图像分割学习笔记1
1、显著性检测(Saliency Detection)
1.1 两类问题
①显著性物体分割(Salient object segmentation)--- 最能引起人的视觉注意的物体区域
②注视点预测(Fixation prediction)--- 通过对眼动的预测和研究探索人类视觉注意机制
1.2 两种策略的视觉注意机制
①自底而上基于数据驱动的注意机制
1)从数据出发
2)与周边有较强对比度或差异
3)颜色、亮度、边缘等特征
②自上而下基于任务驱动的目标的注意机制
1)从认知因素出发,如知识、预期、兴趣等
1.3 Pascal VOC数据集
①显著物体标注 ②眼动数据
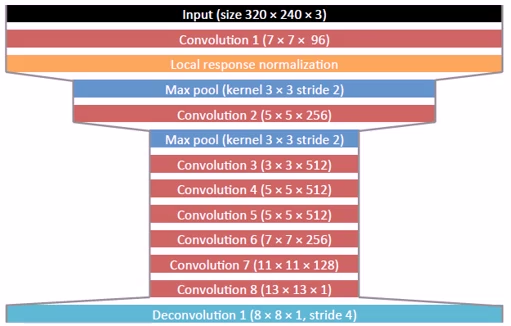
如下图所示,由VGG修改而成DNN模型,用于显著性检测,最后一层是一个解卷积层。
2、物体分割(Object Segmentation)
2.1 前景背景分割
①前景一般包含物体 ②需要交互提供初始标记(提供一些简单的初始标记,使分割更好)
2.2 Graph Cuts分割
最基本的分割算法一般都是基于图论。
①基于图论的分割方法
②分割模型
1)每个像素都一个节点
2)最小割最大流算法优化
2.3 GrabCut分割
①前景/背景的颜色模型
1)高斯混合模型
2)Kmeans算法获得
②迭代进行Graph Cuts
1)优化前景和背景的颜色模型
2)能量随着不断迭代变小
3)分割结果越来越好
③算法流程
1)使用标记初始化颜色模型(K=5)
2)执行Graph Cuts
3、语义分割(Semantic Segmentation)
3.1 什么是语义分割
①目标
1)从像素水平(pixel-level)上,理解、识别图片的内容
2)根据语义信息分割
②输入
图片
③输出
1)同尺寸的分割标记(像素水平)
2)每个像素会被识别为一个类别(category)
3.2 语义分割的用处
①机器人视觉和场景理解
②辅助/自动驾驶
③医学X光
3.3 算法研究阶段
①2015年以前:手工特征+图模型(CRF)
②2015开始:深度神经网络模型
1)思路:改进CNN,并使用预训练CNN层的参数
2)传统CNN的问题
后半段网络无空间信息
输入图片尺寸固定
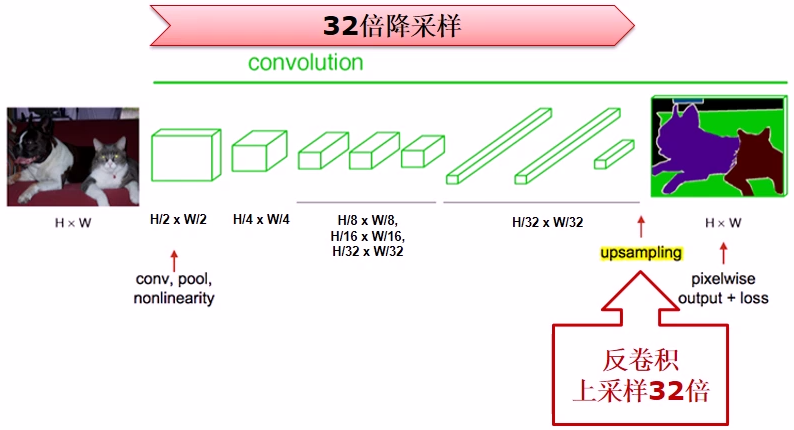
3)全卷积网络(Fully Convolutional Networks)
所有层都是卷积层
解决降采样后的低分辨率问题
3.4 全卷积网络(Fully Convolutional Networks-FCN)
①卷积化(Convolutionalization)
1)将所有全连接层转换成卷积层
2)适应任意尺寸输入,输出低分率分割图片
②反卷积(Deconvolution)
1)将低分辨率图片进行上采样,输出同分辨率分割图片
③跳层结构(Skip-layer)
1)精化分割图片
3.4.1 FCN-卷积化的降维问题
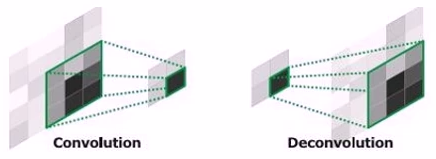
3.4.2 FCN-反卷积(Deconvolution)
①一对多操作
②卷积的逆操作
