聊聊我与流式计算的故事
聊聊流式计算吧 , 那一段经历于我而言很精彩,很有趣,想把这段经历分享给大家。
1 背景介绍
2014年,我在艺龙旅行网促销团队负责红包系统。
彼时,促销大战如火如荼,优惠券计算服务也成为艺龙促销业务中最重要的服务之一。
而优惠券计算服务正是采用当时大名鼎鼎的流式计算框架 Storm。
流式计算是利用分布式的思想和方法,对海量“流”式数据进行实时处理的系统,它源自对海量数据“时效”价值上的挖掘诉求。
优惠券计算服务的逻辑是:每个城市每个酒店的使用优惠券的规则并不相同,当运营人员修改规则之后,触发优惠券计算服务,计算完成之后,用户下单时在使用优惠券时会呈现最新的规则。
优惠券计算服务是我们团队的明星项目,很多研发的同学都对 Storm 特别感兴趣 , 因为 Storm 的核心开发语言是 clojure , 比较小众。
于是,在团队内部,发现一个很有趣的现象:很多同学的办公桌上放着《clojure in Action 》这本书。

彼时,艺龙开始发力移动互联网,业务量的激增,优惠券计算服务开始遇到了瓶颈。
比如运营人员修改全量规则时,整个计算流程要耗时一上午,也就谈不上实时计算了。
CTO 几次找团队负责人,并严厉批责成他尽快优化。经过一个半月几次优化,系统的瓶颈依然明显,时不时运营同事会走到我们的工位附近,催促我们:“系统生效了么? ”
我并不负责计算服务,每当同事被质疑时,我都感到很疑惑:“优惠券计算服务真的那么复杂吗? ” , 同时也跃跃欲试:“ Storm 真有那么难搞吗?”
我心中暗暗下定了决心,一定要弄清楚优惠券计算服务的逻辑 。
2 国图学习
北京有很多景点都让我流连忘返,比如史铁生小说里的地坛,满山枫叶的香山,如诗如画的颐和园,美仑美奂的天坛 。
在我心里,有一处很神圣的地方,它是知识和希望的象征,那就是国家图书馆 。

中国国家图书馆位于北京市中关村南大街33号,与海淀区白石桥高粱河、紫竹院公园相邻。它是国家总书库,国家书目中心,国家古籍保护中心,同时也是世界最大、最先进的国家图书馆之一 。
每到周末,当我想安静下来,专注思考时,我就会背着笔记本电脑来到国家图书馆。
选择自己喜欢的书,然后将笔记本电脑打开,一边看书,一边在电脑上写点笔记。
偶尔抬起头,望着那些正在阅读的读者,心里面感觉很阳关,觉得生命充满了希望。
我并不负责流式计算服务,但想要揭开 Storm 神秘面纱的探索欲,同时探寻优惠券计算服务为什么会这么慢的渴望,让我好几天晚上没睡好。
于是周六上午9点半, 我来到国家图书馆 ,想让自己安静下来,思考如何解决这个问题。解决问题的快感,是我一直追求的。
当我把笔记本电脑放平在桌上,我很兴奋,同时灵台一片澄清:优惠券计算服务的核心是 Storm ,那么我需要先了解 Storm 的整体概念。
打开官网,浏览官网的文档,第一次看到 Storm 的逻辑流程图时, 做为程序员,我第一次竟然感受到抽象之美:从源头流下来的水通过水龙头( Spout ),再经过层层转接头( Bolt )过滤,不就是我们想要的纯净水吗?
