Celery 源码解析四: 定时任务的实现
序列文章:
-
Celery 源码解析一:Worker 启动流程概述
-
Celery 源码解析二:Worker 的执行引擎
-
Celery 源码解析三: Task 对象的实现
-
Celery 源码解析四: 定时任务的实现
-
Celery 源码解析五: 远程控制管理
-
Celery 源码解析六:Events 的实现
-
Celery 源码解析七:Worker 之间的交互
-
Celery 源码解析八:State 和 Result
在系列中的第二篇我们已经看过了 Celery 中的执行引擎是如何执行任务的,并且在第三篇中也介绍了任务的对象,但是,目前我们看到的都是被动的任务执行,也就是说目前执行的任务都是第三方调用发送过来的。可能你会有点奇怪,难道除了第三方调用发送,还有其他的调用发送方?是的,Celery 自身也会发送任务,在本文中,你将看到 Celery 如何利用自身的定时机制运行我们设置得定时任务,并且交给 Worker 执行。
定时任务的定义
在开始讲解源码之前,我们不妨先看下我们平常都是怎么定义定时任务的,还是以我们习惯的 Demo 为例:
 

定义就是这么简单,这么随意,但是,想要执行却是需要我们运行一个定时器,也就是在命令行中启动 Beater,正常情况下你这么做就可以了:

然后你就会看到一个个的定时任务被发送到 MQ 中,然后被 worker 消化。
定时任务的启动
上面只是举了个如何使用的例子,但是,在 Celery 内部是如何处理这些任务才是我们需要关心的真正的点。回想一下在我们第一篇中讲 Worker 的启动流程的文章,有一个很重要的 BootStep 我们还没有讲到,那就是 Worker 的 Beat,但是我在那里排的优先级却是 2,确实如此,我也是在讲完了所有 1 的优先级之后再讲它的,所以它可以说重要,也可以说不重要。
既然都说开了,那么就不停下了,直接看看 Beat 的实现,Beat 的实现可以说是非常简单,我们一眼就可以看完:
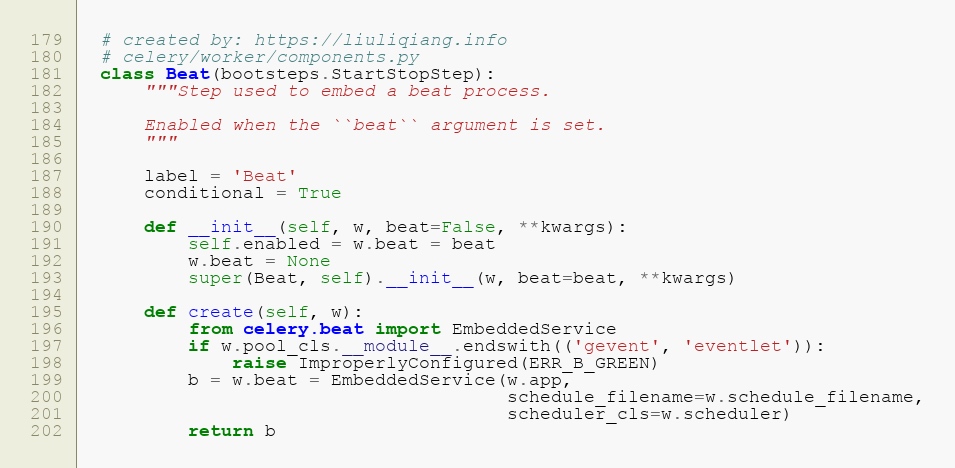 

核心还是在 create 中咯,然后关键还是看 Line 199,这里又牵扯到 celery.beat.EmbeddedService,那我们基本上就可以确定在这了。
 

敲黑板了,注意看这里,Line 648 就决定了是使用 线程 还是 进程 来运行 Beat 服务,但是我们应该清楚,无论是使用 线程 还是 进程,思路都是相差不远的,我们可以先找一个来看看。到这里,其实定时任务的启动工作就算是完成了,因为后面就是以独立的线程/进程执行了,主线程已经可以回去了。
 

定时任务的执行
其实无论是用 Thread 还是 Process,这里都是构造的 Service 对象,然后 start 的,那么这个 Service 对象具体是啥,其实也是在这个文件里面,但是我们不急着看它。在看它之前我先给大家描述一下这个文件里面几个关键的类的关系,方便大家了解:
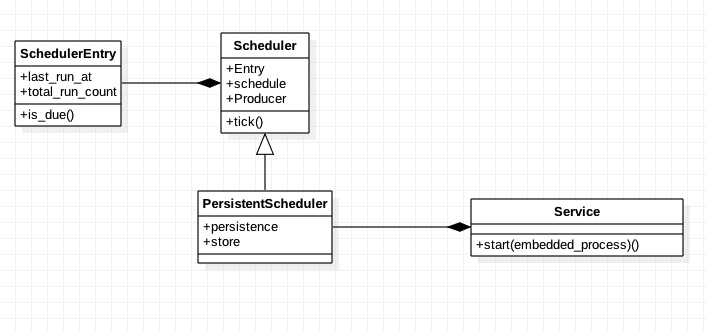 

