

BoW算法及DBoW2库简介
由于在ORB-SLAM2中扩展图像识别模块,因此总结一下BoW算法,并对DBoW2库做简单介绍。
1. BoW算法
BoW算法即Bag of Words模型,是图像检索领域最常用的方法,也是基于内容的图像检索中最基础的算法。网络上有各种各样的原理分析,所以这里只是简单提一下。
Bag of Words本是用于文本检索,后被引用与图像检索,和SIFT等出色的局部特征描述符共同使用(所以有时也叫Bag of Feature,BOF),表现出比暴力匹配效率更高的图像检索效果,它是直接使用K-means对局部描述符进行聚类,获得一定数量的视觉单词,然后量化再统计词频或TF-IDF加权之后的权重系数。
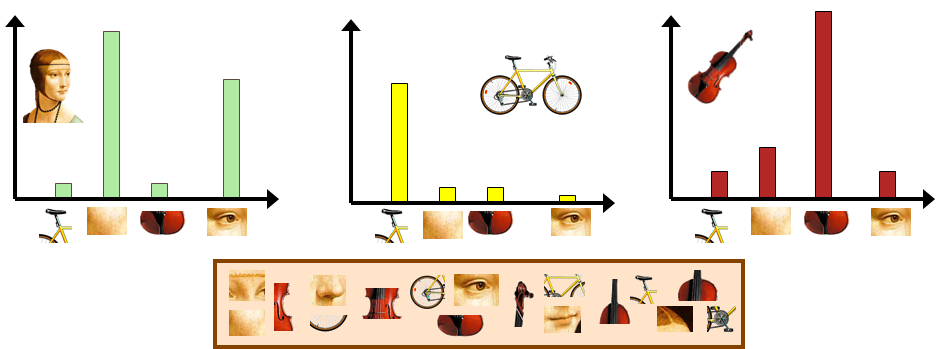
但是随着图像数据库的扩大,图像数据增加,所使用的码书规模也越来越大,K-means的效率就比较低了。为了改善大规模图像检索场景下的图像检索效果,有人提出了Vocabulary Tree(VT)算法,它是对BoW算法的一种改进算法,也就是我们现在常看见的分层量化的BoW算法。按照VT论文表述,这种算法不用进行图像表达向量的相似性计算,而是根据倒排文件系统进行打分,按照打分的高低进行排序,获得最相似的图像,至于怎么打分,这里就不多说了,从图上可以看出来。倒排文件存储就是每个叶子结点下有哪些对应的图像。
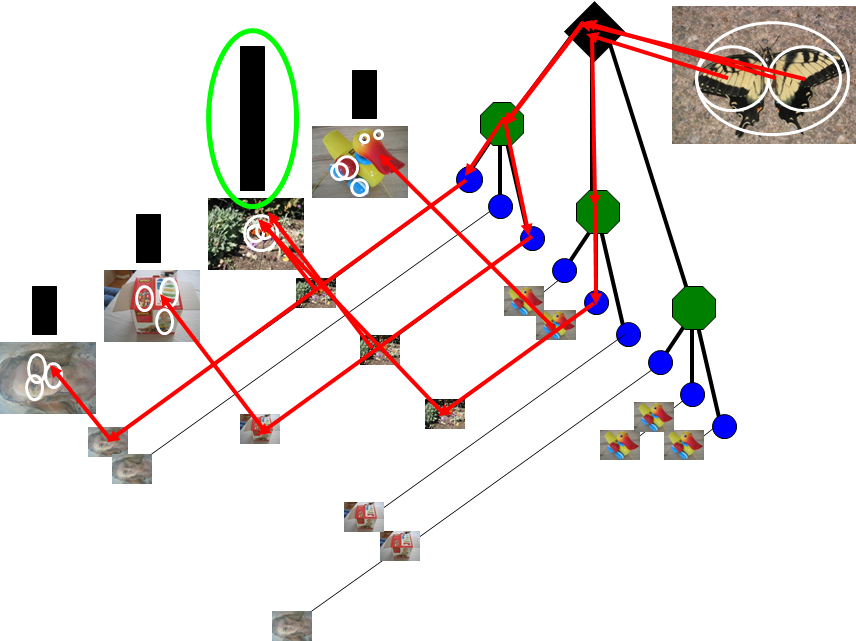
2. DBoW
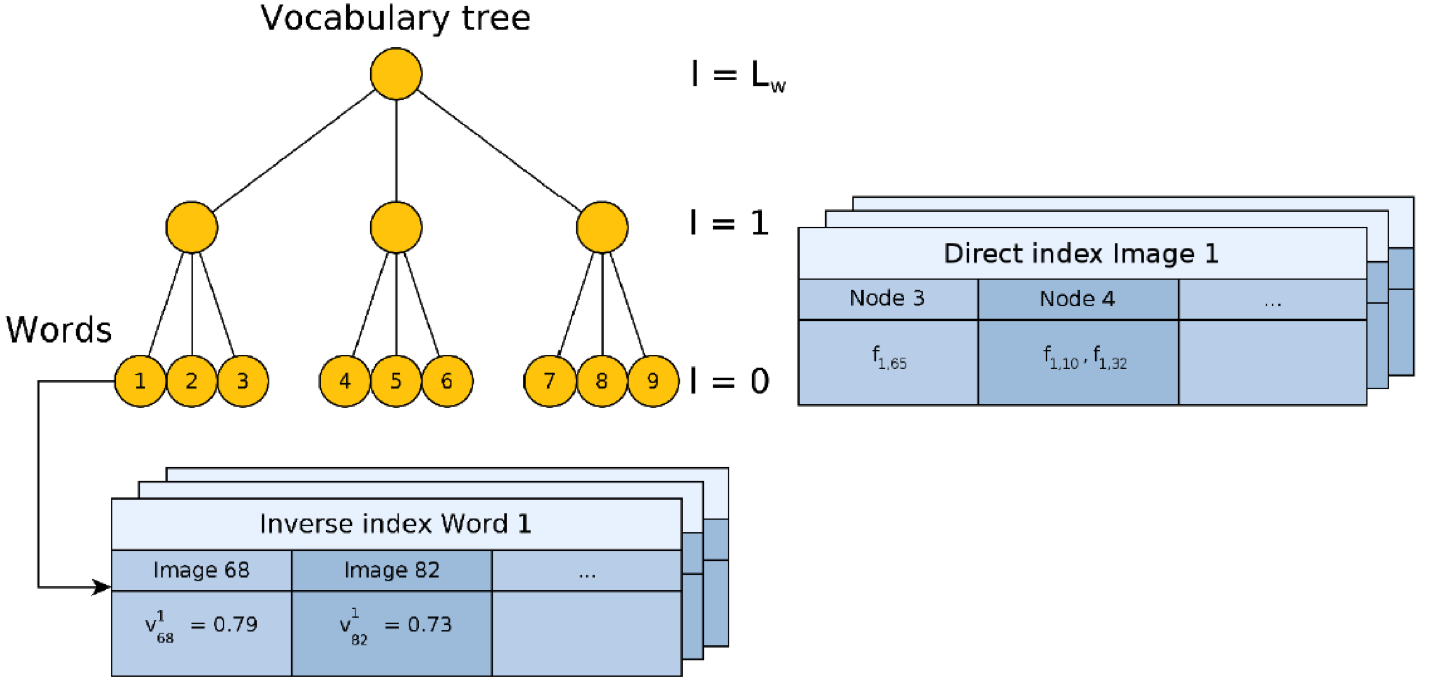