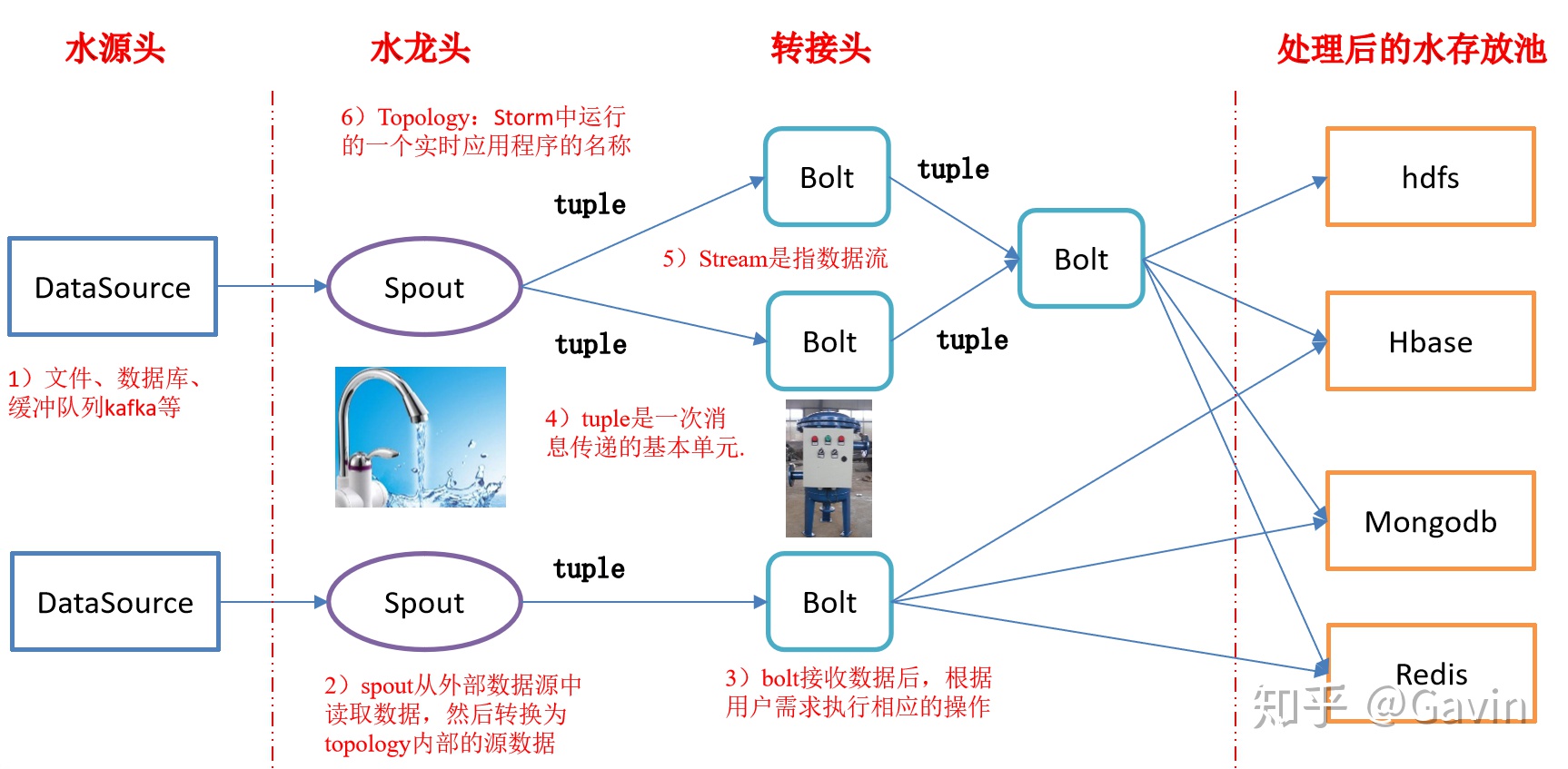
其实我们原来都是 CRUD boy ,机械的使用那些框架,只会做增删改查,并不会思考框架背后的设计思路。 但框架到底是什么?从来没有思考过。 我一直觉得我很笨拙,学什么都很慢,但那一刻我突然恍然大悟:框架本身是将解决问题的思路抽象化,从而便于研发人员使用,把复杂的问题抽象成有美感,是需要功底的。
了解完 Storm 整体概念 , 下一步也就是大家熟知的写 Hello World 阶段了 。
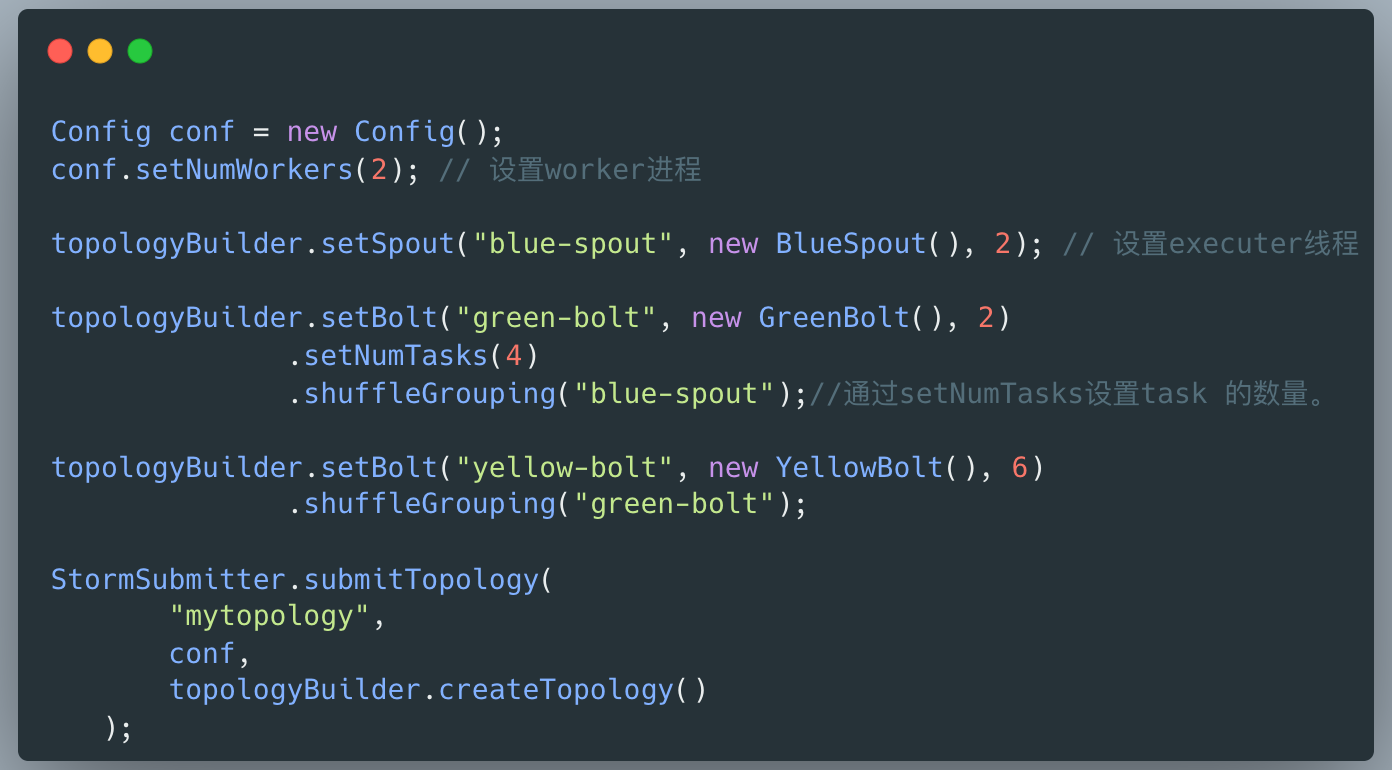
我参考教程写了一个简单的 Storm 应用(简称:拓扑),在部署后,程序正常跑了起来。
我脑海里一直有一个疑问:“是不是优惠券计算服务的 storm 集群的配置没有调优,才导致计算的性能太差 ? ” 所以我必须去理解 storm 的并发度是如何计算的。
整个下午,我一直在查阅相关的资料,并结合下图思考:Nimbus, Supervisor ,Worker ,Task 这些名词到底是什么概念,以及他们之间是如何交互的。
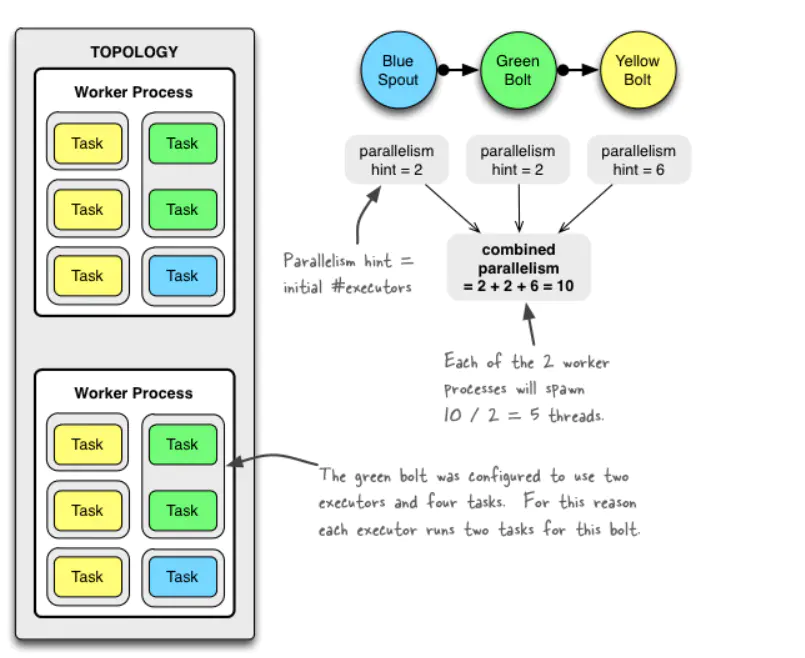
进而思考:拓扑到底会启动几个进程,每个进程内部线程模型是怎样的,颇有些庖丁解牛的味道。
这个习惯一直保持到现在,当我看到一个系统,我会下意思的去思考:“这个系统的线程模型如何,每次操作有哪些线程参于,他们之间如何交互”。我知道有更厉害的大牛,运行一行代码就知道 CPU 会运行的哪些指令,我做不到,但我觉得那就更加深刻了。
不管怎样,这一天,我的思绪经过多次的变化,兴奋,犹疑,放弃,阳光,激动,畏难心理一直存在,很多次想放弃,但好奇心一直鼓励着我。
