
Kafka
Kafka
一、kafka基本介绍
是一个开源的分布式事件流平台,用它实现高性能数据传输,流分析,数据集成和关键任务等相关的应用程序。
1、作用
1)削峰填谷
2)应用解耦
3)异步处理
4)消息通讯
消息的方式
1)点对点
1)发布-订阅
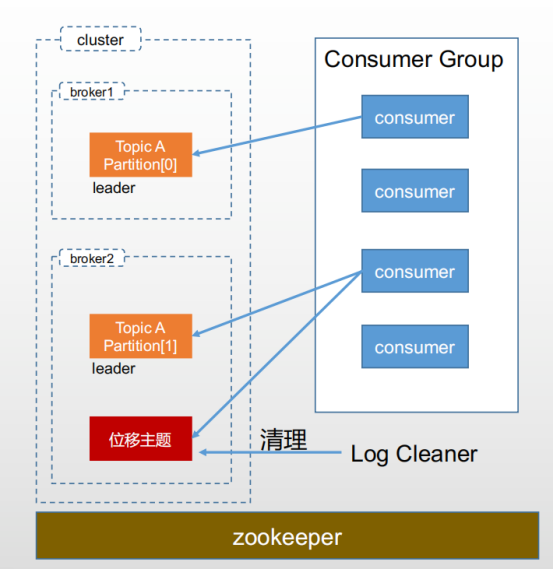
1、kafka的架构图
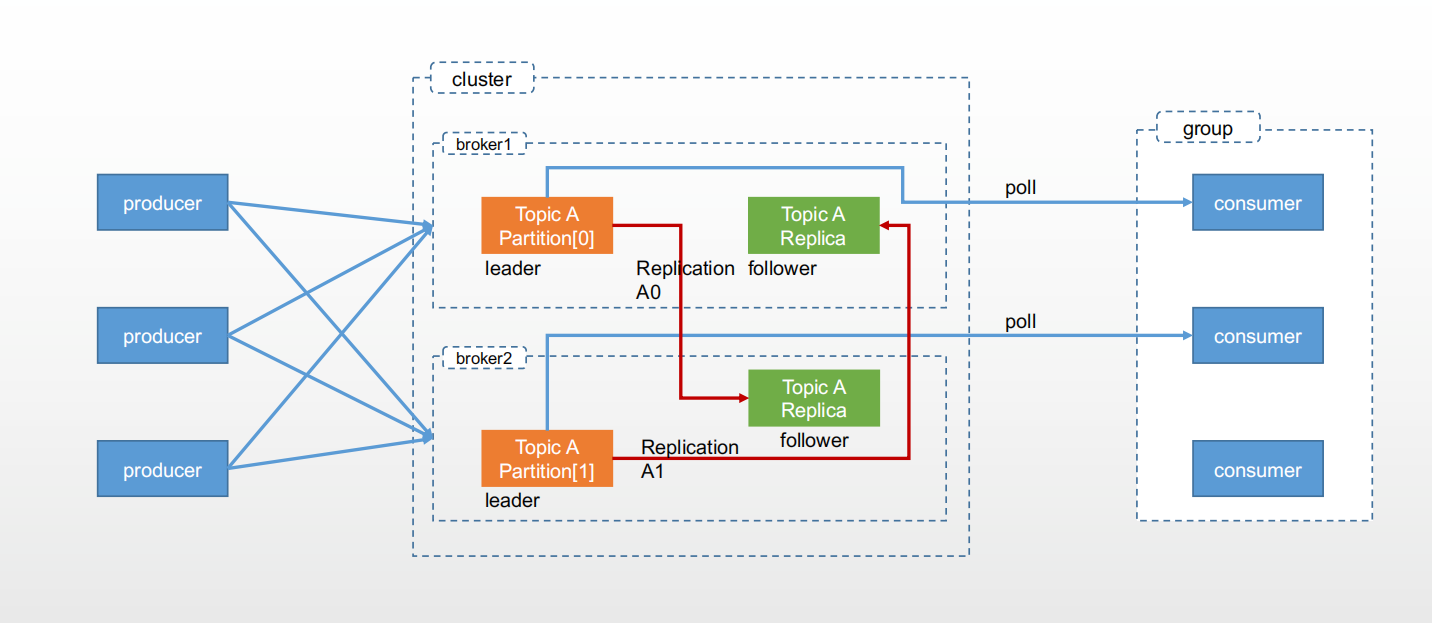
消息:Record。这里的消息就是指Kafka处理的主要对象。
主题:Topic。主题是承载消息的逻辑容器,在实际应用中用来区分具体的业务
分区:Partion。一个有序不变的消息序列。每个主题下可以有多个分区。
消息位移:Offset。表示分区中每条消息的位置信息,是一个单调递增的值
副本:Replica。Kafka中同一条消息能被拷贝到多个地方以提供数据冗余。
分主从,可以保证高可用。所有消息的写入和读取都是通过leader,follower只是做一个备份。
重平衡:Rebalance,消费者组某个消费者实例挂掉后,其它消费者实例自动重新分配订阅主题分区的过程。Rebalance是kafka实现高可用的重要手段。
一、kafka入门
1、安装步骤和使用笔记:
