.是任意字符 可以匹配任何单个字符。
例子:正则表达式c.r 可以匹配这些字符串:car、cur、c r,但是不匹配root。
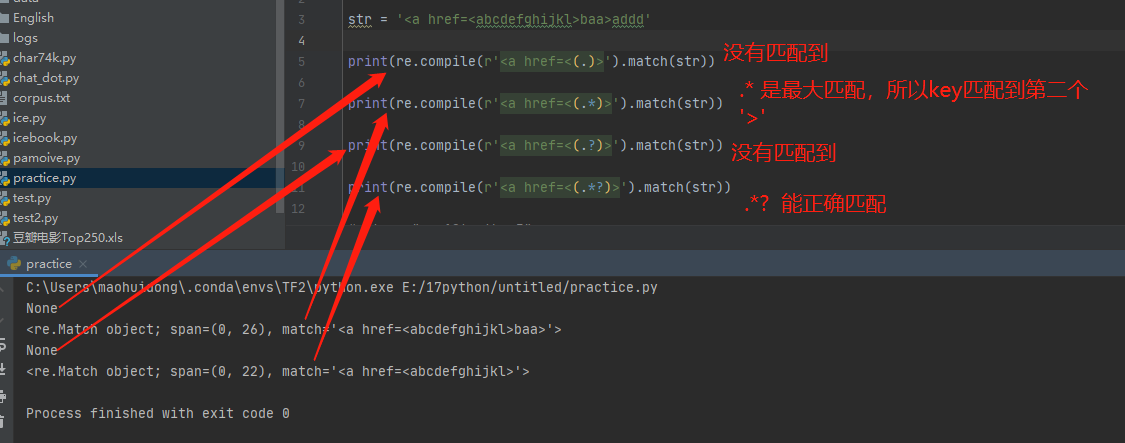
*匹配0或多个正好在它之前的那个字符。例如正则表达式。*意味着能够匹配任意数量的任何字符。?匹配0或1个正好在它之前的那个字符。注意:这个元字符不是所有的软件都支持的。.*是指任何字符0个或多个,.?是指任何字符0个或1个。
?表示非贪婪模式,即为匹配最近字符 如果不加?就是贪婪模式a.*bc 可以匹配 abcbcbc 。
.* 具有贪婪的性质,首先匹配到不能匹配为止,根据后面的正则表达式,会进行回溯。.*?则相反,一个匹配以后,就往下进行,所以不会进行回溯,具有最小匹配的性质。
.*? 表示匹配任意字符到下一个符合条件的字符
例子:正则表达式a.*?bbb 可以匹配 acbbb abbbbb accccccccbbb
正则表达式模式
由于正则表达式通常都包含反斜杠,所以你最好使用原始字符串来表示它们。模式元素(如 r’\t’,等价于 \t )匹配相应的特殊字符
下面列出了正则表达式模式语法中的特殊元素。如果你使用模式的同时提供了可选的标志参数,某些模式元素的含义会改变
1、^:匹配字符串的开头
2、$:匹配字符串的末尾
3、.:匹配任意字符,除了换行符,当re.DOTALL标记被指定时,则可以匹配包括换行符的任意字符
4、[…]:用来表示一组字符,单独列出:[amk] 匹配 ‘a’,‘m’或’k’
5、[^ …]:不在[]中的字符:[^abc] 匹配除了a,b,c之外的字符
6、re*:匹配0个或多个的表达式
7、re+:匹配1个或多个的表达式
8、re?:匹配0个或1个由前面的正则表达式定义的片段,非贪婪方式
9、re{ n}:匹配n个前面表达式。例如,"o{2}“不能匹配"Bob"中的"o”,但是能匹配"food"中的两个o
10、re{ n,}:精确匹配n个前面表达式。例如,"o{2,}“不能匹配"Bob"中的"o”,但能匹配"foooood"中的所有o。"o{1,}“等价于"o+”。“o{0,}“则等价于"o*”
11、re{ n, m}:匹配 n 到 m 次由前面的正则表达式定义的片段,贪婪方式
12、a| b:匹配a或b
13、(re):匹配括号内的表达式,也表示一个组
14、(?imx):正则表达式包含三种可选标志:i, m, 或 x 。只影响括号中的区域
15、(?-imx):正则表达式关闭 i, m, 或 x 可选标志。只影响括号中的区域
16、(?: re):类似 (…), 但是不表示一个组
17、(?imx: re):在括号中使用i, m, 或 x 可选标志
18、(?-imx: re):在括号中不使用i, m, 或 x 可选标志
19、(?#…):注释.
20、(?= re):前向肯定界定符。如果所含正则表达式,以 … 表示,在当前位置成功匹配时成功,否则失败。但一旦所含表达式已经尝试,匹配引擎根本没有提高;模式的剩余部分还要尝试界定符的右边
21、(?! re):前向否定界定符。与肯定界定符相反;当所含表达式不能在字符串当前位置匹配时成功
22、(?> re):匹配的独立模式,省去回溯
23、\w:匹配数字、字母、下划线
24、\W:匹配非数字、非字母、非下划线
25、\s:匹配任意空白字符,等价于 [\t\n\r\f]
26、\S:匹配任意非空字符
27、\d:匹配任意数字,等价于 [0-9]
28、\D:匹配任意非数字
29、\A:匹配字符串开始
30、\Z:匹配字符串结束,如果是存在换行,只匹配到换行前的结束字符串。
31、\z:匹配字符串结束
32、\G:匹配最后匹配完成的位置
33、\b:匹配一个单词边界,也就是指单词和空格间的位置。例如, ‘er\b’ 可以匹配"never” 中的 ‘er’,但不能匹配 “verb” 中的 ‘er’
34、\B:匹配非单词边界。‘er\B’ 能匹配 “verb” 中的 ‘er’,但不能匹配 “never” 中的 ‘er’
35、\n, \t, 等:匹配一个换行符。匹配一个制表符, 等
36、\1…\9:匹配第n个分组的内容
37、\10:匹配第n个分组的内容,如果它经匹配。否则指的是八进制字符码的表达式

 浙公网安备 33010602011771号
浙公网安备 33010602011771号