灌水贴挖掘初步
灌水帖挖掘初步(2017-1-15 16:17:20 发布于: 西电睿思BBS)
http://rs.xidian.edu.cn/forum.php?mod=viewthread&tid=841917
这是一篇灌水帖,但不仅仅是灌水......
在一个夜深人静的夜晚,躺在床上久久难以入眠。划拉着手机,逛着睿思,把水区的帖子一个个点开。各种信息映入眼帘,有18禁的征婚交友贴,有感叹校园的世事无常贴,也有locklock的晚安贴。。。
-----此处割掉三厘米-----
我在痛苦中思索着几个问题:人在无聊的时候应该做些什么而不至于太感觉浪费时光呢?除了抽烟喝酒烫头这种提升个人境界的事情,是否可以做些帮助普罗大众的事情?
一觉醒来,我想到了我可以做一件简单的事情:分析下睿思上大家都在讨论什么。
一年前某位仁兄在技术博客发帖,标题是“当我们在睿思灌水,我们在聊些什么”。帖子中将一千篇帖子的标题做成词云展示了出来。可惜自从睿思9月份磁盘奔溃之后,帖子都不见了。这是我第二次发帖,第一次帖子是“IPv4与IPv6互联互通的一些技术”,也永久地消失了。
自己动手复现了该仁兄的过程.下图为仅根据帖子标题中的词频建立的词云,数据来自2016年9月份以后的半年中灌水区的帖子:

词云图片的生成采用了python的WordCloud库,采用了一张卡通图片背景颜色,字体采用的是[maggie]天使小萌猫。生成词云的工具很多,多试几个也无妨。
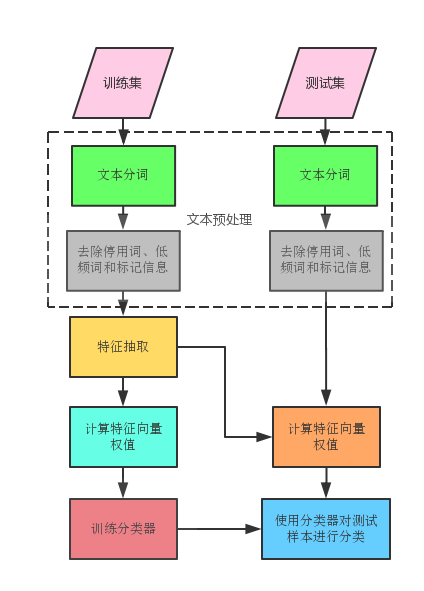
考虑到有很多标题党的存在,仅看标题不足以挖掘到所有的主题分类,所以需要稍微地深入一点,将每篇帖子的楼主所贴内容也加入到数据分析当中。
。。。此处省略对数据进行复制粘贴的工作。。。
下面来一波LDA自动主题分类,选出top-10的主题构成主题的特征向量.
TF-IDF
TF指词频(一篇文档中某词出现的次数),代表了隶属度;IDF指(Inversed Document Frequency)出现某个词的文档个数的倒数,代表了区分度.
用TF与IDF的乘积来评估一个词作为特征是否合适.TF-IDF是一个最初为信息检索(作为搜索引擎结果的排序功能)开发的词加权机制,在文档分类和聚类中也是非常有用的。
LDA(Latent Dirichlet Analysis)
用来确定一组文档的共同主题
结果图如下,感觉不够理想,也许是参数设置的不好,并且没有去掉一些无用的干扰词.
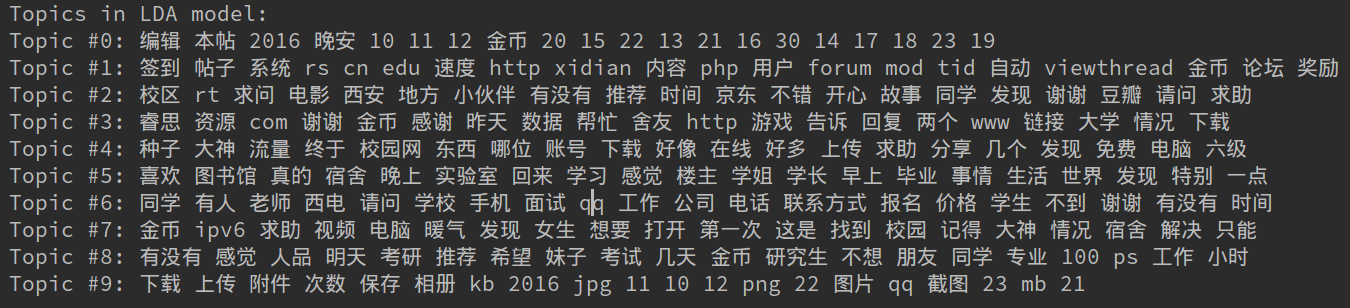
此时我们可以从那些主题词中归纳出一些更合适的主题,如从苹果香蕉归纳出更宽泛的“水果”这一主题。此后便可对帖子进行自动化分类,常见的分类其可能要数贝叶斯了,但是并非无监督学习,也即需要自己选出一些样本进行手工分类(或者考虑kmeans等无监督学习方法)。
朴素贝叶斯分类
已知样本X,
- 首先计算P(X|Ci),得出Ci类别包含样本X的先验概率;
- 然后根据贝叶斯定理求后验概率P(Ci|X),得到X属于Ci类别的后验概率;
- 最后根据最大后验概率判断所属类别。
朴素的含义:
朴素的假设F1与F2相互独立,则 \(P(F1,F2|C)=P(F1|C)P(F2|C)\)
当待分类样本拥有若干特征变量F1…Fn时,待分类样本属于类C的后验概率为:
其中,Z=P(F1,...,Fn)是一个缩放因子,当特征向量的值已知时是一个常数。
分类时可以采用最大后验概率(MAP)决策准则:
为了防止乘积的某一项出现0的情况,可以在分子中简单的加1,分母加上元的个数,可称为“加1平滑”;或者在先验概率的基础上加上一个适当的较小的概率值。
为了防止多个概率值相乘可能出现的算数下溢的情况(接近于0而精度不够用导致结果为0),可以对概率值取对数 log(x⋅y)=logx+logy。
送入贝叶斯分类器进行训练,对任一帖子进行分类(假如能做出每个帖子的特征向量,采用余弦相似度更简单)
总结
本文仅仅简单介绍了一些基础方法,并未给出代码实现,仅为抛砖引玉。我觉得更为重要的是想法和思路,现成的工具和代码很多,只要善加利用,就可以组合出逞手的兵器。
你也许会说,啰嗦了半天原来最终目的只是为了挑出那些征婚交友贴。你可不知,这虽然是我在编程上跨出的一小步,却是我寻找生命另一半过程中跨出的一大步。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号
