04 python字符串
1、长字符串
- 跨越多行的字符串,可使用三个引号(而不是一个引号),即长字符串。
- 请注意,这让解释器能够识别表示字符串开始和结束位置的引号,因此字符串本身可包含单引号和双引号,无需使用反斜杠进行转义。
- 长字符串的作用:一是保留多行字符串的格式(转义字符依然有效),二是注释多行。
print('''This is a very long string. It continues here.
And it's not over yet. "Hello, world!"
Still here.''')
- 常规字符串也可横跨多行。只要在行尾加上反斜杠,反斜杠和换行符将被转义,即被忽略。
>>> 1 + 2 + \
4 + 5
12
>>> print("hello,\
world!")
hello,world!
>>> print \
('Hello, world')
Hello, world
2、原始字符串
- 原始字符串用前缀r表示。
- 原始字符串不以特殊方式处理反斜杠。
>>> print(r'C:\Program Files\fnord\foo\bar\baz\frozz\bozz') C:\Program Files\fnord\foo\bar\baz\frozz\bozz
- 原始字符串不能以单个反斜杠结尾。换而言之,原始字符串的最后一个字符不能是反斜杠,除非你对其进行转义(但进行转义时,用于转义的反斜杠也将是字符串的一部分)。
>>> print(r"This is illegal\") SyntaxError: EOL while scanning string literal >>> print(r"This is illegal\\") This is illegal\\
- 以反斜杠结尾的原始字符串,基本技巧是将反斜杠单独作为一个字符串。
>>> print(r'C:\Program Files\foo\bar' '\\') C:\Program Files\foo\bar\
- 在原始字符串中可以包含任何字符,但有个例外,引号依然会被转义,而且用于执行转义的反斜杠也将包含在最终的字符串中。
>>> print(r'Let\'s go!') #注意,这都是单引号。用双引号标识字符串可以不转义单引号 Let\'s go!
- 指定原始字符串时,可使用单引号或双引号将其括起,还可使用三引号将其括起来。
3、字符串:不可变的字符序列
-
字符串就是由字符组成的序列。
Python没有专门用于表示字符的类型,因此一个字符就是只包含一个元素的字符串。 - Python在打印字符串时,用单引号或双引号将其括起。
>>> 'Hello, world!' 'Hello, world!' >>> "Hello, world!" 'Hello, world!'
- 单引号和双引号是一样的。当字符串中包含一种引号时,可以用另一种引号来标识字符串。
>>> "Let's go!" "Let's go!" >>> '"Hello, world!" she said' '"Hello, world!" she said'
- 反斜杠(\)进行转义。
>>> 'Let's go!' SyntaxError: invalid syntax >>> 'Let\'s go!' "Let's go!"
3.1、字符串基本操作
- 所有标准序列操作(索引、切片、乘法、成员资格检查、长度、最小值和最大值)都适用于字符串。
- 字符串是不可变的,因此所有的元素赋值和切片赋值都是非法的。
>>> website = 'http://www.python.org' >>> website[-3:] = 'com' Traceback (most recent call last): File "<pyshell#1>", line 1, in <module> website[-3:] = 'com' TypeError: 'str' object does not support item assignment
3.2、设置字符串的格式
1、格式字符串中的%s称为转换说明符
>>> print("Hello, %s!" % 'world')
Hello, world!
>>> print("Hello, %s. %s enough for ya?" % ('world', 'Hot')) #有多个时,必须使用小括号括起来
Hello, world. Hot enough for ya?
>>> print("我是%s,今年%d岁" % ('麦恒', 22))
我是麦恒,今年22岁
2、模板字符串
>>> from string import Template
>>> tmpl = Template("Hello, $who! $what enough for ya?")
>>> tmpl.substitute(who="Mars", what="Dusty")
'Hello, Mars! Dusty enough for ya?'
