
Spring Cloud Sleuth +Zipkin
Spring Cloud Sleuth +Zipkin
一、基本概念
1、分布式跟踪系统
在微服务架构中,众多的微服务之间相互调用,如何清晰地记录服务的调用链路是一个需要解决的问题。同时,由于各种原因,跨进程的服务调用失败时,运维人员希望能够通过查看日志和查看服务之间的调用关系来定位问题。
一个分布式服务跟踪系统主要由五部分构成:
1)数据采集。
2)数据传输
3)数据存储
4)数据分析
5)数据可视化
分布式跟踪系统设计理念
1)平台无关性(不管什么平台,通过插件方式迅速介入)
2)多语言支持
3)多中间件支持
2、Sleuth 介绍
Spring Cloud Sleuth是为了对微服务之间调用链路进行跟踪的一个组件,它的主要作用是数据采集。
3、Sleuth术语
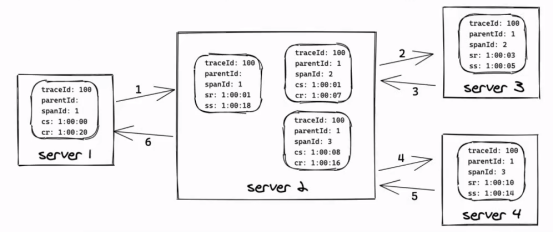
1)Span:基本工作单元,例如,在新建的span中发送一个RTC等同于发送一个回应请求给RTC,span通过一个64位ID唯一标识,span还有其它数据信息,比如摘要、时间戳事件、关键值注释(tags)、span的ID、以及进度ID(通常是IP地址),span在不断的启动停止,同时记录时间信息,在你创建了一个span,你必须在未来的某个时间停止它。
2)Trace:它是树状结构,有一系列span组成。例如,如果你正在跑一个分布式工程,你可能需要创建一个trace。
3)Annotation:用来及时记录一个事件的存在,一些核心的annotations用来定义一个请求的开始时间和结束时间。
① cs -Client Send 客户端发起一个请求,这个annotion描述了这个span的开始。
② sr - Service Received 服务端获得请求并开始处理它,如果将其sr-cs的时间戳便可得到网络延迟。
③ ss-Service Send 表明请求处理的完成(当请求返回客户端),如果ss-Service Received 是服务需要处理的时间
④ cr-Client Received span结束,客户端成功接收到服务端的回复。cr-ss得到的时间戳得到客户端从服务端获取回复所需要的时间。
4)采样率
如果服务的流量很大,全部采集对传输、存储压力比较大。这个时候可以设置采样率,sleuth可以通过配置spring.sleuth.sampler.probability=X.Y(如配置为1.0,则采样率为100%,采集服务的全部追踪数据),若不配置默认采样率是0.1(即10%)。也可以通过实现bean的方式来设置采样为全部采样(AlwaysSampler)或者不采样(NeverSampler):如
@Beanpublic Sampler defaultSampler()
{return new AlwaysSampler();}
sleuth采样算法的实现是 Reservoir sampling(水塘抽样)。实现类是 PercentageBasedSampler。
附水塘抽样算法:https://www.cnblogs.com/krcys/p/9121487.html
4、Zipkin
ZIpkin 是Twitter的一个开源项目,它基于Google Dapper 实现,它致力于收集服务的定时数据,以解决服务架构中的延时问题,包括数据的收集、存储、查找和展现。我们可以使用它来收集各个服务器上请求链路的跟踪数据,并通过它提供Rest API 接口来辅助我们查询跟踪数据以实现对分布式系统的监控程序,从而及时地发现系统中出现的延迟升高问题并找出系统性能瓶颈的根源。除了面向开放的API接口之外,它也提供了方便的UI组件来帮助我们直观的搜索跟踪信息和分析请求链路的明细,比如可以查询某段时间内各用户请求的处理时间。
Zipkin 提供了可插拔数据存储方式:In-Memory、MySql、Cassandra 以及 Elasticsearch。接下来的测试为方便直接采用 In-Memory 方式进行存储,生产推荐 Elasticsearch

二、环境搭建
依赖jdk8、mysql
1、下载zipkin.jar包
用wget下载zipkin官方最新jar包(注意:zipkin需要java8,请事先确保环境为java8环境)具体命令如下:
