One-stage和two-stage
One-stage检测器
几种比较常见的one-stage检测器有YOLO系列和Retinanet等。接下来简要介绍一下这两种结构。
YOLO
Retinanet
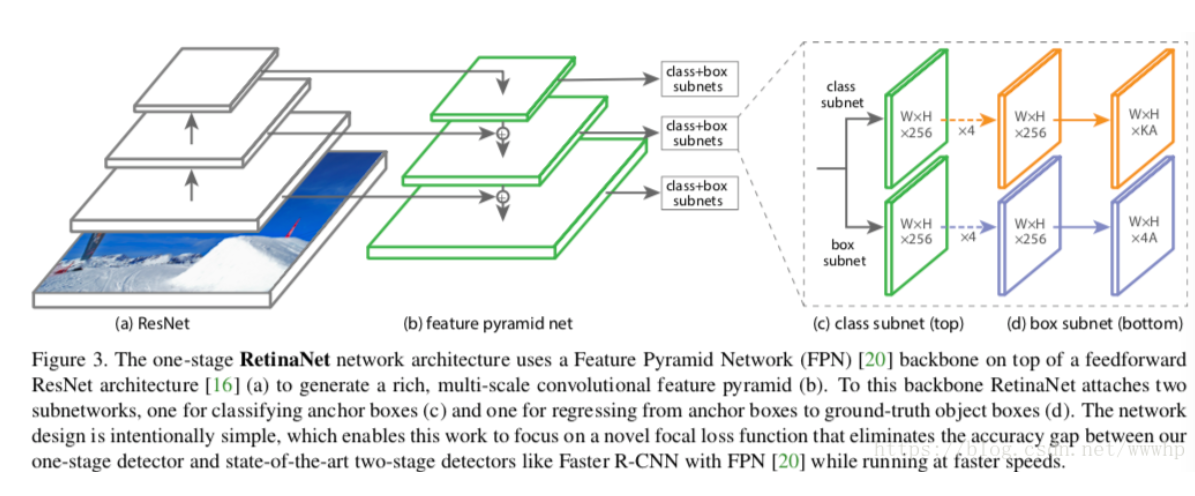
retinanet主要由三部分组成,分别是backbone、FPN和检测器头
1、backbone
在retinanet模型中的backbone大多使用resnet结构进行特征提取
2、FPN
由于现实图片中含有各种目标物体,而这些物体的大小形状各异,结合top to bottom和bottom to top,增加特征映射的分别率能够获得小物体的更多信息,同时结合高层的语义特征和低层的定位信息,最后对于FPN中的每一层进行输出,每一层具有不同的特征映射的分辨率,最后每层进行classification和bbox regression。
3、检测器头
FPN中每一层输出的特征图大小各不相同,也就是每一层的分支中W、H不同,对于one-stage检测器而言,是在每一层FPN的输出特征每一个grid都预设A个anchor,就是每一层FPN输出的特征图的每一个格都定为anchor的中心点,总共预设的anchor就有:W*H*A个anchor。
对于classification分支和bbox regression分支,两个分别进行若干个卷积操作,最后一层卷积操作将通道数分别输出为,在classification分支通道数输出为KA,这个代表的含义是,总共本次目标检测共有K
个类别,因此每一个anchor会输出k维的向量,来表示模型对于这个anchor类别的预测。而在bbox regression分支,最后的通道是输出4A,这是因为bounding box总共有四个参数来表示这个框的位置。