3、字符串方法format
- 每个值都被插入字符串中,以替换用花括号括起的替换字段。
- 要在最终结果中包含花括号,可在格式字符串中使用两个花括号(即{{或}})来指定。
>>> price_width = 10
>>> item_width=20
>>> header_fmt = '{{:{}}}{{:>{}}}'.format(item_width, price_width)
>>> header_fmt
'{:20}{:>10}'
>>> header_fmt = '{{:{}}}{{:>{}}}'.format(item_width, price_width).format('Item','Price')
>>> header_fmt
'Item Price'
>>> '{:20}{:<30}'.format('Item','Price')
'Item Price '
4、替换字段由如下部分组成,其中每个部分都是可选的
(1)字段名:索引或标识符
- format中未命名参数必须在前面,且个数不少于{}的数量
>>> "{foo} {} {bar} {}".format(1, 2, bar=4, foo=3)
'3 1 4 2'
- 不能同时使用手工编号和自动编号,会变得混乱不堪
>>> "{foo} {1} {bar} {0}".format(1, 2, bar=4, foo=3)
'3 2 4 1'
- 索引无需按顺序排列。
>>> "{3} {0} {2} {1} {3} {0}".format("be", "not", "or", "to")
'to be or not to be'
- 命名字段的工作原理与你预期的完全相同。
>>> from math import pi
>>> "{name} is approximately {value:.2f}.".format(value=pi, name="π")
'π is approximately 3.14.'
- 在Python 3.6中,如果变量与替换字段同名,还可使用一种简写。在这种情况下,可使用f字符串——在字符串前面加上f。
>>> from math import e
>>> f"Euler's constant is roughly {e}."
"Euler's constant is roughly 2.718281828459045."
等价:
>>> "Euler's constant is roughly {e}.".format(e=e) #把替换字段e替换为变量e的值
"Euler's constant is roughly 2.718281828459045."
- 可使用索引,还可使用句点表示法来访问导入的模块中的方法、属性、变量和函数
>>> fullname = ["Alfred", "Smoketoomuch"]
>>> "Mr {name[1]}".format(name=fullname)
'Mr Smoketoomuch'
>>> import math
>>> tmpl = "The {mod.__name__} module defines the value {mod.pi} for π"
>>> tmpl.format(mod=math)
'The math module defines the value 3.141592653589793 for π'
(2)转换标志:跟在叹号后面的单个字符
- s:函数str通常创建外观普通的字符串版本(这里没有对输入字符串做任何处理)。
- r:函数repr尝试创建给定值的Python表示(这里是一个字符串字面量)。
- a:函数ascii创建只包含ASCII字符的表示
>>> print("{pi!s} {pi!r} {pi!a}".format(pi="π"))
π 'π' '\u03c0'
(3)格式说明符:跟在冒号后面的表达式
1)格式说明符
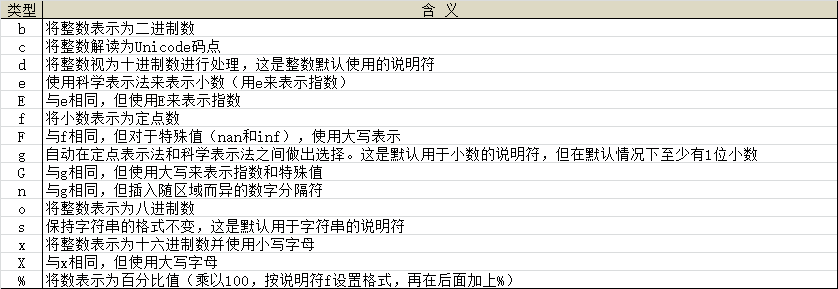
- 设置浮点数的格式时,默认在小数点后面显示6位小数,并根据需要设置字段的宽度,而不进行任何形式的填充
>>> "The number is {num}".format(num=42)
'The number is 42'
>>> "The number is {num:f}".format(num=42)
'The number is 42.000000'
>>> "The number is {num:b}".format(num=42)
'The number is 101010'
2)宽度、精度和千位分隔符
- 宽度是使用整数指定的。
>>> "{num:10}".format(num=3)
' 3'
>>> "{name:10}".format(name="Bob") #数和字符串的对齐方式不同
'Bob '
- 精度也是使用整数指定的,但需要在它前面加上一个表示小数点的句点。
>>> import math
>>> "Pi day is {pi:.2f}".format(pi=math.pi)
'Pi day is 3.14'
>>> from math import pi
>>> "{pi:10.2f}".format(pi=pi)