等天色已黑,我走出国图的大门,脑子里全部都是 Storm 进程,线程模型,内心里面,有了莫名的自信。感觉自己就像仙剑奇侠传里的酒剑仙,伴随着激昂的 BGM ,拔剑四顾,斩妖除魔。
御剑乘风来,除魔天地间,有酒乐逍遥,无酒我亦癫。
一饮尽江河,再饮吞日月,千杯醉不倒,唯我酒剑仙。
3 找到瓶颈
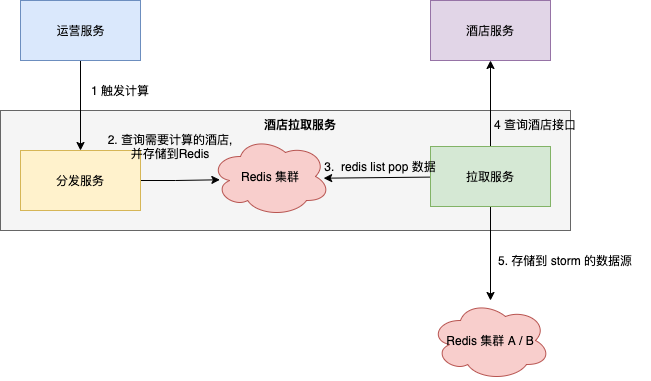
当我理解了 Storm 的整体概念,接下来我需要去找到优惠券计算服务的性能瓶颈。这个时候,梳理计算服务整体流程非常关键。
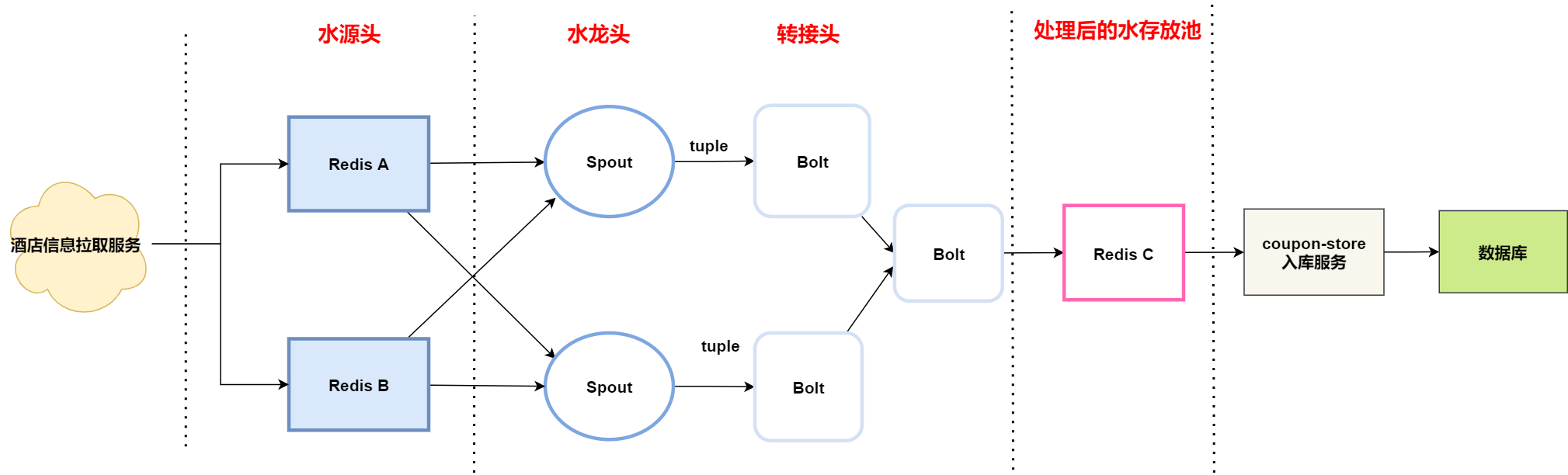
计算服务整体流程分为三个步骤 :
- 抽取数据:酒店信息拉取服务拉取酒店信息,并存储到水源头( Redis A/B 集群 ) ;
- 计算过程:Storm 拓扑从水源头获取酒店数据,通过运营配置的规则对数据进行清洗 ,将计算好的数据存储到水存放池 ( Redis C 集群) ;
- 入库阶段:入库服务从水存放池获取数据,将计算结果存储到数据库 。
当我们把整个计算的过程拆分成 抽取-->计算 --> 存储 三个阶段的时候,计算服务的架构就变得异常清晰,那到底在哪个阶段最耗时 ,也成为我追查的目标。
优惠券计算服务当时没有详细的性能监控体系,所以我只能先从日志着手。 在运营同事触发全量计算后,分别观察三个阶段对应服务的日志:
- 抽取数据:酒店信息拉取服务
- 计算过程: Storm 拓扑
- 入库阶段: 入库服务
令人惊讶的现象:一次全量计算需要耗时4个多小时,但抽取数据的任务竟然跑了2个多小时,和我预期完全不一样。

