面向对象设计与构造 第三单元总结
面向对象设计与构造 第三单元总结
写在前面
不能大意!不能大意!不能大意!(重要的事情说三遍
第三单元主要内容是JML规格的理解与编程,看似比前面两个单元简单许多,但是还存在很多隐藏坑点的。五一假期刚拿到这单元第一次作业时,我大意了啊,让一个qbs给偷家了orz。而且,第二次作业又让我体验到了人间疾苦,时间优化力度不够也还是照样tle。好在痛定思痛,在第三次作业把所有坑点全扫了一遍,总算是没问题了。
JML规格能够给编程带来比较直观的向导作用,但是JML使用的实现方式未必是最好的方式,很多的细节比如数据存储、遍历、查找方式,都需要我们自己考虑。而且这一单元的作业,更加要求充分的自主测试,考验了数据构造能力。
下面就来详细说说这三次作业的坑点与我的解决方式。
设计策略
三次作业的内容都包含异常类以及关系类两个部分,一般我选择先解决相对简单的异常类,再去搞定相对复杂的关系类。
异常类
异常类官方不提供规格,需要按照指导书要求实现。这部分的内容相对独立,根据官方要求,只要在异常类中使用static变量存储触发次数即可。由于要记录每个id对应的触发次数,id -> trigger times是很明显的键值对结构,直接List或者HasMap顶上就行,这里我是用HashMap(具体原因后面说)。
关系类
社交关系相对复杂,要求我们要通读JML,形成一个比较具象的关系网,了解每个person之间的联系存在方式以及交互方式。设计时,要从宏观着手,然后推进到细节的实现,主要可以从以下几个方面着手:
类的用途与类之间的联系
在拿到官方包感觉十分混乱的时候,不妨先看看每个类的主要用途是什么。Person用来记录每个人的相关信息,Message是发出的每条信息的属性,Network记录人与人之间的关系以及信息收发记录......大致明确每个类的功能,可以帮助梳理宏观程序的工作方式。
数据存储方式
不同的数据存储方式意味着不同的时间、空间开销,本单元对运行时间的要求较高,尤其是前两次作业。因此,本着时间优先的原则,我们应该首选“较快”的数据容器。但是同时也要注意,有些方法要求我们存储时记录存储的顺序,比如Person的getReceivedMessages()方法:
/*@ public normal_behavior
@ assignable \nothing;
@ ensures (\forall int i; 0 <= i && i < messages.length && i <= 3;
@ \result.contains(messages[i]) && \result[i] = messages[i]);
@ ensures \result.length == (messages.length < 4)? messages.length: 4;
*/
public /*@pure@*/ List<Message> getReceivedMessages();
这里我最终选择LinkedList,主要考虑messages涉及的Network中关于查询的方法较少,使用LinkedList不会造成太大的性能影响。
方法规格的实现方式
主要原则就是“由简入难”。
对于一些简单的查询、添加方法,在确定使用的容器后可以直接return容器的size。Network中某些添加方法的JML规格可能比较冗长,比如addMessage():
/*@ public normal_behavior
@ requires !(\exists int i; 0 <= i && i < messages.length; messages[i].equals(message)) &&
@ (message instanceof EmojiMessage) ==> containsEmojiId(((EmojiMessage) message).getEmojiId()) &&
@ (message.getType() == 0) ==> (message.getPerson1() != message.getPerson2());
@ assignable messages;
@ ensures messages.length == \old(messages.length) + 1;
