一文彻底让你学会自己解决乱码问题
问题:之前编程过程中偶尔会遇到一些乱码的问题,基本都是搜搜博客解决就算了,今天仔细看了各位大佬的视频和博客算是比较了解了一些编码的原理,结论就是乱码的原因都是编码不一致导致的!!!
各种编码到底是怎么出现的?
很久之前,美国佬发明了计算机,但计算机硬件只懂得01,当时的程序员用纸带打孔来编程,但这比搬砖还累,有人就想怎么用英文字母来编程呢?想要让计算机认识英文字母肯定要找到英文字母与01的对应关系才行,显然二者之间没有任何关系,所以他们给自己的英文字母和一些符号赋予编号,让它们每个字符可以用二进制表示,这个过程就在编码了。
先介绍几个主要的概念:
- 字符集:一系列字符的合集,比如英文,汉字,符号
- 码位:就是前面提到的给每个字符赋予编号,这个编号就是码位
- 字符编码:按照某种规则,将程序数据(字节序列)和字符集的码位进行互转的方法
ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)
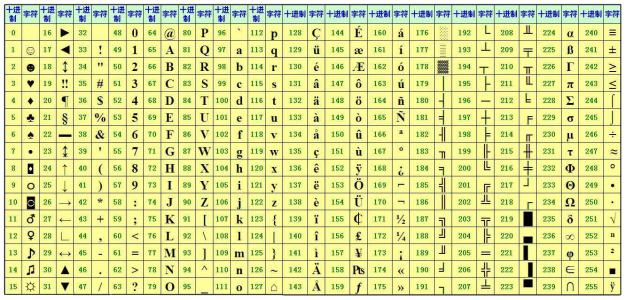
相信大家很熟悉ASCII编码了,它就是开发者最早想出的一种编码。他的特点是一个字节对应一个字符,一个字节(8位)可以表示256个字符,ASCII一开始用0~127表示了大部分的字母和符号,后面为了把一些不常用的字符也包含进来扩展到了255,如下图所示:
GB2312&GBK(汉字内码扩展规范)&GB18030
随着计算机风靡到我国,我们的程序员当然也想让计算机上出现我们的汉字,但是前256个编码都被美帝占了,但我们汉字可不止几百,优秀的中国程序员的做法是:
-
一个汉字对应两个字节
-
不大于127的字符仍然与ASCII的字符集相同,高位字节(0xA1~0xF7,)与ASCII不同
-
如果2个高位字节同时出现,就认定这是个中文字符,去GB2312编码表里找对应的值
这样GB2312字符集就能有7000多个简体汉字了,但后面我们发现对于生僻字GB2312还是不够用,
我们就发明了GBK编码:要求低字节一定是127号之后的内码,只要第一个字节是大于127就固定表示这是一个汉字的开始,不管后面跟的是不是扩展字符集里的内容。再后来我们想要继续加入少数名族和一些亚洲国家的文字,又将GBK扩展成了GB18030。
“从此之后,中华民族的文化就可以在计算机时代中传承了。 中国的程序员们看到这一系列汉字编码的标准是好的,于是通称他们叫做“DBCS“(Double Byte Charecter Set 双字节字符集)。在DBCS系列标准里,最大的特点是两字节长的汉字字符和一字节长的英文字符并存于同一套编码方案里,因此他们写的程序为了支持中处理,必须要注意字串里的每一个字节的值,如果这个值是大于127的,那么就认为一个双字节字符集里的字符出现了。”
Unicode(万国码)