假如我把酒店信息拉取服务比作抽水泵,那么整个系统最大的问题竟然是抽水泵抽水马力不足。
4 推进重构
为什么抽水泵抽水马力不足 ?
通过阅读源码,我发现因为线程模型不够好,应用在部署多个节点后,每个节点只能有两个线程执行拉取酒店信息。
怎么处理呢? 在原有代码上优化可行吗? 好像也不太容易,因为老代码最初是一个 C# 研发同事写的,他当时也不熟悉 JAVA ,从设计层面来讲,有很多冗余且不合理的代码,而且经过3年左右的维护,代码老化严重,于是我只能想到重构。
当我把想法和团队负责人沟通后,他有点半信半疑,他认为我的判断没有问题,但不确定我是否可以将系统重构好。 我那时候信心爆棚,主动请缨,打包票不会出问题的。可能是由于 CTO 逼的太紧了,他同意了。
在重构之间,梳理好系统的整体逻辑。
重构的重点原则有两条:
-
拉取服务可水平扩展,若性能不足时,增加服务节点即可提升性能;
-
配置文件可配置 worker 线程数量。
那思想层面,我已经做好准备了,那硬实力层面我有没有做好准备吗? 非常自信的讲,准备好了,因为我遇到了 RocketMQ 。
我在《我与消息队列的8年情缘》这篇文章写到:
2014年,我搜罗了很多的淘宝的消息队列的资料,我知道MetaQ的版本已经升级MetaQ 3.0,只是开源版本还没有放出来。
大约秋天的样子,我加入了RocketMQ技术群。誓嘉(RocketMQ创始人)在群里说:“最近要开源了,放出来后,大家赶紧fork呀”。他的这句话发在群里之后,群里都炸开了锅。我更是欢喜雀跃,期待着能早日见到阿里自己内部的消息中间件。
终于,RocketMQ终于开源了。我迫不及待想一窥他的风采。
因为我想学网络编程,而RocketMQ的通讯模块remoting底层也是Netty写的。所以,RocketMQ的通讯层是我学习切入的点。