@ ensures (\forall int i; 0 <= i && i < \old(messages.length);
@ (\exists int j; 0 <= j && j < messages.length; messages[j] == (\old(messages[i]))));
@ ensures (\exists int i; 0 <= i && i < messages.length; messages[i] == message);
@*/
主要意思就是在messages中添加传入的message参数,本质上再不出发异常的情况下,一句简单的messages.put(message.getId(), message);就可以搞定了(添加方式取决于messages的容器类型)。
JML一般包含normal behavior以及exceptional behavior,可以先处理触发异常的情况,之后再处理正常情况。编写一般情况时,要注意方法之间的联系,当调用另一个方法是,要考虑这个方法的实现机制是什么、复杂度如何、在这里会不会超时、是否有关系漏洞等问题。
测试设计方法与策略
设计测试主要可以从单元测试、集成测试、系统测试三个层次来考虑,本单元作业规格相对不是非常复杂加之我没咋弄明白系统测试,我的测试就主要侧重于前两者。
单元测试
单元测试主要就是对几个比较容易出问题的模块进行形式验证,判断实现的内容是否与规格的要求一致,主要使用到的工具是JUnit。我们可以对一个方法列举所有可能的结果,然后使用assert断言来判断方法是否达到了我们预期的结果。
举个例子,还是Network中的addMessage()方法,可以构造以下四种情况:
· 参数message存在于messages容器;
· 参数message不存在于messages容器,且是不存在于emojiMessages容器的emojiMessage;
· 参数message不存在于messages容器,type为0且person1等于person2;
· 参数message不是emojiMessage,不存在于messages容器,person1不等于person2;
· 参数message是emojiMessage,存在于emojiMessage容器,不存在于messages容器,person1不等于person2
以上message触发的结果依次是:EqualMessageIdException,EmojiIdNotFoundException,EqualPersonIdException,添加成功,添加成功。通过assert语句来判断mesages容器的size是否与我们的预期一致,就可以完成对这一单元块的功能测试。
以下为Network单元测试简单示例代码(有删减,不保证能运行):
public class MyNetworkTest {
private Network myNet;
@BeforeClass
public static void beforeClass() {
System.out.println("---before class---");
}
@AfterClass
public static void afterClass() {
System.out.println("---after class---");
}
@Before
public void setUp() throws Exception {
myNet = new MyNetwork();
Person p1 = new MyPerson(1, "Yue", new BigInteger("123"), 19);
Person p2 = new MyPerson(2, "He", new BigInteger("456"), 21);
try {
myNet.addPerson(p1);
myNet.addPerson(p2);
} catch (EqualPersonIdException e) {
e.print();
}
System.out.println("---before test---");
}
@After
public void tearDown() throws Exception {
System.out.println("---after test---");
}
@Test