http://note.youdao.com/s/NpKpVSh7
常用lunix命令 cd bin
Ls 查看bin下面的文件目录。
Cat service.propertitys 看service.propertitys 文件里面具体内容
连接zookeeper,指定breaker的id。
源数据放到zookeeper里面。通过查看kafka的启动情况
在zookeeper 的bin目录下,zkCli.sh -server 127.0.0.1:2181
Consumer_offsets 之前放到zk里面,后来用kafka自身的主题存消费者位移。
Partitions一般三个,如果保证高可用,一般5个。
2、Kafka集群部署
1)参数
考虑性能要求,磁盘(机械、固态、RAID磁盘阵列)
磁盘容量(新增消息数、消息留存时间、平均消息大小、备份数、是否启用压缩)最好的压缩算法是20:1
磁盘容量计算方法:消息条数*平均消息大小*副本数/1024/1024
2)Broker参数
① 存储类:log.dirs=/home/kafka1,/home/kafka2,/home/kafka3
ZooKeeper相关: zookeeper.connect=zk1:2181,zk2:2181,zk3:2181/kafka1
② 连接类:listeners=CONTROLLER: //localhost:9092
listener.security.protocol.map=CONTROLLER:PLAINTEX
③ Topic管理
auto.create.topics.enable:false 不能自立为王
unclean.leader.election.enable:false 宁缺毋烂
auto.leader.rebalance.enable:false 江山不易改
④ 数据留存
log.retention.{hours|minutes|ms} :数据寿命 hours=168
log.rentention.bytes: 祖宅大小 -1 表示没限制
message.max.bytes: 祖宅大门宽度,默认1000012=976KB,建议改大点儿
3)主题级别参数
①消息保存
• retention.ms 规定了该 Topic 消息被保存的时长
• retention.bytes 规定了要为该 Topic 预留多大的磁盘空间
②消息大小
max.message.bytes Kafka Broker 能够正常接收该 Topic 的最
大消息大小 一般配置 5M
4)JVM参数
二、kafka客户端
1、kafka生产者架构
