

Golang 网络爬虫框架gocolly/colly 五 获取动态数据
Golang 网络爬虫框架gocolly/colly 五 获取动态数据
gcocolly+goquery可以非常好地抓取HTML页面中的数据,但碰到页面是由Javascript动态生成时,用goquery就显得捉襟见肘了。解决方法有很多种,一,最笨拙但有效的方法是字符串处理,go语言string底层对应字节数组,复制任何长度的字符串的开销都很低廉,搜索性能比较高;二,利用正则表达式,要提取的数据往往有明显的特征,所以正则表达式写起来比较简单,不必非常严谨;三,使用浏览器控件,比如webloop;四,直接操纵浏览器,比如chromedp。一和二需要goquery提取javascript,然后再提取数据,速度非常快;三和四不需要分析脚本,在浏览器执行JavaScript生成页面后再提取,是比较偷懒的方式,但缺点是执行速度很慢,如果在脚本非常复杂、懒得分析脚本的情况下,牺牲下速度也是不错的选择。
不同的场景,做不同的选择。中证指数有限公司下载中心提供了行业市盈率下载,数据文件的Url在页面的脚本中,脚本简单且特征明显,直接用正则表达式的方式是最好的选择。

下载地址对应一段脚本
<a href="javascript:;" class="ml-20 dl download1">下载<i class="i_icon i_icon_rar ml-5"></i></a>
<script> $(function() { //切换 $('.hysyl_con').rTabs({ bind: 'click', auto: false, }); tabs($('.snav .tab_item'),$('.sCon .tab-con-item')); tabs($('.snav2 .tab_item'),$('.sCon2 .tab-con-item')); tabs($('.snav3 .tab_item'),$('.sCon3 .tab-con-item')); $("#search_code1").on("click",function(){ var csrc_code = $("#csrc_code1").val(); if (csrc_code == '') { return false; } var url = "http://www.csindex.com.cn/zh-CN/downloads/industry-price-earnings-ratio-detail?date=2018-01-19&class=1&search=1&csrc_code="+csrc_code; $("#link_1").attr('href', url); document.getElementById("link_1").click(); }) $("#search_code2").on("click",function(){ var csrc_code = $("#csrc_code2").val(); if (csrc_code == '') { return false; } var url = "http://www.csindex.com.cn/zh-CN/downloads/industry-price-earnings-ratio-detail?date=2018-01-19&class=1&search=1&csrc_code="+csrc_code; $("#link_2").attr('href', url); document.getElementById("link_2").click(); }) }) $(".download1").on("click",function(){ var date = $(".date1").val(); date = date.replace(/\-/g, ''); if (date) { $("#link1").attr('href', 'http://115.29.204.48/syl/'+date+'.zip'); document.getElementById("link1").click(); } }); $(".download2").on("click",function(){ var date = $(".date2").val(); date = date.replace(/\-/g, ''); if (date) { $("#link2").attr('href', 'http://115.29.204.48/syl/csi'+date+'.zip'); document.getElementById("link2").click(); } }); $(".download3").on("click",function(){ var date = $(".date3").val(); date = date.replace(/\-/g, ''); if (date) { $("#link3").attr('href', 'http://115.29.204.48/syl/bk'+date+'.zip'); document.getElementById("link3").click(); } }); </script>
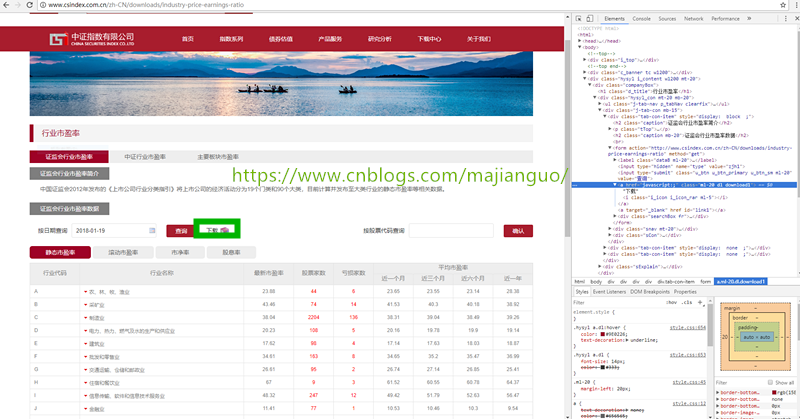
点击下载时,为link1元素生成href属性,然后点击link1,这需要用gocolly+goquery提取date,然后获取服务器地址http://115.29.204.48/,根据获取文件的类型拼接字符串生成下载地址。
获取交易日期
sTime := ""
var bodyData []byte
c:= colly.NewCollector()
c.OnResponse(func (resp *colly.Response) {
bodyData = resp.Body
})
c.OnHTML("input[name=date]",func (el *colly.HTMLElement) {
sTime = el.Attr("value")
})
err = c.Visit("http://www.csindex.com.cn/zh-CN/downloads/industry-price-earnings-ratio")
if err != nil {
return
}
获取文件服务器地址,下载zip文件
htmlDoc,err := goquery.NewDocumentFromReader(bytes.NewReader(bodyData))
if err != nil {
return
}
scripts := htmlDoc.Find("script")
destScript := ""
for _,n := range scripts.Nodes {
if n.FirstChild != nil {
if strings.Contains(n.FirstChild.Data,"syl/csi") && strings.Contains(n.FirstChild.Data,".download2"){
destScript = n.FirstChild.Data
break
}
}
}
re,err := regexp.Compile("http://[0-9]+.[0-9]+.[0-9]+.[0-9]+/syl/csi")
if err != nil {
log.Fatal(err)
}
result := re.FindString(destScript)
pos := strings.LastIndex(result,"/")
parentUrl := result[0:pos+1]
link := parentUrl
sTime = strings.Replace(sTime,"-","",-1)
fileName := ""
if t == ZhengJjianHuiHangYePERatio {
fileName = fmt.Sprintf("%s.zip",sTime)
link += fileName
fileName = "zjh"+fileName
}else if t == ZhongZhengHangYePERatio {
fileName = fmt.Sprintf("csi%s.zip",sTime)
link += fileName
}else {
fileName = fmt.Sprintf("bk%s.zip",sTime)
link += fileName
}
fmt.Println(link)
cli:=http.Client{}
resp,err := cli.Get(link)
if err != nil {
return
}
defer resp.Body.Close()
fullFileName := fmt.Sprintf("%s/%s",filePath,fileName)
if resp.StatusCode == 200 {
allBody,err := ioutil.ReadAll(resp.Body)
if err != nil {
return err
}
err = ioutil.WriteFile(fullFileName,allBody,0666)
if err != nil {
return err
}
}else{
err = fmt.Errorf("bad resp.%d",resp.StatusCode)
return
}
err = archiver.Zip.Open(fullFileName, filePath)
在脚本里匹配服务器ip地址用 http://[0-9]+.[0-9]+.[0-9]+.[0-9]+/syl/csi
,因为前后都有限定元素,所以写得比较简单;如果没有前后限定条件,设计正则表达式就得多费心了,复杂的正则表达式会吓跑很多人。不过没关系,稍微了解一些正则表达式的知识,就可以用在爬虫上了。
下载的文件是excel(.xls格式)的zip压缩包,解压缩操纵及xls读取后面再介绍。
转载请注明出处:https://www.cnblogs.com/majianguo/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号