public void contains() {
assertTrue(myNet.contains(1));
assertFalse(myNet.contains(3));
}
@Test(expected = EqualPersonIdException.class)
public void addPerson() throws EqualPersonIdException {
Person p1 = new MyPerson(1, "YueYang", new BigInteger("123"), 19);
myNet.addPerson(p1);
}
@Test
public void addRelation() throws EqualRelationException, PersonIdNotFoundException {
myNet.addRelation(1, 2, 20);
}
}
集成测试
集成测试建立在单元测试之上,通过构造随机数据,利用python自带的关系库或者程序对拍,检验程序正确性;通过构造复杂度情况最高的测试数据,配合JProfiler或者JVVM来检测程序的性能。
前两次作业都是自己手动构造数据,所以测试做的比较少,直接导致了第二次作业tle+wa,爆了3个点。第三次作业厚着脸皮借来了大佬的评测机与数据生成器,在此感谢@ljk凯哥的帮助!
容器选择与使用
容器选择
由于本单元对时间性能的要求非常严格(CPU时间2s,2s,6s),但是内存允许使用的容量比较大(>500MB),容器选择的策略采用“空间换时间”。
主流使用的容器主要为Map、Set、List、Queue,这三种容器又都有各自的代表HasMap、HashSet、LinkedList、PriorityQue。这里我们主要区分HashMap以及LinkedList。
LinkedList实现了List接口,底层使用的是使用双向链表的形式,存储的数据在空间上很可能不相邻,但是他们都有一个引用连在一起,所以增删起来会很方便。但是,在LinkedList中查找元素时,需要花费较多时间进行遍历,在出现大批量遍历相关指令的时候,很容易造成tle。
HashMap底层使用的是Hash算法存储数据,将数据以键值对的方式离散地存储。由于对key进行hash计算得到的值不连续,value的添加和保存顺序也是不一致的,这就导致了HashMap存储的无序性。但是通过hash计算得到下标的方式从底层上避免了List寻找元素时的遍历,查询的时间复杂度趋近于O(1),大大提高了查询的效率。
因此,我们在存储数据的时候,尽量使用HashMap实现JML规格。
Person中,建立id -> Person的acquaintanceMap,建立id -> value的valueMap,方便在Network中的isCircle(),queryValue(),queryCircle()等方法中快速搜索结果。记录messages时由于对元素顺序有要求,使用LinkedList进行存储。
Network中,能够使用id -> type这类键值对的容器,同理也全部使用HashMap实现。
HashMap删除元素
HashMap删除元素时不能直接在循环中remove,推荐使用的迭代器删除:
//声明map集合
Map<String,String> PubJudgeGroupRelationList = new HashMap<>();
//迭代器循环
Iterator<Entry<String, String>> iter = PubJudgeGroupRelationList.entrySet().iterator();
while (iter.hasNext()) {
Map.Entry<String, String> info = iter.next();
System.out.println("循环"+info.getKey()+"/"+info.getValue());
//判断key值.equals(值) 如果等于就删除这个key
if (info.getKey().equals(“1024”)) {
iter.remove();
}
}
如果判断条件比较简单,也可以使用HashMap的removeif()方法:
emojiIdHeat.entrySet().removeIf(entry -> entry.getValue() < limit);
