

爬虫
(1)请用requests库的get()函数访问360主页20次,打印返回状态,text()内容,计算text()属性和content属性所返回网页内容的长度
import requests r=requests.get("http://www.360.com",timeout=30) r.encoding='utf-8' r.raise_for_status() for i in range(20): print(i) print("函数测试输出:\n",r.text) n=len(r.text) m=len(r.content) print("text属性下网页长度为:{},content属性下网页长度为:{}".format(n,m))
结果:
(2)
1、
from bs4 import BeautifulSoup html=BeautifulSoup("<!DOCTYPE html>\n<html>\n<head>\n<meta charset=‘utf-8‘>\n<title>菜鸟教程(runoob.com)</title>\n</head>\n<body>\n<h1>我的第一标题</h1>\n<p id=‘frist‘>我的第一段落。</p>\n</body>\n</table>\n</html>","html.parser") print(html.head,"学号后两位:07")
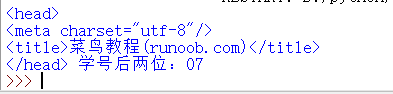
2、

3、

4、

(3)
爬中国大学排名网站内容,http://www.zuihaodaxue.com/zuihaodaxuepaiming2018.html
from bs4 import BeautifulSoup import requests allUniv=[] def getHTMLText(url): try: r=requests.get(url,timeout=30) r.raise_for_status() r.encoding = ‘utf-8‘ return r.text except: return "" def fillUnivList(soup): data = soup.find_all(‘tr‘) for tr in data: ltd = tr.find_all(‘td‘) if len(ltd)==0: continue singleUniv = [] for td in ltd: singleUniv.append(td.string) allUniv.append(singleUniv) def printUnivList(num): print("{1:^2}{2:{0}^10}{3:{0}^6}{4:{0}^4}{5:{0}^10}".format((chr(12288)),"排名","学校名称","省市","总分","培训规模")) for i in range(num): u=allUniv[i] print("{1:^4}{2:{0}^10}{3:{0}^5}{4:{0}^8.1f}{5:{0}^10}".format((chr(12288)),u[0],u[1],u[2],eval(u[3]),u[6])) def main(num): url=‘http://www.zuihaodaxue.cn/zuihaodaxuepaiming2016.html‘ html = getHTMLText(url) soup = BeautifulSoup(html,"html.parser") fillUnivList(soup) printUnivList(num) main(10)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号