了解了上述两种算法之后再看DBoW算法就小菜一叠了,但是仍然有几个概念需要注意。DBoW2中计算图像之间相似度时仍然计算的是BoW向量之间的距离(根据描述子的不同可能选择Hamming距离或者余弦距离),而视觉单词分层的作用则引出了正向索引和反向索引的概念。
反向索引即倒排文件系统,即每个叶子结点都有一个关联的文本文档,里面存储着当前节点的索引值和落在该节点下的图像索引值。反向索引的作用和倒排文档是一致的,加速图像的匹配过程,当query图像来时,只要和对应节点下图像计算相似性即可,这就大大缩小了待匹配图像的规模。
正向索引,即中间层中每一节点下存储着该节点的索引值和对应的某一张图像的特征。正向索引可以加速特征之间的匹配,因为在图像检索的过程中,通常也是先经过BoW或者其他检索算法检索出最相似的N张图像,然后再通过特征匹配(暴力匹配)的方式确定最相似的一张或几张图像。使用正向索引时需要指定一个层数,即在与该层下的某个节点所包含的特征进行特征匹配,这同样也大大降低了特征匹配的规模,这种方法在ORB-SLAM中也用于特征匹配的加速,如跟踪时的关键帧模型等。
BoW算法或DBoW库的一个缺点就是需要离线训练一个规模较大的码书(ORB-SLAM2中这个码书达到了一百三十多兆),感觉就像一个瘤子一样(...)。
3 总结
下面会使用DBoW库训练自己的码书,并且在ORB-SLAM的基础上进行图像检索的任务,把AR部分融合进来。还有就是希望可以想想办法把这个“瘤子”去掉。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号