HashMap遍历
此外,在对HashMap遍历的时候,不同的遍历方式也会带来不同的时间复杂度。举个例子,如果对map.values()进行遍历,会先遍历整个map获得values集合,然后再对此集合进行遍历,此时就会有一个隐藏的O(n)复杂度存在。
for each map.entrySet()
Map<String, String> map = new HashMap<String, String>();
for (Entry<String, String> entry : map.entrySet()) {
entry.getKey();
entry.getValue();
}
显示调用map.entrySet()的集合迭代器
Iterator<Map.Entry<String, String>> iterator = map.entrySet().iterator();
while (iterator.hasNext()) {
Map.Entry<String, String> entry = iterator.next();
entry.getKey();
entry.getValue();
}
for each map.keySet(),再调用get获取
Map<String, String> map = new HashMap<String, String>();
for (String key : map.keySet()) {
map.get(key);
}
for each map.entrySet(),用临时变量保存map.entrySet()
Set<Entry<String, String>> entrySet = map.entrySet();
for (Entry<String, String> entry : entrySet) {
entry.getKey();
entry.getValue();
}
通过改变map大小进行代码测试,我们最终得到如下结果:
compare loop performance of HashMap
-----------------------------------------------------------------------
map size | 10,000 | 100,000 | 1,000,000 | 2,000,000
-----------------------------------------------------------------------
for each entrySet | 2 ms | 6 ms | 36 ms | 91 ms
-----------------------------------------------------------------------
for iterator entrySet | 0 ms | 4 ms | 35 ms | 89 ms
-----------------------------------------------------------------------
for each keySet | 1 ms | 6 ms | 48 ms | 126 ms
-----------------------------------------------------------------------
for entrySet=entrySet()| 1 ms | 4 ms | 35 ms | 92 ms
-----------------------------------------------------------------------
综合测试结果与实际使用体验来看,选择使用entrySet遍历Map,能够更加高效。
易出现的性能问题
isCircle()、queryBlockSum()
要想判断两人是否有联系,必须要调用isCircle()。如果完全按照规格来实现,isCircle()中存在循环嵌套,复杂度达到了O(n2)。此外,queryBlockSum()中存在循环中调用isCircle()方法,复杂度更是达到了O(n3)。
最基本的想法是dfs或者bfs,但是搜索算法本质上还是在遍历,在图的size比较大的情况下也是有超时风险。