' 3.14'
>>> "{:.5}".format("Guido van Rossum") #对于其他类型也可指定精度,但是不太常见
'Guido'
- 千位分隔符,同时指定其他格式设置元素时,这个逗号应放在宽度和表示精度的句点之间。
>>> 'One googol is {:,}'.format(10**10)
'One googol is 10,000,000,000'
3)符号、对齐和用0 填充
- 在指定宽度和精度的数前面,可添加一个标志。这个标志可以是零、加号、减号(默认)或空格,其中零表示使用0来填充数字。(仅用于数值)
>>> print("'{0:-.2f}'\n'{1:-.2f}'".format(pi, -pi))
'3.14'
'-3.14'
>>> print("'{0:+.2f}'\n'{1:+.2f}'".format(pi, -pi))
'+3.14'
'-3.14'
>>> print("'{0: .2f}'\n'{1: .2f}'".format(pi, -pi))
' 3.14'
'-3.14'
- 说明符=,它指定将填充字符放在符号和数字之间。(仅用于数值,可以填充任意字符,与<、>和^互斥)
>>> from math import pi
>>> print('{0:=+10.2f}\n{1:=+10.2f}'.format(pi, -pi))
+ 3.14
- 3.14
>>> print('{0:=+10.2f}\n{1:$=+10.2f}'.format(pi, -pi))
+ 3.14
-$$$$$3.14
- 左对齐、右对齐和居中,可分别使用<、>和^。(可以填充任意字符,与说明符 “=”互斥)
>>> from math import pi
>>> print('{0:<10.2f}\n{0:^10.2f}\n{0:>10.2f}'.format(pi))
3.14
3.14
3.14
>>> print('{0:A<10.2f}\n{0:$^10.2f}\n{0:0>10.2f}'.format(pi))
3.14AAAAAA
$$$3.14$$$
0000003.14
- 井号(#),将其放在符号说明符和宽度之间
例如,对于二进制、八进制和十六进制转换,将加上一个前缀。
>>> "{:b}".format(42)
'101010'
>>> "{:#b}".format(42)
'0b101010'
例如,对于各种十进制数,它要求必须包含小数点(对于类型g,它保留小数点后面的零)。
>>> "{:g}".format(42)
'42'
>>> "{:#g}".format(42)
'42.0000'
3.3、字符串方法详解
- 字符串有很多方法,因为其很多方法都是从模块string那里“继承”而来的。
- 虽然字符串方法完全盖住了模块string的风头,但string模块包含一些字符串没有的常量和函数。
string.digits:包含数字0~9的字符串。
string.ascii_letters:包含所有ASCII字母(大写和小写)的字符串。
string.ascii_lowercase:包含所有小写ASCII字母的字符串。
string.printable:包含所有可打印的ASCII字符的字符串。
string.punctuation:包含所有ASCII标点字符的字符串。
string.ascii_uppercase:包含所有大写ASCII字母的字符串。
虽然说的是ASCII字符,但值实际上是未解码的Unicode字符串
1、center(宽度,"字符")
- 方法center通过在两边添加填充字符(默认为空格)让字符串居中。
>>> 'Hello World'.center(20) ' Hello World ' >>> 'Hello World'.center(20,'#') '####Hello World#####'
- 类似的方法:ljust、rjust和zfill。
>>> 'Hello World'.ljust(20,'#') 'Hello World#########' >>> 'Hello World'.rjust(20,'#') '#########Hello World' >>> 'Hello World'.zfill(20) '000000000Hello World'
2、find(子串,起点,终点)
- 方法find在字符串中查找子串。如果找到,就返回子串的第一个字符的索引,否则返回-1。
- 字符串方法find返回的并非布尔值。如果find返回0,就意味着它在索引0处找到了指定的子串。
>>> title = "Monty Python's Flying Circus"
>>> title.find('Monty')
0
>>> title.find('Python')
6
>>> title.find('Zirquss')
-1
- 可指定搜索的起点和终点(它们都是可选的)。包含起点,不包含终点。
>>> subject = '### Get rich now!!! ###'
>>> subject.find('###')
0
>>> subject.find('###',1)
20
>>> subject.find('!!!')