curl -fL -o 'zipkin.jar' 'https://maven.aliyun.com/repository/central/io/zipkin/zipkin-server/2.23.2/zipkin-server-2.23.2-exec.jar'
2、 启动zipkin.jar
java -jar zipkin.jar
启动成功后默认是内存存储。
3、 Zipkin mySql方式存储配置
1)建立数据库zipkin,初始化数据。
2)在zipkin.jar同级目录创建zipkin-server.properties文件
文件内容配置如下
zipkin.storage.type=mysql
zipkin.storage.mysql.host=localhost
zipkin.storage.mysql.port=3306
zipkin.storage.mysql.username=root zipkin.storage.mysql.password=123456
3)重新启动
java -jar zipkin.jar
三、Sleuth案例
1、创建sleuth-example maven项目
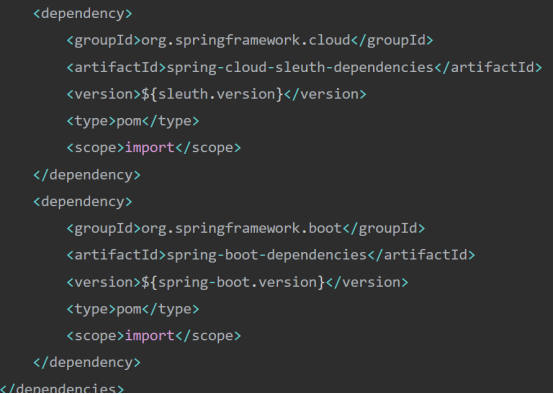
2、修改pom.xml
引入spring-boot-dependencies和spring-cloud-sleuth-dependencies
3、创建子项目user 和sale
Pom的依赖加上
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-zipkin</artifactId> </dependency>
4、启动sale、user 模块
访问连接
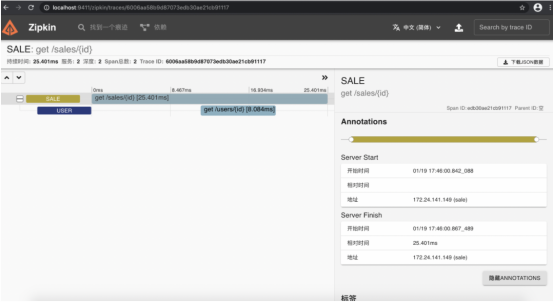
5、Zipkin
在浏览器输入http://localhost:9411/
四、原理分析
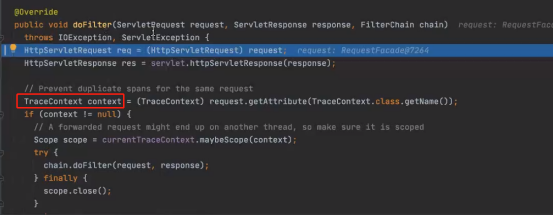
1、doFilter
具体的工作由doFilter去做
Sala服务第一次调用这个方法时,traceContext是没有值的,sala调用user接口是,再次进入doFilter,这是traceContext已经有值。
2、sleuth支持范围
具体怎么采集,依赖zipKin的一些包。
3、自动配置
找meta-info下面的spring.factories
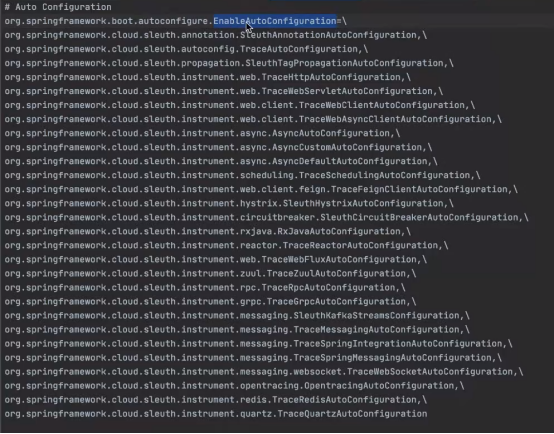
4、TraceWebServletAutoconfiguration
该类主要是初始化TracingFilter
@Bean @ConditionalOnMissingBean public TracingFilter tracingFilter(HttpTracing tracing) { return (TracingFilter) TracingFilter.create(tracing); }
五、常见的链路追踪技术
1、cat
由大众点评开源,基于java开发的实时应用监控平台,包括实时应用监控,业务监控。是通过代码埋点的方式实现监控,比如拦截器,过滤器等。对代码的入侵性很大,集成成本高,风险较大。
2、zipkin
由TWitter公司开源,分布式跟踪系统,用于手机服务的定时数据,已解决微服务架构之间的延迟问题,包括数据的收集、存储、查找和展现。该产品结合spring-cloud-sleuth,使用较为简单,但功能较简单。
3、pinpoint
由韩国人开源的基于字节码注入的调用链分析,以及应用监控分析工具,特点是支持多种插件,UI功能强大,接入端无代码入侵。
4、skywalking
是本土开源的基于字节码注入的调用链分析,以及应用监控分析工具。特点和pinpoint差不多。
启动
Java -javaagent:G:\github\incubator-skywalking\skywalking-agent\skywalking-agent.jar -Dskywalking.agent.service_name=test -jar app.jar
具体到每一个service的执行时间
链路分析、跟踪、监控

 浙公网安备 33010602011771号
浙公网安备 33010602011771号