解决方法
普通版
在Network中添加一个id -> Hashset<id>的RelationMap用来记录people中每个人有联系的人的集合。
private HashMap<Integer, HashSet<Integer>> relation;
在addPerson()时添加参数person的关系集
relation.put(person.getId(), temp);
在每次addRelation()更新关系时,更新relation的集合。
((MyPerson) getPerson(id1)).addAcquaintance((MyPerson) getPerson(id2), value);
((MyPerson) getPerson(id2)).addAcquaintance((MyPerson) getPerson(id1), value);
HashSet<Integer> set1 = relation.get(id1);
HashSet<Integer> set2 = relation.get(id2);
if (!set1.equals(set2)) {
set1.addAll(set2);
for (int id : set2) {
relation.put(id, set1);
}
}
最后,在isCircle()中查询是否联通时,只需要查找id1的关系集合中是否包含id2即可,这样就可以将O(n^2)的复杂度下降到O(1)。
return relation.get(id1).contains(id2);
queryBlockSum()中只要将所有的集合去重相加(通过collection与set完成,set作为集合不允许出现重复元素,,故可以用来去重),获取size即可知道有多少联通块。
Collection<HashSet<Integer>> temp = relation.values();
Set<HashSet<Integer>> allBlocks = new HashSet<>(temp);
return allBlocks.size();
绝杀版
虽然通过记录人的联系集可以降低时间占用,但是在对relation遍历去重的时候,还是需存在O(n)的复杂度。我们可以直接新建一个qbs的int型成员变量,在addPerson()时,新加的人还未与其他人有联系,本身就是一个联通块,qbs++;addRelation时,每个人一旦与其他人建立联系了,这两个人的构成一个联通块,qbs--;最终,在queryBlockSum()时直接返回qbs即可。isCircle()依旧维持O(n)的复杂度,但是queryBlockSum()的复杂度直接去到O(1)。具体实现比较简单就不展示了。
queryGroupValueSum()
按照原规格,复杂度会达到O(n^2),在重复调用的时候有超时风险。主要原因就是在查询value的时候一直在枚举people中每个person的acquaintance,存在双层循环嵌套。
解决方式
利用对边的枚举,取代对people中人的枚举。新建edgesMap,记录每条边的节点与value,在addRelation()时更新edges;qgvs指令发出时枚举edgesMap,可以将O(n^2)的复杂度降低为O(n)。
sendIndirectMessage()
这个方法最大的坑点,就是这一段规格:
@ ensures (\exists Person[] pathM;
@ pathM.length >= 2 &&
@ pathM[0].equals(\old(getMessage(id)).getPerson1()) &&
@ pathM[pathM.length - 1].equals(\old(getMessage(id)).getPerson2()) &&
@ (\forall int i; 1 <= i && i < pathM.length; pathM[i - 1].isLinked(pathM[i]));
@ (\forall Person[] path;
@ path.length >= 2 &&
@ path[0].equals(\old(getMessage(id)).getPerson1()) &&