不光中国,各国的程序员都开发出了自己国家语言的编码,这样一来在本国计算机上运行其他国家的程序就会出现严重的编码问题,这样很不利于世界计算机文化的交流,ISO(国际标谁化组织)的国际组织决定着手解决这个问题,他们打算叫它”Universal Multiple-Octet Coded Character Set”,简称 UCS, 俗称 “unicode“。unicode开始制订时,计算机的存储器容量极大地发展了,空间再也不成为问题了。于是 ISO 就直接规定必须用两个字节,也就是16位来统一表示所有的字符,对于ASCII里的那些“半角”字符,unicode 包持其原编码不变,只是将其长度由原来的8位扩展为16位,而其他文化和语言的字符则全部重新统一编码。
只要记住Unicode可以与全世界各种语言互相转换!!!
但是Unicode存在空间大浪费和效率低的问题,本来1字节就能存的英文字符得翻倍存储了。
UTF-8
Unicode 在很长一段时间内无法推广,直到互联网的出现,为解决 unicode 如何在网络上传输的问题,于是面向传输的众多 UTF(UCS Transfer Format)标准出现了,顾名思义,UTF-8就是每次8个位传输数据,而 UTF-16 就是每次16个位。UTF-8 最大的一个特点,就是它是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度,当字符在 ASCII 码的范围时,就用一个字节表示,保留了 ASCII 字符一个字节的编码做为它的一部分,注意的是 unicode 一个中文字符占2个字节,而UTF-8一个中文字符占3个字节)。从Unicode 到 uft-8 并不是直接的对应,而是要过一些算法和规则来转换。
读到这里可能读者对Unicode与UTF-8的关系仍然不是很清楚,其实Unicode是一个编码字符集,并不是一种字符编码,由于微软习惯把
UTF-16LE(Little Endian)称做Unicode编码,所以误导了大部分人。UTF-8UTF-16(LE/BE)UTF-32(LE/BE)才是针对Unicode字符集的编码方式。
简单来说,Unicode字符集就是给世界上所有的语言符号编了一个号码,具体是用几个字节存储英文以及用几个字节存汉字由UTF-8等编码规定
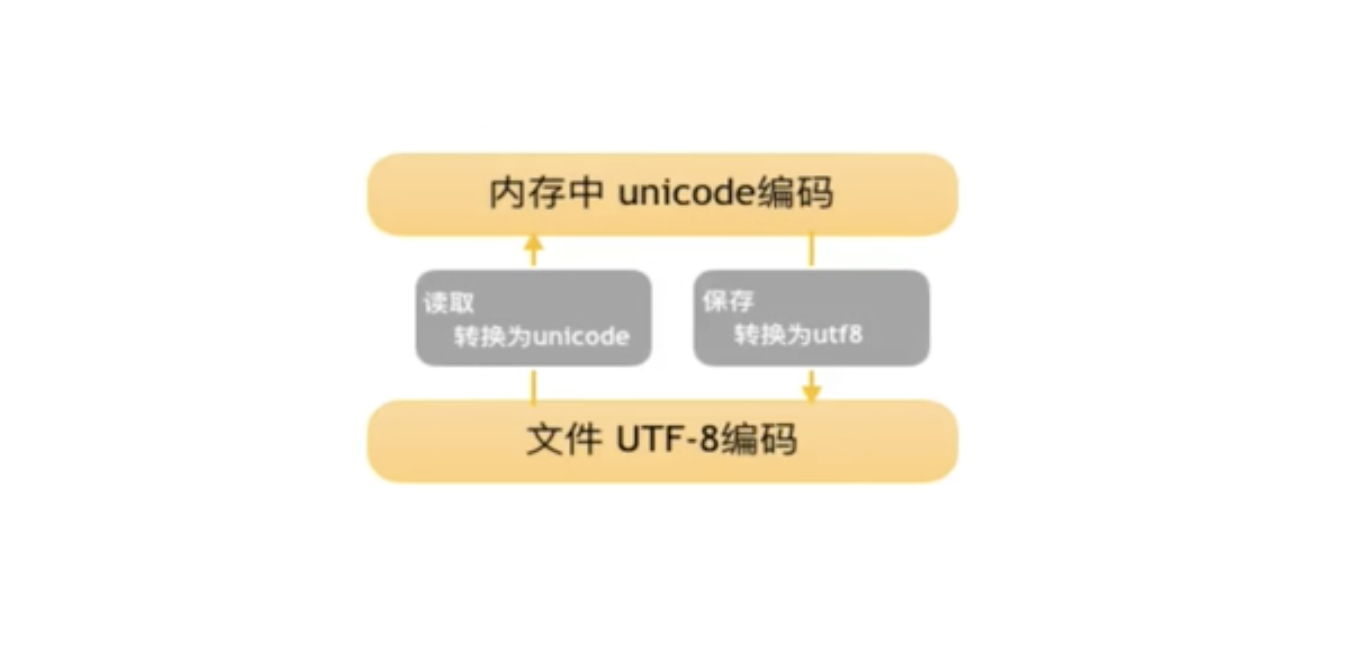
分析乱码出现的原因
乱码的原因都是编码不一致导致的!!!
想要知道是哪里出现了编码不一致,我们需要了解存在编码的地方:
- 程序文件有编码(比如.py,.java,.c等程序文件)
- 数据文件和数据源有编码(比如要读的.xlsx,.docx文件以及mysql等数据库里的数据都存在编码)
- 展示数据的平台也有编码(比如各种终端和浏览器)
如果将编码A的文件,用编码B的IDE或者文本浏览器打开就会显示乱码。
如果程序读取编码A的数据,并转成字符串,默认转换编码是B,也会乱码。
如果向前端返回的数据编码是A,而浏览器用编码B去展示也是乱码,类似第一种。
典型案例分析:python2解释器
首先我在mac里新建了一个py2中文.py的脚本:

然后我用python2.7解释器运行:

好家伙,直接报错!!!
根据上面的知识,我们先分析程序文件的编码,因为我们是用mac终端来编辑程序文件的,我们现场查看我们mac终端的编码方式,直接输入locale命令:

可以看到mac终端用的是utf-8编码,显然在utf-8中汉字是用3个字节来存储的,而坑的地方在于python2是在Unicode编码出来之前开发的,所以它默认用ASCII来编码!!!所以我们来看下这两个汉字具体存储的字节是啥:

sys.getdefaultencoding()读取 python 默认编码是 ASCII,而 ASCII 是不认识 \xe4的,所以会报错Non-ASCII character '\xe4' in file demo.py on line 1, but no encoding declared;,此时只要在 demo.py 文件头加上 # encoding:utf-8就可以了,虽然是注释,但 python 看到这句话就知道了接下来应该用utf-8编码了,而 demo.py 存储时也是utf-8的,所以就正常了。我们再打印一次:

成功显示中文!!!
如今的python3解释器默认是Unicode编码的,所以不用担心这个问题:

这里插一个python解释器的知识
编译性语言
程序在执行之前需要一个专门的编译过程,把程序编译成 为机器语言的文件,运行时不需要重新翻译,直接使用编译的结果就行了。程序执行效率高,依赖编译器,跨平台性差些。如C、C++、Delphi等.
以C语言编译过程为例,具体见链接c语言的编译过程,
gcc命令其实依次执行了四步操作:
1.预处理(Preprocessing), 2.编译(Compilation), 3.汇编(Assemble), 4.链接(Linking):

解释性语言
在运行程序的时候才翻译,专门有一个解释器去进行翻译,每个语句都是执行的时候才翻译。效率比较低,依赖解释器,跨平台性好,源代码不是直接翻译成机器语言,而是先翻译成中间代码,再由解释器对中间代码进行解释运行。比如Python/JavaScript / Perl /Shell等都是解释型语言。
以python为例:m.py(源代码)——> m.pyc(字节码)——> PVM(虚拟机运行)
安装Python 时候,会有一个 Python.exe 文件,这就是 Python 解释器,你写的每一行 Python 代码都是由它负责执行,解释器由一个编译器和一个虚拟机构成,编译器负责将源代码转换成字节码文件,而虚拟机负责执行字节码,所以,解释型语言其实也有编译过程,只不过这个编译过程并不是直接生成目标代码,而是中间代码(字节码),然后再通过虚拟机来逐行解释执行字节码。
程序编译过程中编码的作用
- 源文件编码:文件其实就是一堆字节所组成的,生成这些字节序列的方式即源码编码。
- 编译器执行编码:编译器最终生成执行文件时的编码。
编译过程中,编译器通过识别源文件的编码,将其按照执行编码进行转换输出,生成目标文件,最终目标文件经过链接生成可执行程序。所以当我们程序运行后,程序内部的各种数据,均是执行编码,而不是源码编码。参考链接
字符是怎么在计算机上显示的
经过上面的阅读,相信大家对各种编码都熟悉了但还是对这个问题有点疑惑。
知乎飞错的雪:当你按下A键,操作系统先把A从ascii编码,转换到unicode,然后会在系统字体中(c:windows/font目录),比如(宋体.ttf)查找A对应的字形。ttf文件前半部分有个表,存储的unicode到字形信息(6字节,4字节是偏移,2字节是对应字形的长度)的映射。这个时候操作系统取出A字母对应的字形信息。操作系统根据字形信息把这个字母画出来,生成一个图片,然后显示在屏幕上。freetype是一个字体引擎,这个引擎可以接收一个unicode和一个字体文件,然后输出一个字体的图片。操作系统应该不会用freetype去做这些事,应该是用的自己的字体引擎。
总之,就是首先根据你要现实的字符对应的Unicode去字体库中找到对应的字形然后再通过字体引擎渲染在屏幕上。
参考资料:
1.https://blog.csdn.net/joyfixing/article/details/79971667
2.https://www.zhangjunbk.com/article/31174
3.https://www.cnblogs.com/huchong/p/9037142.html
4.https://www.jianshu.com/p/6bdc0d52620a
5.https://zhangrunnan.com/encoding/
6.https://www.cnblogs.com/CarpenterLee/p/5994681.html
7.https://www.cnblogs.com/alex3714/articles/7550940.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号