可以看到对于one-stage检测器而言,它是将整幅图的特征图进行提取特征之后对所有目标框和类别进行预测,换句话说就是所有的目标框和类别是来之同时输出的预测类别分数和框的参数是没有映射会特征图的,想要将这些画在图像中主要后期的可视化来实现
two-stage检测器
two-stage检测器主要介绍Faster RCNN
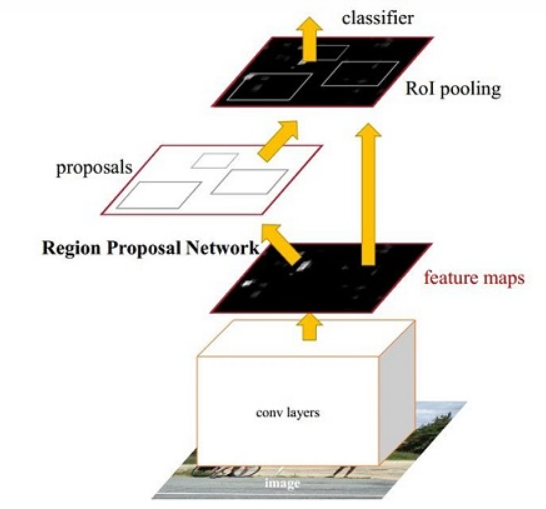
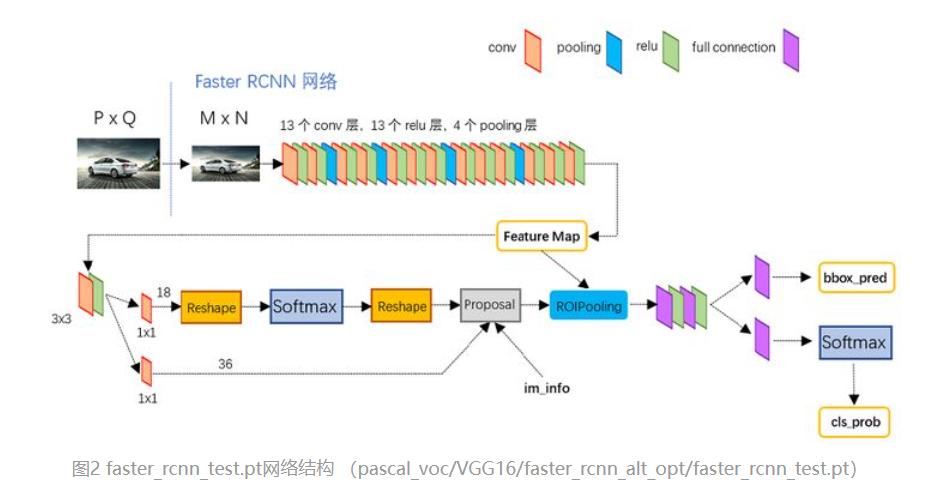
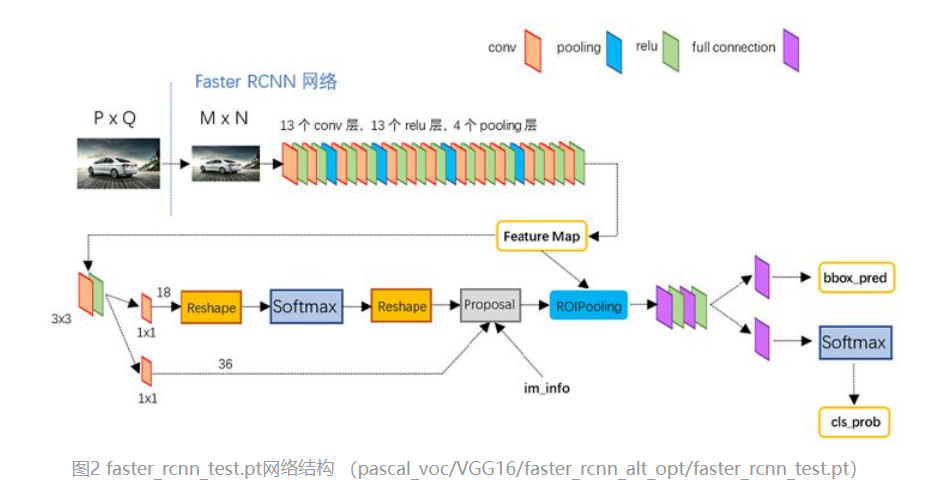
Faster RCNN主要由四部分组成,分别是backbone、RPN、ROI pooling和检测器头
1、backbone
backbone同样是从图片中提取特征的网络结构,包括resnet结构等,在backbone提取特征之后会引出两个分支,分别通往RPN模块,另一个ROI pooling模块
2、RPN
RPN的主要作用就是从特征图中产生可能含有目标物体的候选框以及相应的置信类别,在这里产生的置信类别只有两种,要么是前景要么是背景,而不去细分具体是什么类别。由backbone输出的特征图,经过两个检测头分支进行预测,如上右图,首先各自经过一个1*1的卷积改变特征的通道数,在RPN中的classification通道数改变为18(每个特征点预设框9个,每个分为两类前景和背景),而在bbox regression分支通道数为36(4*9),在classification分支的操作是将特征图reshape为一维的特征图在经过softmax进行预测,最后再reshape为之前的特征图大小。