16
>>> subject.find('!!!', 0, 18)
-1
- 类似的方法:rfind、index、rindex、count、startswith、endswith。
3、join(序列)
- join是一个非常重要的字符串方法,其作用与split相反,用于合并序列的元素。
- 所合并序列的元素必须都是字符串。
>>> a = [1, 2, 3, 4, 5]
>>> b = '+'
>>> b.join(a) #尝试合并一个数字列表
Traceback (most recent call last):
File "<pyshell#15>", line 1, in <module>
b.join(a)
TypeError: sequence item 0: expected str instance, int found
>>> a = ['1', '2', '3', '4', '5']
>>> b.join(a) #合并一个字符串列表
'1+2+3+4+5'
>>> dirs = '', 'usr', 'bin', 'env'
>>> '/'.join(dirs)
'/usr/bin/env'
>>> print('C:' + '\\'.join(dirs))
C:\usr\bin\env
4、lower()
- 方法lower返回字符串的小写版本。
>>> 'Trondheim Hammer Dance'.lower() 'trondheim hammer dance'
- 类似的方法:islower、istitle、isupper、translate,capitalize、casefold、swapcase、title、upper。
5、replace(子串,替换的子串)
- 方法replace将指定子串都替换为另一个字符串,并返回替换后的结果。
>>> a = 'This is a test'
>>> a.replace('is', 'eez')
'Theez eez a test'
>>> a
'This is a test'
- 类似的方法:translate,expandtabs。
6、split(单字符)
- split是一个非常重要的字符串方法,其作用与join相反,用于将字符串拆分为序列。
- 注意,如果没有指定分隔符,将默认在单个或多个连续的空白字符(空格、制表符、换行符等)处进行拆分。
>>> '1+2+3+4+5'.split('+')
['1', '2', '3', '4', '5']
>>> '/usr/bin/env'.split('/')
['', 'usr', 'bin', 'env']
>>> 'Using the default'.split()
['Using', 'the', 'default']
- 类似的方法:partition、rpartition、rsplit、splitlines。
7、strip()
- 方法strip将字符串开头和末尾的空白(但不包括中间的空白)删除,并返回删除后的结果。
>>> ' internal whitespace is kept '.strip() 'internal whitespace is kept'
- 还可在一个字符串参数中指定要删除哪些字符,只删除开头或末尾的指定字符。
>>> ' *** SPAM * for * everyone!!! *** '.strip(' *!')