@ path[path.length - 1].equals(\old(getMessage(id)).getPerson2()) &&
@ (\forall int i; 1 <= i && i < path.length; path[i - 1].isLinked(path[i]));
@ (\sum int i; 1 <= i && i < path.length; path[i - 1].queryValue(path[i])) >=
@ (\sum int i; 1 <= i && i < pathM.length; pathM[i - 1].queryValue(pathM[i]))) &&
@ \result==(\sum int i; 1 <= i && i < pathM.length; pathM[i-1].queryValue(pathM[i])));
先不谈循环中可能涉及的操作,单看JML就能目测出复杂度至少在O(n^2)之上。想要解决这个问题,首先得看懂这段代码在干什么。在给定的id1与id2之间,规格求出了所有路径的权值,然后选择的权值最低的那一条路径,将这条路径的权值返回。换而言之,就是要求我们寻找最短带权路径(而且这里每条边的权值都大于0)
解决方式
现在问题已经很清晰了,求最短带权路径,而且边的权值都大于0,首选Dijkstra算法。
Dijkstra算法
迪杰斯特拉(Dijkstra)算法是典型最短路径算法,用于计算一个节点到其他节点的最短路径。 它的主要特点是以起始点为中心向外层层扩展(广度优先搜索思想),直到扩展到终点为止。朴素的Dijkstra算法时间复杂度为O(n^2)。
/*
* Dijkstra最短路径。
* 即,统计图中"顶点vs"到其它各个顶点的最短路径。
*
* 参数说明:
* vs -- 起始顶点(start vertex)。即计算"顶点vs"到其它顶点的最短路径。
* prev -- 前驱顶点数组。即,prev[i]的值是"顶点vs"到"顶点i"的最短路径所经历的全部顶点中,位于"顶点i"之前的那个顶点。
* dist -- 长度数组。即,dist[i]是"顶点vs"到"顶点i"的最短路径的长度。
*/
public void dijkstra(int vs, int[] prev, int[] dist) {
// flag[i]=true表示"顶点vs"到"顶点i"的最短路径已成功获取
boolean[] flag = new boolean[mVexs.length];
// 初始化
for (int i = 0; i < mVexs.length; i++) {
flag[i] = false; // 顶点i的最短路径还没获取到。
prev[i] = 0; // 顶点i的前驱顶点为0。
dist[i] = mMatrix[vs][i]; // 顶点i的最短路径为"顶点vs"到"顶点i"的权。
}
// 对"顶点vs"自身进行初始化
flag[vs] = true;
dist[vs] = 0;
// 遍历mVexs.length-1次;每次找出一个顶点的最短路径。
int k=0;
for (int i = 1; i < mVexs.length; i++) {
// 寻找当前最小的路径;
// 即,在未获取最短路径的顶点中,找到离vs最近的顶点(k)。
int min = INF;
for (int j = 0; j < mVexs.length; j++) {
if (flag[j]==false && dist[j]<min) {
min = dist[j];
k = j;
}
}
// 标记"顶点k"为已经获取到最短路径
flag[k] = true;
// 修正当前最短路径和前驱顶点
// 即,当已经"顶点k的最短路径"之后,更新"未获取最短路径的顶点的最短路径和前驱顶点"。
for (int j = 0; j < mVexs.length; j++) {
int tmp = (mMatrix[k][j]==INF ? INF : (min + mMatrix[k][j]));
if (flag[j]==false && (tmp<dist[j]) ) {
dist[j] = tmp;
prev[j] = k;
}
}
}
// 打印dijkstra最短路径的结果