我模仿RocketMQ的remoting写了一个玩具的rpc,这更大大提高我的自信心。正好,艺龙举办技术创新活动。我想想,要不尝试一下用Netty改写下Cobar的通讯模块。于是参考Cobar的源码花了两周写了个netty版的proxy,其实非常粗糙,很多功能不完善。后来,这次活动颁给我一个鼓励奖,现在想想都很好玩。
在重构酒店信息拉取服务时,我将 RocketMQ 如何创建线程的知识点正好也用了上去,并学习如何将模块拆分得更加合理。同时在重构过程中,不断 Review 新老代码的差别,确保核心逻辑正确。
非常幸运,大概一周时间,我就重构完了。
重构完成并不意味着结束,怎么验证呢 ? 我当时采取了两种方式:
-
代码评审
我拉着优惠券计算服务的同事,一起 review 代码 。整个过程,大家也并没有提出异议,并对我创建线程的技巧感到很好奇。我心中窃喜:”那是学习 RocketMQ 的“。
-
测试环境数据验证
我们将新旧两版服务同时触发,比对两个版本的数据的异同,将比对结果输出到日志文件,然后从中找到差异的地方,修复重构版的 BUG 。 然后在测试环境部署重构版,观察一段时间,确保无异常。
从编写第一行代码,三周时间,重构版终于上线了。 我将原来的老服务替换后,部署了3个节点, 每个节点8个 worker 并行拉取酒店信息 。
令人开心和激动的是,重构是非常成功的。 因为业务给我们的时间需求也是1个小时左右。一次全量计算从原来4个小时急速缩减到1小时15分钟,整个酒店拉取服务耗时40分钟左右。
我心里长舒一口气,内心吟诵李白的诗:"十步杀一人,千里不留行。事了拂衣去,深藏身与名。"
5 向前一步