在这两个分支中输出的参数都是对于每一个特征点预设框的参数,他们输出的是框的参数而不是backbone输出框对应位置的特征,而在右图中的proposal模块,就是将classification和regression输出结合起来,删去大部分的背景部分的proposal,最后输出的proposal所占比较小的一部分。
3、ROI pooling
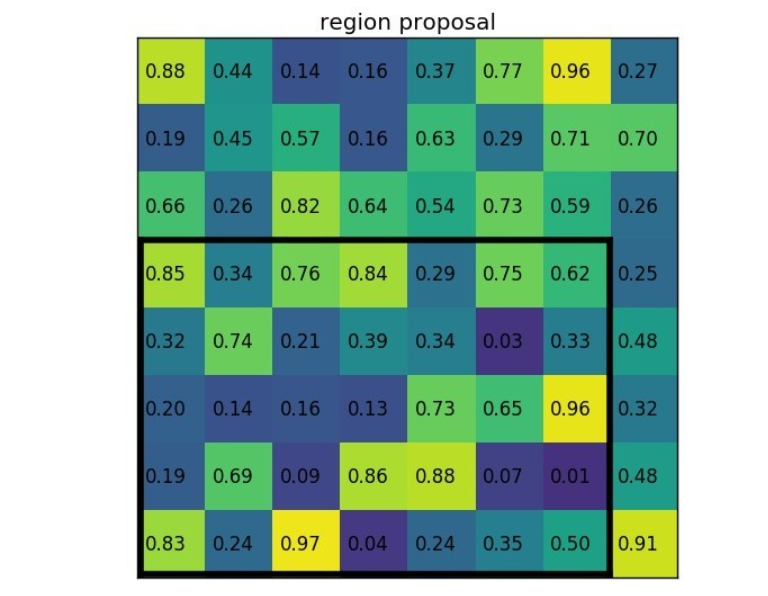
ROI pooling总共有两个输入,分别是backbone和RPN输出,这个分别代表着backbone提取的特征图和这个特征图中可能含有目标物体的候选框,而ROI pooling的操作是首先将这些候选框画在backbone提取的特征图上,之后再将特征图上候选框的区域提取出来,换句话说如上图所示,黑色框包围的就是候选框所涵盖的特征图,将黑色框包围的特征图提取出来,在经过max pooling操作,这样能够使得对于不同大小的候选框经过pooling之后输出是相同大小的特征图,最后将所有候选框对应特征图pooling之后的特征进行拼接在进行classification和regression
可以看到在这里faster RCNN和Retinanet的不同之处,对于Retinanet是将全图的特征图进行检测器头的检测来预测类别和框的偏移,而在faster RCNN是在将候选框区域的特征提取出来在池化为相同纬度之后拼接起来进行预测。
4、检测器头
同one-stage检测器

 浙公网安备 33010602011771号
浙公网安备 33010602011771号