System.out.printf("dijkstra(%c): \n", mVexs[vs]);
for (int i=0; i < mVexs.length; i++)
System.out.printf("shortest(%c, %c)=%d\n", mVexs[vs], mVexs[i], dist[i]);
}
可能有读者会发现,朴素Dijkstra算法的时间复杂度和JML规格的复杂度好像差不多都是O(n^2),那还谈何优化呢?确实,通过JVVM计时,朴素的Dijstra算法在跑一组极限数据的时候,时间超过了7000ms(强测不会用这种数据,放心)。因此,我们要对朴素算法进行优化,主要有两种思路,一种是优化遍历方式,一种是利用minHeap小顶堆。
优化遍历方式
我最终采用的是优化遍历方式,主要看中这种方法对于代码的改动最少,同时性能也接近堆优化(不比heap慢,在跑极限数据的时候还比堆优化快500ms左右)。从上面的算法模板来看,Dijkstra算法记录每个节点是否被访问,然后对所有节点进行bfs遍历,但是我们的测试数据规模比较小,每个节点联系的节点数较少,我们不妨在找到最短权值时,记录与当前节点相连的下一节点,记为prev前驱节点,每次循环只需要遍历前驱节点的acquaintanceMap即可,复杂度约为O(n*logn)。我们可以看下优化后的算法思路。
首先,将前驱节点指向id1,遍历与id1直接相连的节点,将这3个节点与对应权值加到bufferMap中。之后,遍历bufferMap,将其中带权值最小的节点取出,移动到distanceMap中,此时这个节点对应的值就是id1到它的最低路径权值。
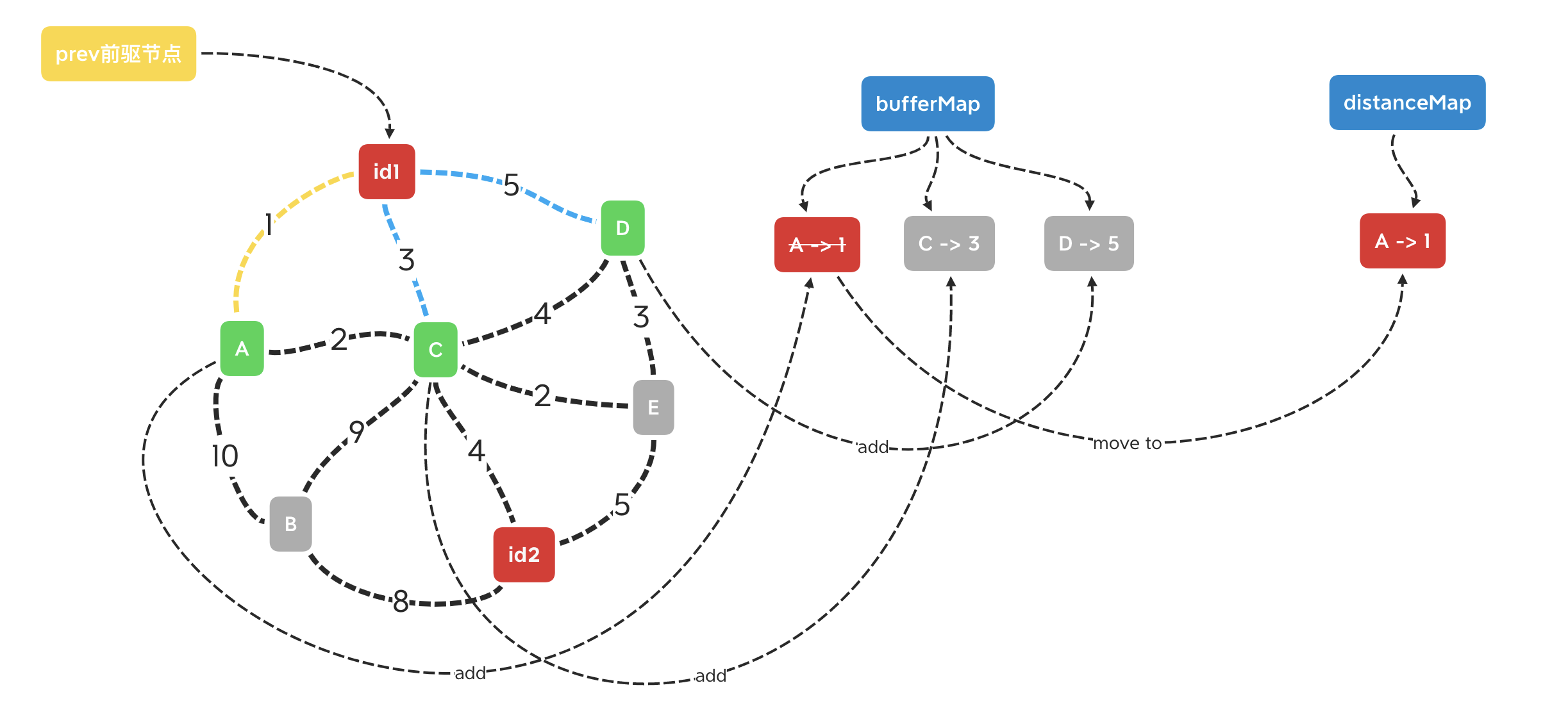
之后,将与上一过程取出的新节点作为前驱节点,遍历它的acquaintance并添加到bufferMap。C节点已经存在于bufferMap中,这里新的路径是A -2-> C,此时C的值为1 + 2 = 3,与上一次遍历的值相等,则bufferMap不更新C的值(如果得到的节点存在于bufferMap且权值低于map记录的值,则更新map)。再次遍历bufferMap,将最小的权值节点转移到distanceMap中。
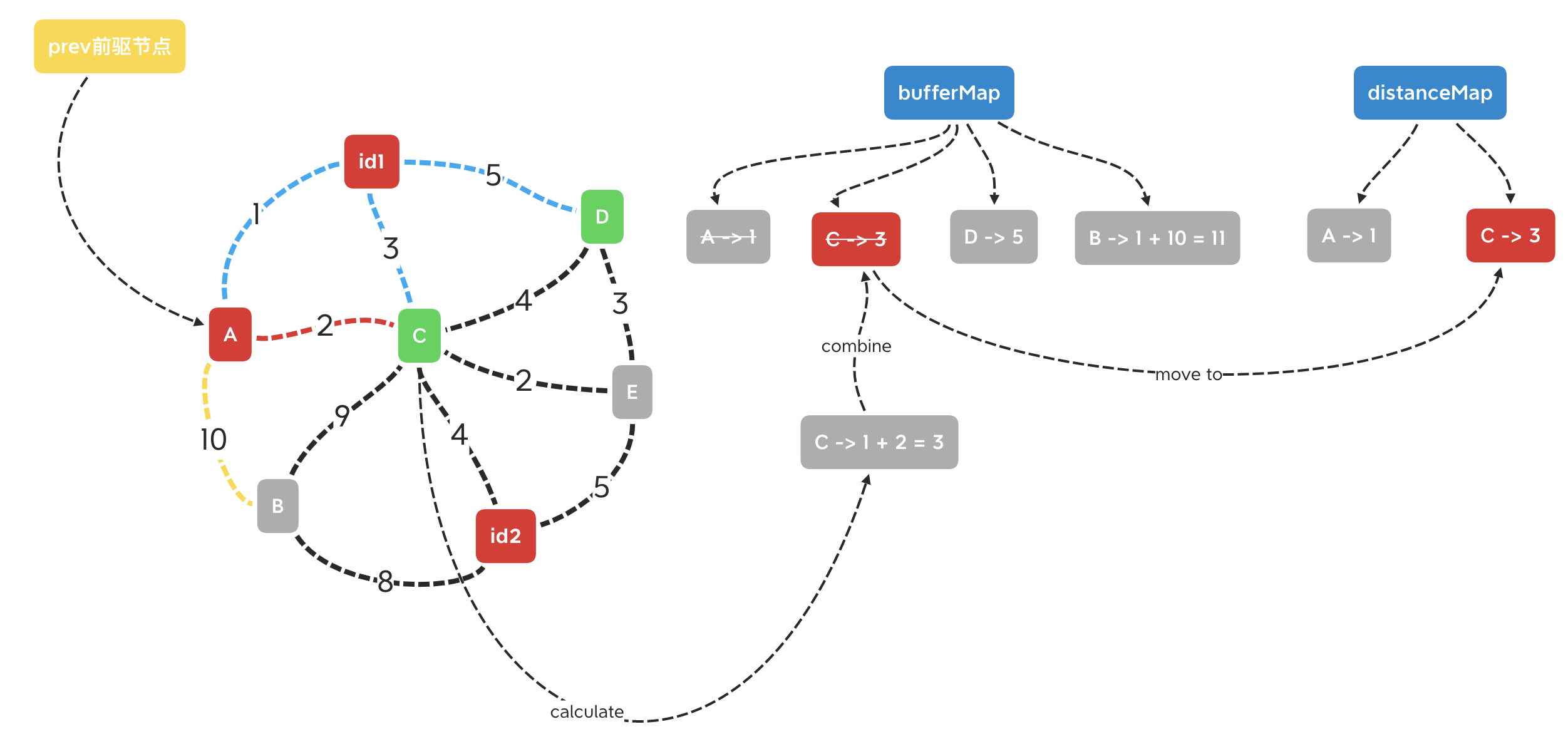
对以上操作不断循环,直至找到id2节点,返回id2对应的权值,就是我们找的最短路径权了。
minHeap小顶堆优化
小顶堆优化的核心就是简化寻找bufferMap中最小元素的过程,通过在添加元素时进行二叉树整理,将最小的权值节点放在最顶层,在寻找最小元素时直接返回顶端节点,可将内层循环复杂度从O(n)降低为O(logn),最终复杂度为O(n*logn)。
堆优化在@qlh大佬的帮助下我也尝试实现了,但是最终还是使用了上面那个方法,就简单放下小顶堆的代码吧。
public class HeapMin {
private int size;
private HashMap<Integer, Integer> idValue;
private HashMap<Integer, Integer> indexId;
private HashMap<Integer, Integer> idIndex;
public HeapMin() {
size = 0;
idValue = new HashMap<>();
indexId = new HashMap<>();
idIndex = new HashMap<>();
}
// 新元素push到堆中,将它添加到二叉树末尾叶节点,再将他上浮,直至他的父节点权值比他小为止
public void push(int pid, int value) {
idIndex.put(pid, size);
indexId.put(size, pid);
idValue.put(pid, value);
upward(size++);
}
// 对于堆中已有节点的权值进行更新,更新的前提是新的权值小于原权值,put操作后依旧需要上浮元素
public void replace(int pid, int value) {
idValue.put(pid, value);
upward(idIndex.get(pid));
}