1)小数步长1/f
2)卷积核尺寸不变
③前向和后向传播
1)对应卷积操作的后向和前向传播,优化上做颠倒
2)反卷积核实卷积核的转置,学习率为0
④也叫转置卷积(Transposed convolution)
⑤可以拟合出双线性插值
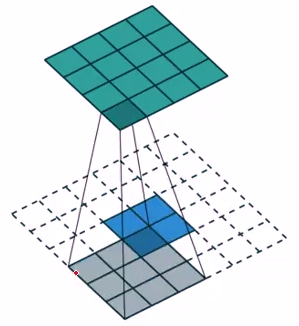
例如:
1)外围全补零(Full padding)反卷积
2)输入:2x2
3)输出:4x4
4)参数设置:
卷积核尺寸:3x3
步长:1
Padding:2
5)被Skip-layer使用
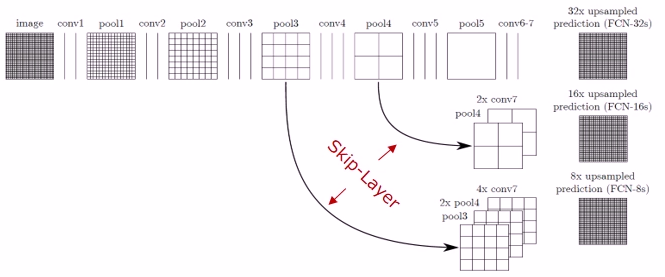
3.4.3 FCN-跳层结构(Skip-layer)
①原因:直接使用32倍反卷积得到的分割结果粗糙
②使用前2个卷积层的输出做融合
1)跳层:Pool4和Pool3后会增加一个1x1卷积层做预测
2)较浅网络的结果精细,较深网络的结果鲁棒
③最后的反卷积层
1)固定为双线性插值
2)不学习
④中间的反卷积层
1)初始化为双线性插值
2)需要学习
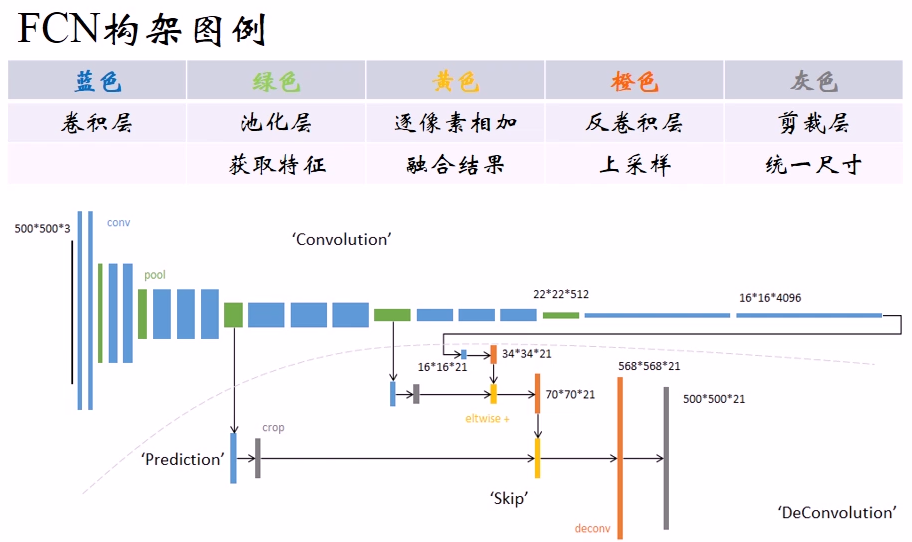
3.4.4 使用AlexNet构建FCN
①第一步
1)使用AlexNet作为初始网络,保留参数
2)舍弃最后1个全连接层
②第二步(FCN-32s网络)
1)替换为两个同深度的卷积层(4096,1,1)-> 16x16x4096
2)追加一个预测卷积层(21,1,1)-> 16x16x21
3)追加一个步长为32的双线性插值反卷积层 -> 500x500x21
③第三步(FCN-16s网络)
1)对最终层Conv7结果2倍上采样 -> 34x34x21
2)提取Pool4输出,追加预测卷积层(21,1,1)-> 34x34x21
3)相加融合 ->34x34x21
4)追加一个步长为16的双线性插值反卷积层 ->500x500x21
④第四步(FCN-8s网络)
1)对上次融合结果2倍上采样 ->70x70x21
2)提取Pool3输出,追加预测卷积层(21,1,1)->70x70x21
3)相加融合 ->70x70x21
4)追加一个步长为8的双线性插值反卷积层 ->500x500x21
3.4.5 FCN训练
①SGD with momentum(0.9)
1)Learning rate
0.001(AlexNet),0.0001(VGG16),0.00001(GoogLeNet)
2)Minibatch:20
②初始化
1)卷积层
前5个卷积层使用初始CNN网络的参数
剩余第6和7卷积层初始化为0
2)反卷积层
最后一层反卷积层固定为双线性插值,不做学习
剩余反卷积层初始化为双线性插值,做学习
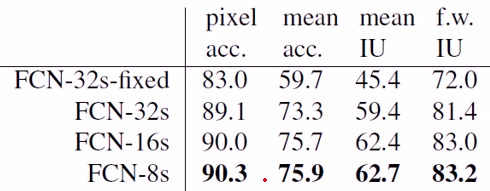
3.4.6 FCN的跳层结构性能
FCN-8s最优

3.4.7 FCN-8s的Pascal VOC竞赛结果
①边缘准确性比较差
1)第一个卷积层大量补零
2)之后做裁剪
3)保证输出分辨率
4)带来噪声


 浙公网安备 33010602011771号
浙公网安备 33010602011771号