前 Facebook COO 谢丽尔·桑德伯格 写了一本书《向前一步》,我特别喜欢这本书的书名 。

在优化优惠券计算服务的前期,团队经过一个多月的时间,也没有什么成效。 我自己也犹豫:”我能不能解决这个问题?“ ,但最终我还是向前一步,并帮助团队大大提升了服务的性能,负责人也有了信心,他也敢投入资源优化Storm 拓扑和入库流程。
在阅读优惠券计算服务的代码中,我发现两个问题:
- 流式计算逻辑中有大量网络 IO 请求,主要是查询特定的酒店数据,用于后续计算;
- 每次计算时需要查询基础配置数据,它们都是从数据库中获取。
对于Storm 拓扑优化,我提了两点建议:
- 流式计算拓扑和酒店拉取服务各司其职,将流式计算中的网络 IO 请求挪到酒店拉取服务,将数据前置准备好;
- 基础配置缓存化,引入读写锁(也是 RocketMQ 名字服务的技巧)。
对于入库流程,一位研发同学将原来的单条数据入库修改成批量入库。
经过大家一起努力 ,优惠券计算服务的整体性能大大提升了,全量计算耗时已经变成40分钟了,再也不会有运营同事在我们的工位附近吐槽系统慢了。
6 写到最后
2014年,我向前一步推动了公司流式计算服务的优化,并取得了一点点进步。
时光荏苒,我已中年,生命中遇到越来越多的挫折,有的时候也会让人低落,但每当想起这个故事,我会深深感动于当时的一往无前。
当再次面临选择时,我希望自己也能够向前一步,想着如何帮助读者成长,或是实现一个产品帮助更多的人。
如果我的文章对你有所帮助,还请帮忙点赞、在看、转发一下,你的支持会激励我输出更高质量的文章,非常感谢!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号