 启动Hive ,新建cmd窗口,并输入以下命令:
启动metastore : hive --service metastore
启动hiveserver2:hive --service hiveserver2
(HiveServer2(HS2)是服务器接口,使远程客户端执行对hive的查询和检索结果(更详细的介绍这里)。目前基于Thrift RPC的实现,是HiveServer的改进版本,并支持多客户端并发和身份验证。
它旨在为JDBC和ODBC等开放API客户端提供更好的支持。)
2.7 验证:
新建cmd窗口,并输入以下 hive 命令,进入hive库交互操作界面:
hive> create table test_table(id INT, name string);
hive> create table student(id int,name string,gender int,address string);
hive> show tables;
student
test_table
2 rows selected (1.391 seconds)
三. 通过Kettle 6.0 连接Hadoop2.6.0 + Hive 2.2.0 大数据环境进行数据迁移
3.1 明确自己hadoop的发行版本,kettle自带的hadoop大致可以分为四种版本:
1. Apache 原生版本
2. Cloudera发行的CDH
3. Google发行的MapR
4. Amazon发行的EMR
5. hortworks发行的hdp
其他需要连接kettle的需要自行将所需要的依赖和配置文件导入到kettle的文件夹下:
E:\software\pdi-ce-6.0.1.0-386\data-integration\plugins\pentaho-big-data-plugin\hadoop-configurations
3.2 配置plugin.properties文件(以前在kettle的相关文档中看到对应的解释)
修改:active.hadoop.configuration=hdp22
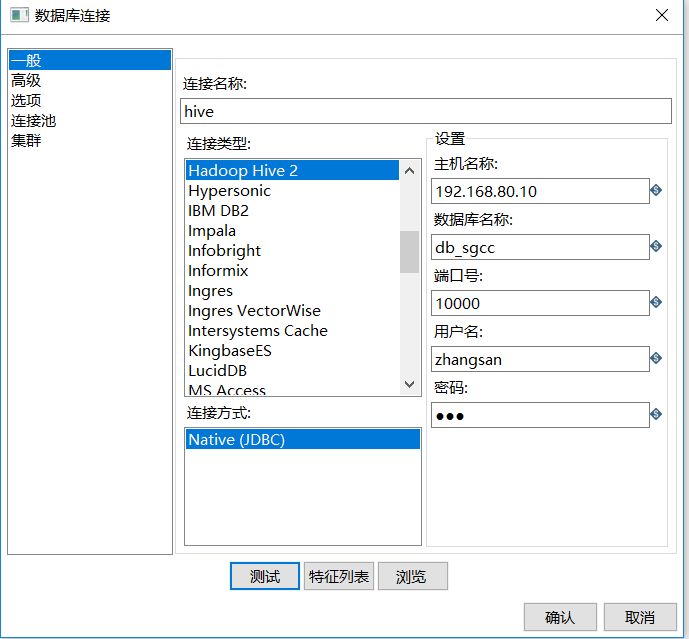
3.3 无需添加任何其他的jar包,开启kettle,并编辑如数据库连接,如下图:
3.4 测试连接,成功,如下图:

搭建Hadoop过程中报错和解决办法:
报错:1. error Couldn't find a package.json file in "***\\hadoop-2.6.0\\sbin
解决:下载webutils覆盖安装目录bin下的文件
报错:2.FATAL org.apache.hadoop.hdfs.server.datanode.DataNode: Initialization failed for Block pool <registering> (Datanode Uuid unassigned) service to localhost ***. Exiting.
org.apache.hadoop.hdfs.server.datanode.DataNode: Initialization failed for Block pool <registering> (Datanode Uuid unassigned) service to node****:9000. Exiting.
java.io.IOException: Incompatible clusterIDs in ****dfs/data: namenode clusterID = CID-9f0a13ce-d7c-****-4d60e63d8392; datanode clusterID = CID-29ff9b68-****-e-aa06-816513a36add
解决:暴力:删除tmp,name,data文件下的所有内容,重新生成,hdfs namenode -format
温柔:将name/current下的VERSION中的clusterID复制到data/current下的VERSION中,覆盖掉原来的clusterID让两个保持一致
报错:3. 执行sbin/start-all.cmd 启动命令
命令行报错:This script is deprecated. Instead use start-dfs.cmd and start - yard.cmd (windows找不到指定文件‘hadoop’)
bin/hadoop dfsadmin -report 查看报错详细信息
解决:
修改配置文件:hdfs-site.xml
修改前配置: <property> <name>dfs.data.dir</name> <value>/E:/software/hadoop-2.6.0/workplace/data</value> </property> 修改后配置: <property> <name>dfs.namenode.name.dir</name> <value>file:/hadoop/data/dfs/namenode</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/hadoop/data/dfs/datanode</value> </property>
搭建Hive和连接Kettle过程中的报错:
报错:1. ERROR [main]: metastore.MetaStoreDirectSql (MetaStoreDirectSql.java:<init>(135)) - Self-test query [select "DB_ID" from "DBS"] failed; direc
t SQL is disabled javax.jdo.JDODataStoreException: Error executing SQL query "select "DB_ID" from "DBS"".
解决:第一次启动hive时,需要对Hive元数据库进行初始化,以上报错因为元数据库初始化有问题导致的。
删除数据库中所有表,重新进行初始化
进入安装目录:apache-hive-2.2.0-bin/bin/,在命令行执行如下命令:hive --service schematool
程序会自动进入***apache-hive-2.2.0-bin\scripts\metastore\upgrade\mysql\文件中读取对应版本的sql文件
报错:2. Error: Could not open client transport with JDBC Uri: jdbc:hive2://hadoop01:10000: Failed to open new session: java.lang.RuntimeException:
org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.authorize.AuthorizationException): User: A is not allowed to impersonate B(state=08S01,code=0)
解决:hadoop目录下/etc/hadoop/core-site.xml加入配置:
<property> <name>hadoop.proxyuser.A.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.A.groups</name> <value>*</value> </property>
(hadoop引入了一个安全伪装机制,使得hadoop 不允许上层系统直接将实际用户传递到hadoop层,而是将实际用户传递给一个超级代理,由此代理在hadoop上执行操作,避免任意客户端随意操作hadoop)
完结。。。。。
posted on 2018-12-25 00:11 mywifelidan 阅读(5430) 评论(4) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号