'SPAM * for * everyone'
- 类似的方法:lstrip、rstrip。
8、translate
- 方法translate与replace一样替换字符串的特定部分,但不同的是它只能进行单字符替换。这个方法的优势在于能够同时替换多个字符,因此效率比replace高。
- 使用translate前必须创建一个转换表。
- 使用方法maketrans创建转换表,这个方法接受两个参数:两个长度相同的字符串,它们指定要将第一个字符串中的每个字符都替换为第二个字符串中的相应字符。
>>> table = str.maketrans('cs', 'kz')
>>> 'this is an incredible test'.translate(table)
'thiz iz an inkredible tezt'
- 调用方法maketrans时,还可提供可选的第三个参数,指定要将哪些字母删除。
- 注意,当有第三个参数时,将先进行删除,再进行替换。
>>> table = str.maketrans('cs', 'kz', ' ')
>>> 'this is an incredible test'.translate(table)
'thizizaninkredibletezt'
3.4、字符串方法附录
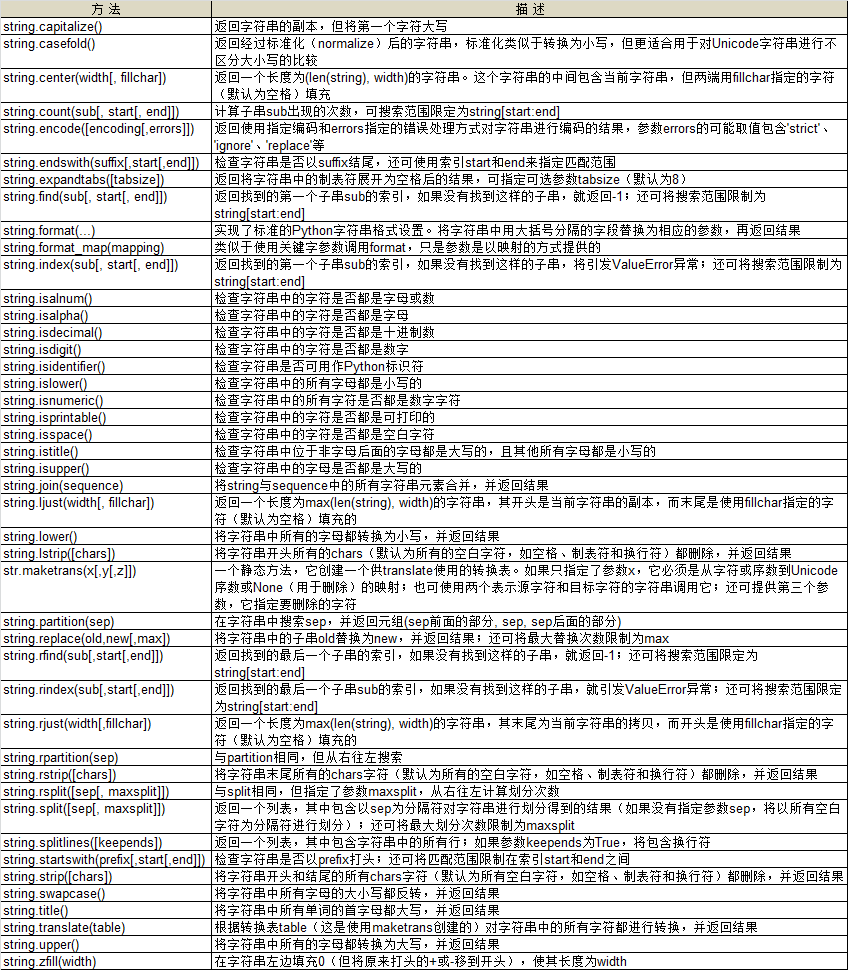
4、练习
(1)将name变量的前三个字符逆序输出。


name = input('请输入一个字符串:') print('您输入的字符串是%s,其前三个字符的逆序是%s' % (name,name[2::-1]))
(2)开发敏感词语过滤程序,提示用户输入内容,如果其输入的内容包含特殊字符,就将其替换为星号(***)。例如滚犊子、你瞅啥、fack。
s_str = input('请输入一个字符串:') lst = ['滚犊子','你瞅啥','fack'] for i in lst: s_str = s_str.replace(i,'***') print('你输入的是:%s' % s_str)
(3)循环提示用户输入:用户名、密码、邮箱,并且用户的输入不能超过20个字符,如果超过则只有前20个字符有效。输入q或Q退出。
输出格式:
用户名 密码 邮箱
Tom 123 tom@hh.com
Jerry 456 jerry@hh.com
print('您好,每次输入不能超过20个字符,如果超过则只有前20个字符有效。') name_l = [] pass_l = [] mail_l = [] while True: name_s = input('请您输入用户名:') pass_s = input('请你输入登录密码:') mail_s = input('请您输入邮箱:') quit_s = input('退出请输入q,继续按回车:') name_l.append(name_s[:20]) pass_l.append(pass_s[:20]) mail_l.append(mail_s[:20]) if quit_s.casefold() =='q': break print('{:<27}{:<28}{:<27}'.format('用户名','密码','邮箱')) for i in range(len(name_l)): print('{:<30}{:<30}{:<30}'.format(name_l[i],pass_l[i],mail_l[i]))
print('您好,每次输入不能超过20个字符,如果超过则只有前20个字符有效。') s = '' while True: name_s = input('请您输入用户名:')[:20] pass_s = input('请你输入登录密码:')[:20] mail_s = input('请您输入邮箱:')[:20] msg = '{}\t{}\t{}\n'.format(name_s,pass_s,mail_s) msg = msg.expandtabs(20) s += msg if name_s.casefold() == 'q' or pass_s.casefold() == 'q' or mail_s.casefold() == 'q': break print(s)