这里就出现了 4 个类,它们之间的关系还是比较明显的,中枢部分就是 Scheduler,然后 Service 是驱动部分,最后的承载实体就是 SchedulerEntry 了,明白这层关系之后,我们再来看看 Service 是如何驱动的:
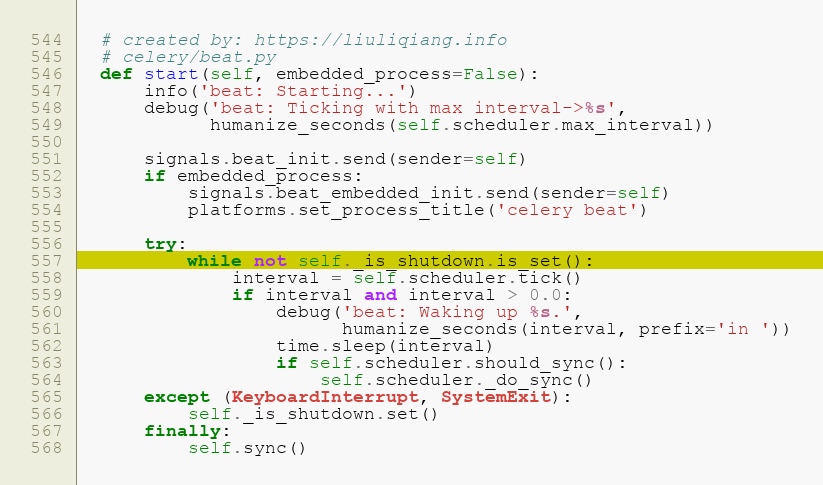 

这里的灵魂一句就是 Line 557 中的这句循环了,我们知道这段代码是运行在独立的线程/进程中的,所以这里是个死循环,而循环的条件就是条件变量 shutdown 被设置了。这里不断得尝试做一件事情,这件事情就是调用 scheduler 的 tick 函数,并且根据它返回的值等待片刻,然后继续执行,所以,关于这个 tick 里面有什么东西,很值得我们关注,从上面的 UML 图中,我们可以看到 tick 是在 Scheduler 中,所以直接可以找到它:
 

这段代码乍一看可能会很复杂,但是实质上很简单,其中 H 是一个最小堆,它的作用就是承载了所有我们设置得定时任务,而最小堆的特性就是堆顶的元素是最小的,在这里就是 event 这个变量,那么你可能会问排序的依据是啥,排序的依据就是 Line 274 的关键词 next_time_to_run,celery 会先计算每个定时任务下一次执行的时间戳 - 当前时间戳,然后根据这个时间差值进行排序,毫无疑问,差值最小的就是下一次需要执行的任务了。
同样在 Line 274 这里还做了一个判断,那就是差值最小的那个任务现在应不应该执行 is_due,如果应该执行,那么 Line 276 - Line 285 就是执行的逻辑了,这里需要注意的一点就是 Line 277 还对出堆的元素进行了判断,以防不是我们刚才要执行的元素,这里我猜测的原因是这个 H 并不是线程安全的,在我们执行定时任务的时候,还可能有其他线程/进程在修改它,所以需要进行一个判断。
还有一个值得我们关注的点就是 Line 279 中的提交定时任务,这个也可以说是我的此行的目的,但是,我们已经有了普通异步任务的经验,相信这里不会让我们太吃惊。
 

正如所期待的,这里只是想将 SchedulerEntry 转换为 Task,然后至于 Task 怎么提交的异步任务,相信看过 第三篇文章的同学已经不陌生了,可以 pass 了。
那么到这里我们也算是将定时任务的执行看完了。
定时任务的持久化
虽然定时任务的执行我们是看完了,但是,定时任务还有一个很重要的地方我们还没有看,那就是持久化。在 Celery 中,定时任务的执行并不会因为我们重启了 Celery 而失效,反而在重启 Celery 之后,Celery 会根据上一次关闭之前的执行状态,重新计算新的执行周期,而这里计算的前提就是能够获取旧的执行信息,而在 Scheduler 中,这些信息都是默认保存在文件中的。
Celery 默认的存储是通过 Python 默认的 shelve 库实现的,shelve 是一个类似于字典对象的数据库,我们可以通过调用 sync 命令在磁盘和内存中同步数据。当然,你也可以自定义存储的位置,但是目前来看这个 store 存储适合 PersistentScheduler 绑定的,所以我个人更建议通过自定义 Scheduler 来实现,我曾经在 Github 开源了一个基于 Redis 的实现,感兴趣的同学可以看一下,地址是:celery redis beat
所以这个问题就变成了如何自定义 Scheduler,我根据自己的经验,总结了以下步骤:
- 继承
Scheduler类,实现构造函数 - 实现
Scheduler的tick()、should_sync()、_do_sync()、close()等方法 - 启动的时候指定
Scheduler类的包路径即可
总结
在本篇文章中,我们以 Beat 为触发点,讲解了 Celery 关于定时任务的定义、启动、执行和持久化。通过本篇文章的介绍,应该可以自己定义或者修改出更好得定时调度器了,同时我们也知道保存在当前目录下的定时文件有什么用了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号