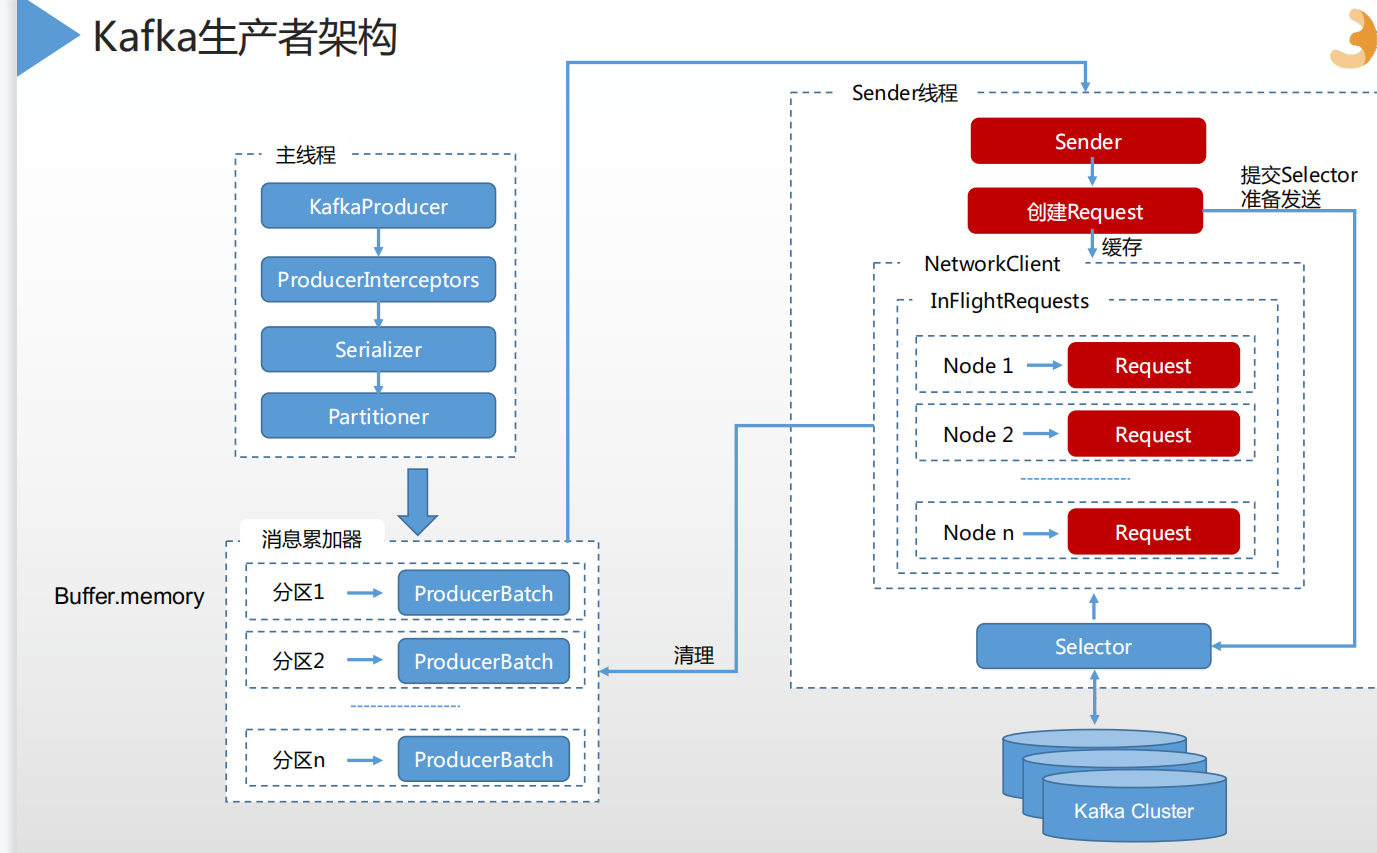
主线程:产生消息后,通过拦截器对消息的加工处理;再通过Serializer对消息序列化,partitioner对消息进行分区;再把消息进行缓存,攒成1批,进行批量发送,又sender线程发送
1、kafka消费端
消费端分区分配策略
RangeAssignor分配策略
RoundRobinAssignor分配策略
StickyAssignor分配策略
消费再均衡Rebalance
• 组成员数量发生变化
• 订阅主题数量发生变化
• 订阅主题的分区数发生变化
消费者协调器和消费组协调器
• 第一阶段 (FIND_COORDINATOR)
• 第二阶段 (JOIN_GROUP)
• 第三阶段(SYNC_GROUP)
• 第四阶段(HEARTBEAT)
1、生产者
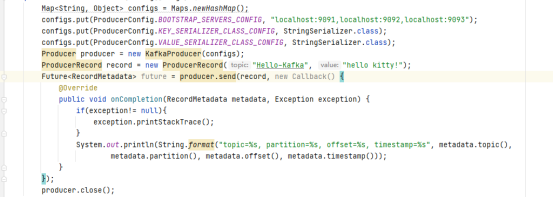
1)同步发送消息
2)异步发送消息
3)自定义拦截器
把消息加一个前缀、统计消息的成功数和失败数;
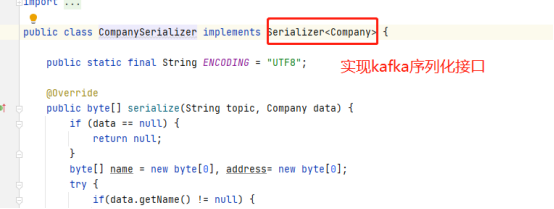
4)自定义序列化器
如果相传实体,需要自定义序列化器;