// 返回顶层最小元素的id与权值,同时将最后一个叶节点放置于头节点,再按照权值大小进行下沉
public LinkedList<Integer> pop() {
LinkedList<Integer> buf = new LinkedList<>();
int pid = indexId.get(0);
int value = idValue.get(pid);
buf.add(pid);
buf.add(value);
idValue.remove(pid);
swap(0, --size);
indexId.remove(size);
idIndex.remove(pid);
downward(0);
return buf;
}
// 上浮操作
public void upward(int index) {
int son = index;
int dad = (son - 1) / 2;
while (dad >= 0) {
if (idValue.get(indexId.get(son)) >= idValue.get(indexId.get(dad))) {
break;
} else {
swap(son, dad);
son = dad;
dad = (son - 1) / 2;
}
}
}
// 下沉操作
public void downward(int index) {
int temp = index;
int son = temp * 2 + 1;
while (son < size) {
if (son + 1 < size && idValue.get(indexId.get(son + 1)) <
idValue.get(indexId.get(son))) {
son++;
}
if (idValue.get(indexId.get(temp)) >= idValue.get(indexId.get(son))) {
swap(temp, son);
temp = son;
son = temp * 2 + 1;
} else {
break;
}
}
}
// 元素位置交换
public void swap(int num1, int num2) {
int pid1 = indexId.get(num1);
int pid2 = indexId.get(num2);
indexId.put(num1, pid2);
indexId.put(num2, pid1);
idIndex.put(pid1, num2);
idIndex.put(pid2, num1);
}
public boolean contains(int pid) {
return (idValue.get(pid) != null);
}
public int getValue(int pid) {
return idValue.get(pid);
}
}
作业架构与维护
UML类图

程序中实现的方法JML规格中都有,这里只展示我使用到的数据存储方式。
架构维护
主要架构以及重点时间优化在之前已经讲过了,这里就拿Network稍微说说吧。
MyNetWork
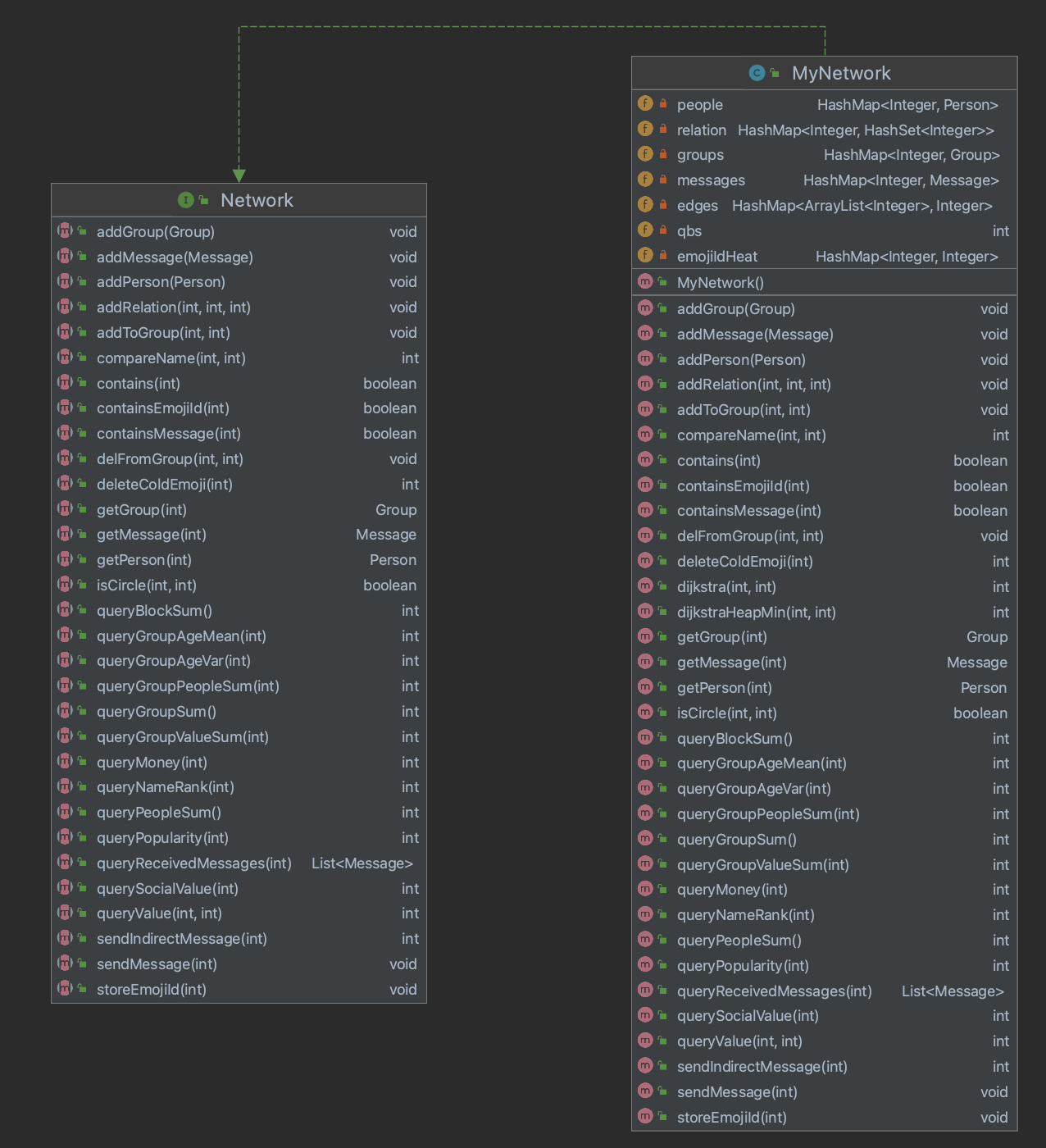
Network里我主要维护的对象,除了JML中的people,messages之外,还有relations以及edges,分别记录人与人的关系以及节点之间的权值。
relation
在构造器中初始化,addPerson()时添加新成员到relation中,addRelation()时更新id1与id2的关系集合。
edges
在构造器中初始化,addRelation()时更新id1与id2的边与权重,在queryGroupValueSum()时对edges遍历,获得权值总和。
心得体会
这一单元的作业看似相对简单,但是对阅读规格的能力要求很高,同时也对数据结构相关知识有一个考察。前两次作业我确实大意了,没有仔细的去做测试,也直接导致了强测炸裂。以后要引以为戒啊。
附带上我写第三次作业时,看到的一个比较好的Dijkstra算法讲解:https://blog.csdn.net/sunstar8921/article/details/81203445

 浙公网安备 33010602011771号
浙公网安备 33010602011771号