

[CVPR2017]Online Video Object Segmentation via Convolutional Trident Network
基于三端卷积网络的在线视频目标分割
|
针对半监督视频目标分割任务,作者采取了和MaskTrace类似的思路,以optical flow为主。 本文亮点在于: 1. 使用共享backbone,三输出的自编码器。 2. 对一些视频中确定性像素建模,分割前后景。 3. 对被遮挡又重新出现的物体使用前后景GMMs损失建模识别,增加正确率。 |
摘要
半监督的在线视频目标分割任务就是给定第一帧的Mask,然后分割后续的帧。我们可以使用optical flow向量传递前面帧的分割效果到后续帧,但是这样会产生错误。因此作者提出了一个三端网络(CTN)——输出分割概率,确定性前景概率和确定性后景概率,然后使用马尔科夫随机场优化得到最终结果。
Proposed Algorithm
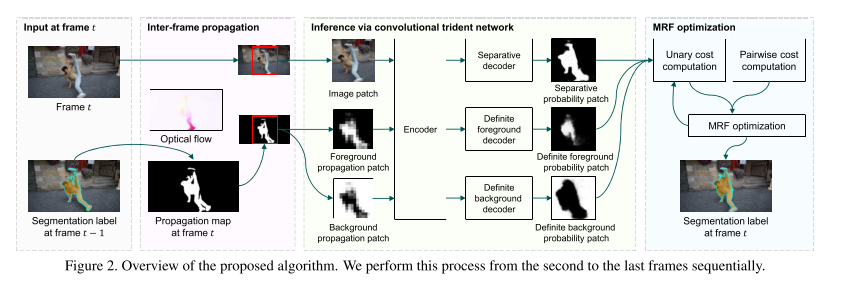
算法流程如下:
1. 首先输入当前帧 t 和前一帧 t-1 的分割mask,前一帧的分割mask在optcal flow的指导下预测出 t 帧的大致样子。
2. 同时对 t 帧和传播后的mask进行crop截取path。经过前景后景抽取的mask和crop后的 t 帧输入到网络得到三张概率map。
3. 对概率图进行MRF优化得到第 t 帧的分割效果。
Propagation of Segmentation Labels
对于像素点p=[x, y]T,从I(t-1)到I(t)的label传播为:

其中S(t-1)为前一帧的分割label图。[u, v]为I(t)到I(t-1)的后向optical flow向量。

Network Architecture
编码结构采用VGG-16,224x224x3为输入,由13个卷积层,3个全链接层和5个池化层组成。
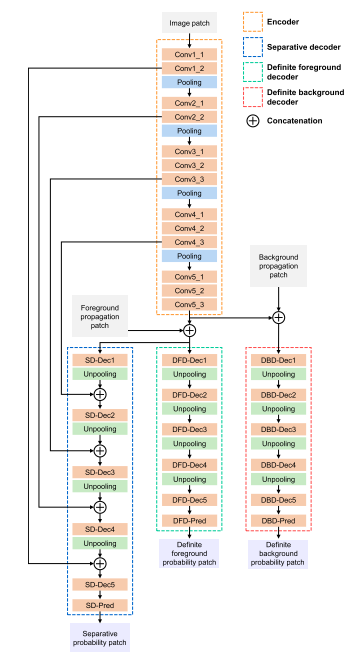
分割概率需要精准风格边界,所以需要shortcut结构获取低层特征信息。确定性前景或后景只判断最可能确定的像素点,所以不需要细节信息。前景后景的输入resize到14x14和VGG输出对齐,因为只是估计确定性像素点,所以相当于低通滤波的resize可以这么设计。卷积层加BN+ReLU。

Training Phase
介绍完网络结构,接下来要说怎么训练,因为原始数据集一般都只带有label mask。
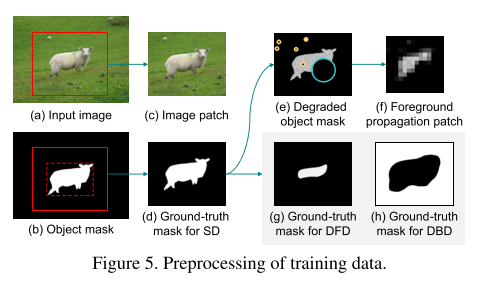
给定输入图片(a),根据边距进行裁剪,与图片的形状大小成正比。然后对mask降质(degrade),对masked区域填充[0.5)的随机强度,然后遮盖部分或圆形噪声点(e)。对降质后的图片进行高斯smoothing和阈值化得到两个Ground truth。
推理阶段,截取图片和传播后的H输入网络,H需要多截取50像素点然后resize。
Markov Random Field Optimization
优化目标函数: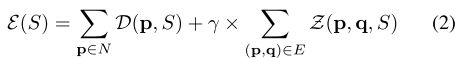 。
。
其中前景后景的作用点在于一元能量函数:
Reappearing Object Detection
如何定义不连续的像素点来检测重新出现的目标,作者定义了像素点的不连续性
。假设前一帧的像素点为 p_head ,当前帧为 p, 大于某阈值即为不连续。
对第一帧和第(t-1)帧使用前景和后景的GMMs。那么一个属于重新出现部分的不连续点的前景高斯损失就会低于后景高斯损失。高斯损失定义在公式(3)。
Experimental Results

作者又提出了一个Fast版本。

实验结果图:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号