configs.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, CompanySerializer.class);
消费时,设置反序列化
5)自定义分区器
1、消费者
1)顺序消费
2)模糊匹配订阅多主题
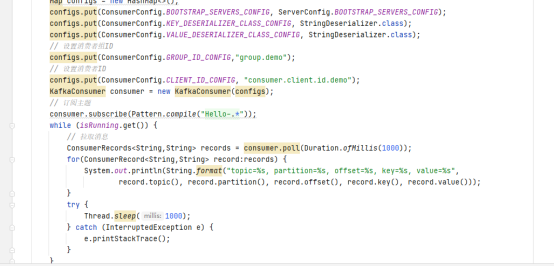
3)多线程消费
4)指定分区消费
// 分配对应的分区
consumer.assign(ImmutableList.of(new TopicPartition("Hello-Kafka", 0))); 指定只消费某个区,用在不同的业务进行划分,消费某一个业务的消费,保证消息的有序行。保证消息有序,发到1个分区。
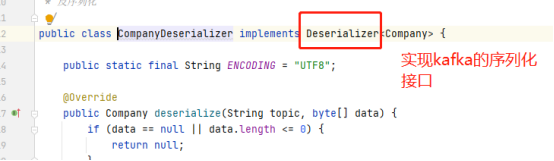
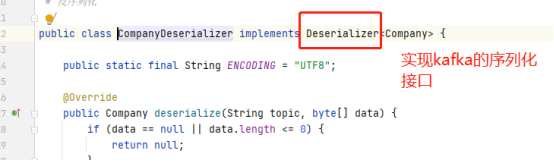
5)自定义反序列化器
// 设置对应的反序列化接口
configs.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, CompanyDeserializer.class.getName());
一、kafka原理
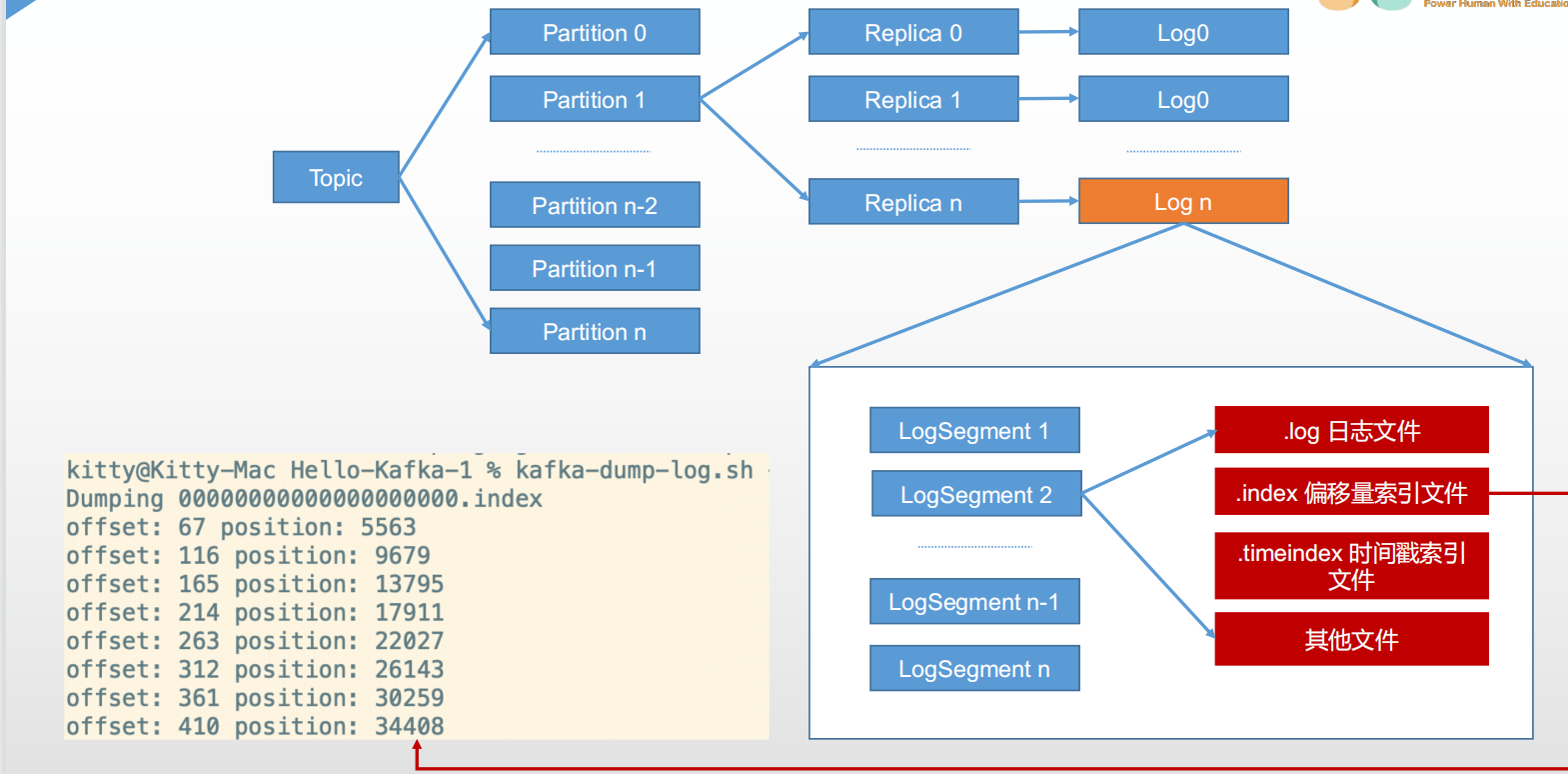
