

smile——Java机器学习引擎
资源
https://haifengl.github.io/
https://github.com/haifengl/smile
介绍
Smile(统计机器智能和学习引擎)是一个基于Java和Scala的快速、全面的机器学习、NLP、线性代数、图形、插值和可视化系统。
凭借先进的数据结构和算法,Smile提供了最先进的性能。Smile有很好的文档记录,请查看项目网站以获取编程指南和更多信息。
Smile涵盖了机器学习的各个方面,包括分类、回归、聚类、关联规则挖掘、特征选择、流形学习、多维缩放、遗传算法、缺失值插补、高效最近邻搜索等。
Smile实现了以下主要的机器学习算法:
- 分类:支持向量机、决策树、AdaBoost、梯度提升、随机森林、逻辑回归、神经网络、RBF网络、最大熵分类器、KNN、朴素贝叶斯、Fisher/线性/二次/正则判别分析。
- 回归:支持向量回归、高斯过程、回归树、梯度提升、随机森林、RBF网络、OLS、套索、弹性网络、岭回归。
- 特征选择:基于遗传算法的特征选择,基于集成学习的特征选择、树形图、信噪比和平方比。
- 聚类:BIRCH、CLARANS、DBSCAN、DENCLUE、确定性退火、K-均值、X-均值、G-均值、神经气体、生长神经气体、层次聚类、顺序信息瓶颈、自组织映射、光谱聚类、最小熵聚类。
- 关联规则和频繁项集挖掘:FP增长挖掘算法。
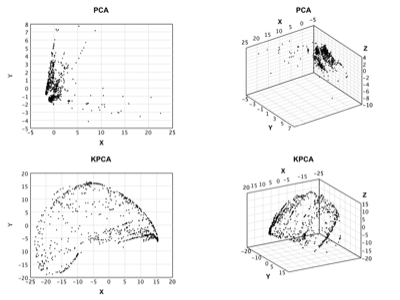
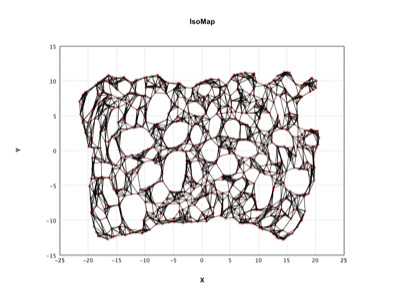
- 流形学习:IsoMap、LLE、拉普拉斯特征映射、t-SNE、UMAP、PCA、核PCA、概率PCA、GHA、随机投影、ICA。
- 多维标度:经典MDS、等渗MDS和Sammon映射。
- 最近邻搜索:BK树、覆盖树、KD树、SimHash、LSH。
- 序列学习:隐马尔可夫模型,条件随机场。
- 自然语言处理:分句器和标记器、双元统计测试、短语提取器、关键词提取器、词干分析器、词性标注、相关性排序
使用(Java等集成)
maven引入
<dependency>
<groupId>com.github.haifengl</groupId>
<artifactId>smile-core</artifactId>
<version>2.6.0</version>
</dependency>
Shell使用
模型序列化
大多数模型支持Java可序列化接口(所有分类器都支持可序列化接口),因此您可以在Spark中使用它们。
对于在非Java代码中读/写模型,我们建议使用XStream以串行化训练的模型。XStream是一个简单的库,用于将对象序列化为XML并再次序列化。XStream易于使用,不需要映射(实际上不需要修改对象)。Protostuff是一个很好的替代方案,它支持向前向后兼容性(模式演化)和验证。除了XML之外,Protostuff还支持许多其他格式,如JSON、YAML、protobuf等。
可视化
Smile提供了一个基于Swing的数据可视化库SmilePlot,它提供散点图、线图、阶梯图、条形图、方框图、直方图、3D直方图、树状图、热图、hexmap、QQ图、等高线图、曲面和线框。
需要引入库
<dependency>
<groupId>com.github.haifengl</groupId>
<artifactId>smile-plot</artifactId>
<version>2.6.0</version>
</dependency>
Smile还支持声明方式的数据可视化。使用mile.plot.vega软件包,我们可以创建一个规范,将可视化描述为从数据到图形标记(如点或条)属性的映射。
该规范基于Vega-Lite。Vega-Lite编译器自动生成可视化组件,包括轴、图例和比例。然后,它根据一组精心设计的规则确定这些组件的属性。
示例
作者:马洪彪
出处:http://www.cnblogs.com/mahongbiao/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号