爬取boss直聘全国招聘数据并做可视化 - Python
正文:今天来爬一下boss直聘上关于python在全国的招聘岗位。
开发环境:
- python 3.7.9
- pycharm
用到的库:
- pandas
- csv
- selenium
- pyecharts (做可视化的时候用到)
爬虫以及保存csv文件的代码:
"""
爬取boss直评数据
"""
import pandas as pd
import csv
from selenium import webdriver
f = open('boss直聘修复数据.csv', mode='a', encoding='utf-8-sig', newline='')
csvWriter = csv.DictWriter(f, fieldnames=[
'标题',
'地区',
'薪资',
'经验',
'学历',
'公司名',
'公司领域',
'福利',
'是否上市',
'公司规模',
'详情页',
'所在城市',
'需具备技能',
])
csvWriter.writeheader() # 先在csv文档中写入头
# 初始化浏览器
browser = webdriver.Chrome() #
url = 'https://www.zhipin.com/c100010000/?query=python&page=8&ka=page-8' # 就爬一页,可以循环爬取所有页
browser.get(url) # 加载网页
browser.implicitly_wait(10) # 全局等待10秒,等到网页加载完成
def get_job_details():
lis = browser.find_elements_by_css_selector('.job-list li') # 找到招聘信息列表
for item in lis: #开始读取信息
# 标题
title = item.find_element_by_css_selector('.job-name a').get_attribute('title')
# 地区
area = item.find_element_by_css_selector('.job-area').text
# 将地区处理为城市
chengshi = area[0:2]
# 薪资
salaray = item.find_element_by_css_selector('.job-limit .red').text
# 经验 和学历
expdata = item.find_element_by_css_selector('.job-limit p').text
# 拆分expdata,将它拆分为经验和学历
jingyan = expdata[0:4] # 无论是经验不限还是1-3年都是四个字符
xueli = expdata[-2:] # 取字符串的最后两字
# 公司名
companyName = item.find_element_by_css_selector('.company-text .name a').text
# 公司类型
companyStyle = item.find_element_by_css_selector('.company-text p a').text
# 福利
descforworker = item.find_element_by_css_selector('.info-append .info-desc').text
# 是否已经上市和公司人数
ipoeddata = item.find_element_by_css_selector('.company-text p').text # 这里的字符需要处理下
# isipoed = ipoeddata[0].text
# companyWorkers = ipoeddata[1].text
# 详情页
detailPage = 'https://www.zhipin.com/' + item.find_element_by_css_selector('.job-name a').get_attribute('href')
suozaichengshi = chengshi
# 所需技能
skillsneed = item.find_element_by_css_selector('.info-append .tags').text
dit = {
'标题':title,
'地区':area,
'薪资':salaray,
'经验':jingyan, #可能需要拆分
'学历':xueli,
'公司名':companyName,
'公司领域':companyStyle,
'福利':descforworker,
'是否上市':ipoeddata, # 未处理数据
'公司规模':ipoeddata, # 未处理数据
'详情页':detailPage,
'所在城市':area[0:2],
'需具备技能':skillsneed,
}
print(dit) # 打印是否符合预期
get_job_details() # 运行下看是否符合预期
browser.close() # 关闭浏览器
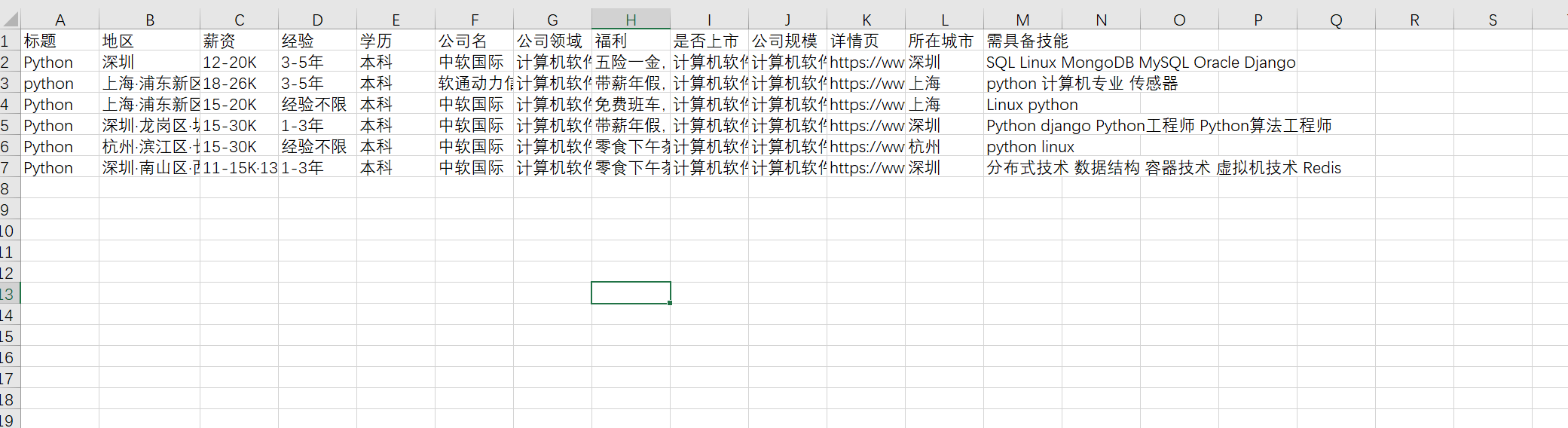
保存后的数据如下:
可视化用pyecharts做,方向主要有:
- 每个城市招聘该职位数量的柱状图
- 求取下平均工资最高的城市
- 经验学历饼图
- 上市公司占比饼图
- 公司规模(人数)占比图
- 公司行业分布图
- 需要的技能饼图

 浙公网安备 33010602011771号
浙公网安备 33010602011771号