1、文件存储
如何快速的进行文件索引呢?
索引文件有一个偏移量 offset,其次是position,记录具体位置
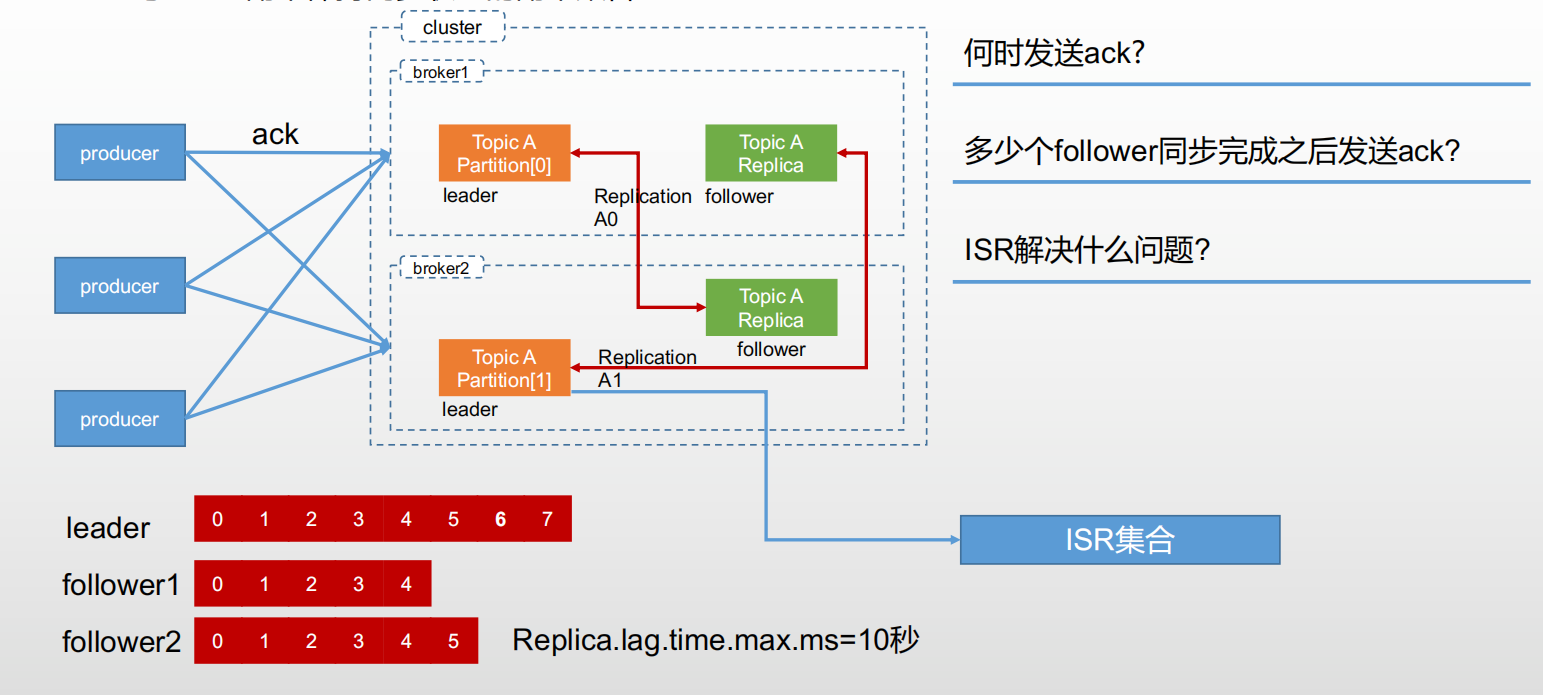
2、数据可靠性
1)AR分区中所有副本
2)ISR与leader副本保持同步状态的副本集合。
1)数据可靠性LEO和HW
LEO表示每个分区中最后一条消息的下一个位置
ISR中最小的LEO为HW
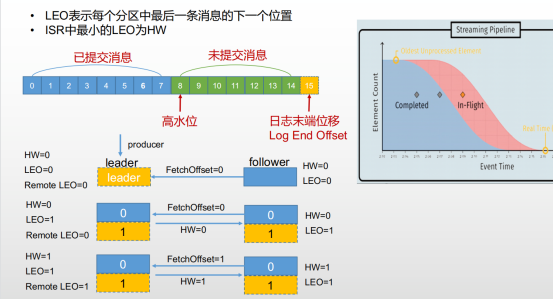
Follower根据HW进行日志截断
Follower副本的HW不能高于leader
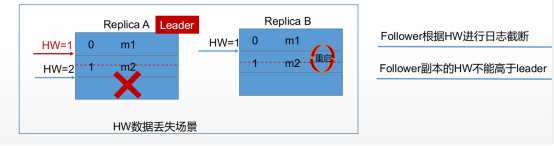
数据丢失场景,原始:Replica A的高水位是1,ReplicaB的高水位也是1。
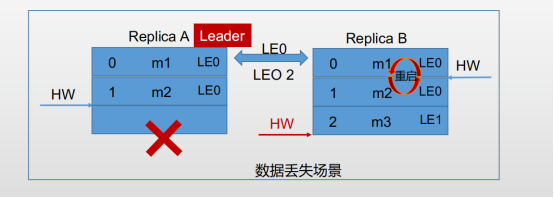
Replica A 又存入1条消息,高水位变为2; ReplicaB在同步ReplicaA的数据时发生重启,同步失败,ReplicaB重启成功,还未同步Replica A宕机,通过重新选举ReplicaB为leader,Replica A恢复后,作为从,根据Follower副本的HW不能高于leader,Replica A的HW重置为1,导致m2数据丢失。