(4)执行程序产生验证码,提示用户输入用户名、密码、和验证码。如果正确,则提示登录成功,否则重新输入(要求产生新的验证码)。
import random hh = 'qwertyuiopasdfghjklzxcvbnmQWERTYUIOPASDFGHJKLZXCVBNM1234567890' while True: code = '' for i in range(4): #range不包含最后一个数 num = random.randint(0, len(hh) - 1) #randint包含最后一个数 code += hh[num] name_s = input('请输入用户名:') pass_s = input('请输入密码:') code_in = input('请输入验证码%s:' % code) if code.casefold() == code_in.casefold(): print('***************************') print('恭喜您登录成功!') break
(5)输入一段英文,统计其中有多少个单词,每两个单词之间以空格隔开。
hh = input('请您输入一段英文:') num_l = hh.split() #split没有指定分隔符,默认使用单个或多个连续的空白字符 num = len(num_l) print('您输入的英文有%s个单词。' % (num))
(6)输入两个字符串,从第一个字符串中删除第二个字符串中的所有字符。例如,输入“I like you!”和“ieo”,则第一个字符串变成“I lk yu!”。
str1 = input('请您输入第一个字符串:') str2 = input('请您输入第一个字符串:') table = str.maketrans('','' , str2) print('结果是:{}'.format(str1.translate(table)))
###方法1: str1 = input('请您输入第一个字符串:') str2 = input('请您输入第一个字符串:') str3 = '' for i in str1: if i not in str2: str3 += i print(str3) ###方法2: str1 = input('请您输入第一个字符串:') str2 = input('请您输入第一个字符串:') for i in str2: str1 = str1.replace(i,'') print(str1)
(7)Jerry喜欢每个字母大写且没有连续相同字母的单词,例如,他喜欢'A'、'ABA',不喜欢'ABBC'。判断输入的一个单词是否是Jerry喜欢的。
print('*********输入q结束*********') while True: hh = input('请您输入一个单词:') if hh.casefold() == 'q': break elif hh.isalpha() and hh.isupper(): for i in range(len(hh)-1): if hh[i] == hh[i+1]: print('Jerry不喜欢这个单词') break else: print('Jerry喜欢这个单词!') else: print('Jerry不喜欢这个单词')
print('*********输入q结束*********') while True: hh = input('请您输入一个单词:') if hh.casefold() == 'q': break for i in range(len(hh)-1): if hh[i] < 'A' or hh[i] > 'Z': print('Jerry不喜欢,不全是大写') break else: if i <= len(hh)-2 and hh[i] == hh[i+1]: print('Jerry不喜欢,有叠词') break else: print('Jerry喜欢')
# #

 浙公网安备 33010602011771号
浙公网安备 33010602011771号