YOLO
论文地址:https://arxiv.org/pdf/1506.02640.pdf
YOLO:
网络结构:
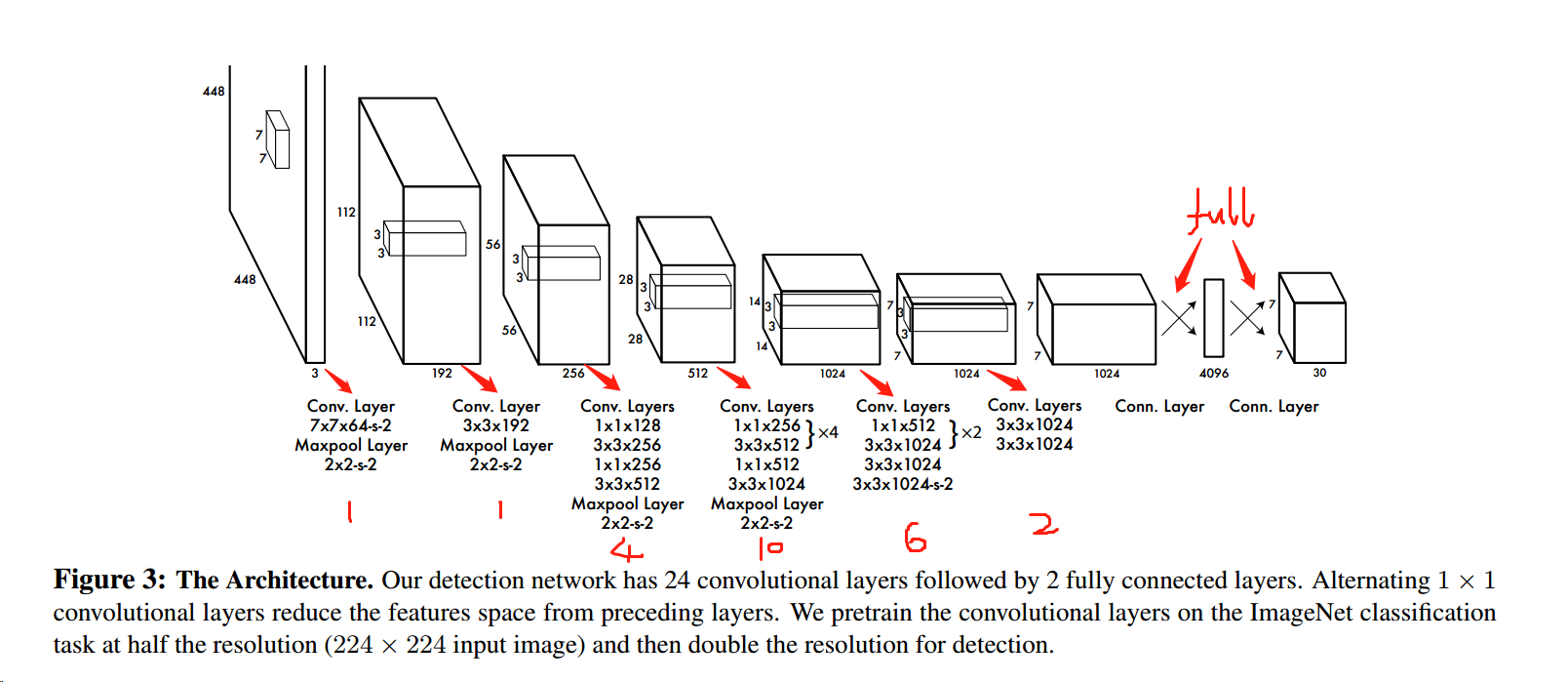
Input image size:448 * 448 * 3 ,
output tensor:7 * 7 * 30 (boxes number * (x, y, w, h, confidence) + classes ) (boxed number = 2, classes = 20), image zoom out 64 times.
通过image的w和h将预测出来的box的w,h进行归一化到0与1之间,并将x,y(center)参数化到相对于特定的cell的坐标,使其处于在0与1之间。
Train:
首先用上面的网络结构里的前20层,在加上一个pool和全连接层,在ImageNet(224 * 224) 1000-classes上面做一个top-5的accuracy到达88%的预训练,然后再用在这前20层+4个conv layers+2个full connected layers.
所有层的激活函数都使用Leaky Rectified Linear activation:

Loss Function:

因为sum-squared error 优化起来比较方便,所以使用方差误差.为了平衡正负样本数量对模型的影响,在其中加入了1和2号参数,1代表含有object的box的系数,2带便没有包含object的box的系数。默认设置位 1:5.0,2:0.5
又因为big box与small box 在求方差的时候会造成不同大小的误差(因为big box的基准大,所以产生的误差也大,所以对模型的影响也比small box造成的大,所以先求一个平方根,减小big box与small box对模型影响的差距。)
因为我们每个cell预测2个box,但是在训练的时候我们希望仅仅只有一个box负责来检测这个object,所以我们会在看看这两个box那个与gt的IOU最大,最大的负责检测。
5代表object出现在第i个cell,3代表这第i个cell的第j个box负责检测object.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号