Kafka的解决方案:引入Leader Epoch,当每进行一次选举时LE增加1,当ReplicaB成为主节点时,Leader Epoch 变为LE1,Replica A重启后,进行HW重置,发现两边的LE不相等,把Replica A的数据同步过去,HW变为2,防止了数据的丢失
4)Kafka 高性能 顺序写入、批量、压缩
顺序写入 -append only
消息累加器,批量发送
压缩算法:gzip 、snappy、lz4
Kafka使用了 页缓存,Kafka写完消息并不是等到消息落到硬盘上,只要写到页缓存里面代表消息已经发送成功。磁盘的交互是通过操作系统完成的,通过调整页缓存大小,提高kafka的吞吐量。
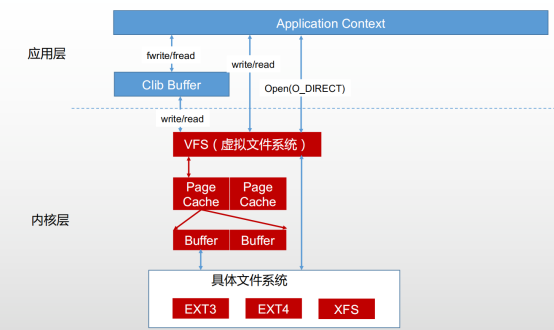
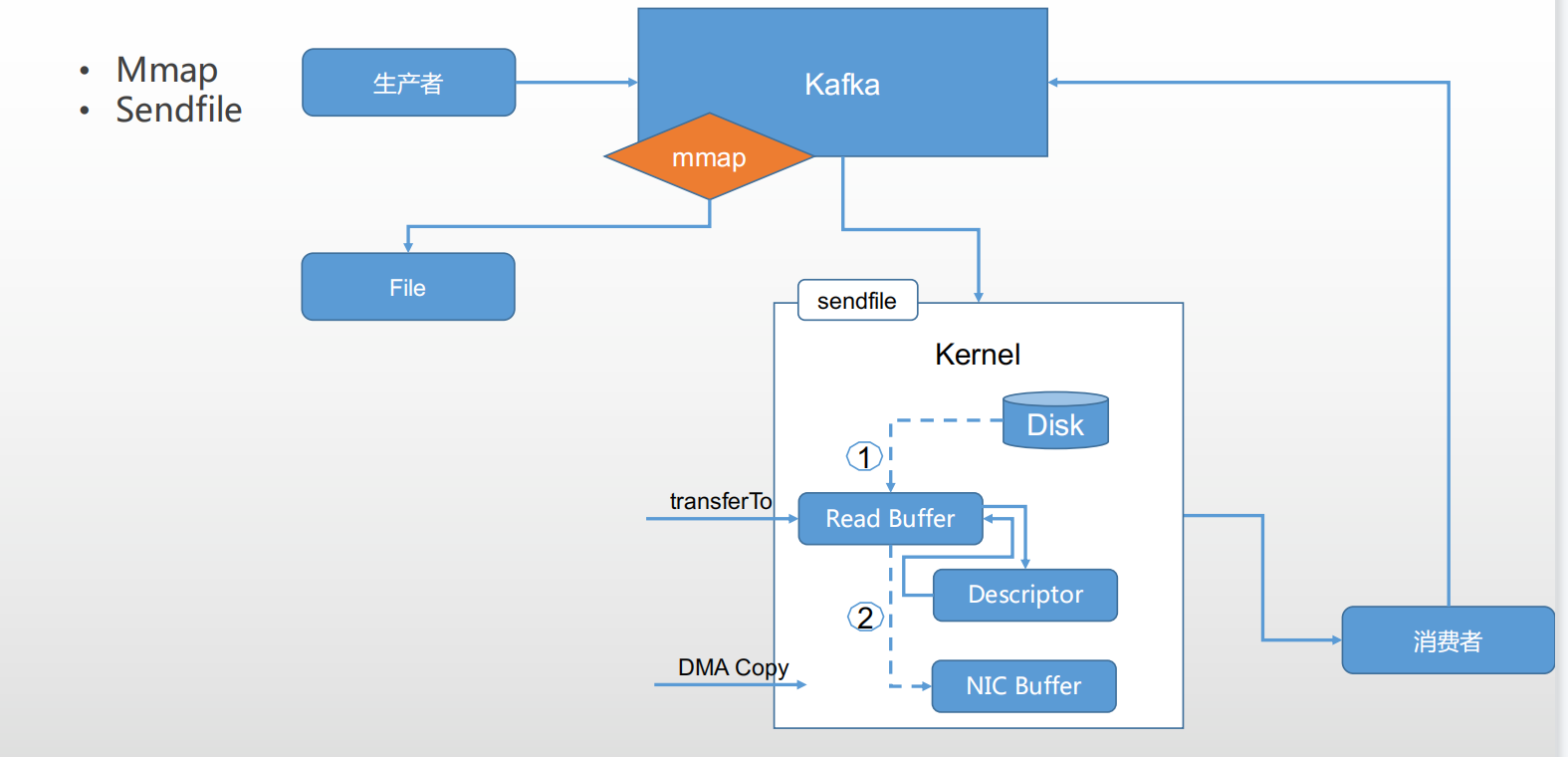
1)kafka高性能,0拷贝。
利用sendfile函数,将文件拷贝到kernel buffer中;消费者直接读取,经历了2次copy,传统需要4次,提高了性能

 浙公网安备 33010602011771号
浙公网安备 33010602011771号