
游戏行业如何实现运维自动化与故障自愈(转)
注:本文主要讲解游戏行业运维体系构建的几点设想
游戏运维体系
公司创业到后期的上市经历的四个阶段
标准化-->自动化-->平台化-->服务化
第一阶段:标准化
标准化的意思是把主机名、内网以及配置文件统一起来,如果不统一,后面的东西就无法继续。没有一个标准化的环境,脚本是无法写下去的。
第二阶段:自动化
中小型企业阶段都是自动化到平台化的过渡,平台化就是把自动化的东西分装,把功能整合,把数据做聚合,然后放在平台上来可视化。
第三阶段:平台化
以后的趋势是脚本和功能必须是外部化的,这样新来的一个人才能接手。不用在服务器上跑脚本,还要同下个人交代在哪儿装。
第四阶段:服务化
服务化是指现在云平台所承载的东西。举个例子,搭一个redis集群,用户不需要知道服务器有多少个,因为所提供的NOSQL服务打开后,用户就可以直接使用了。
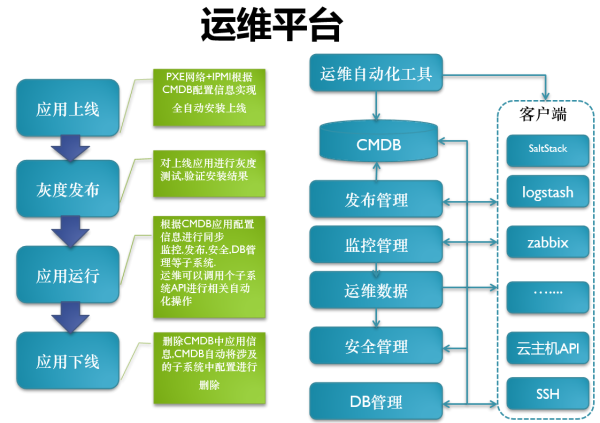
自动化工具

CMDB

完善的发布流程
监控

运维数据
安全管理:
1)游戏跑在普通用户下
2)可以给研发授予服务器权限,服务器使用key登录,做好命令执行监控
3)域名使用
4)端口管理(只开必要的游戏端口)
DB:
1)备份还原策略(全备,增备)
2)批量更新表结构,查询数据,添加用户
3)
客户端基础环境:
批量管理:SaltStack做aget,Ansible无需客户端
日志收集:logstash
监控报警:zabbix,openfalt,
监控添加:根据cmdb自动添加监控,删除监控
监控模板:
系统基础监控模板(内存,CPU,硬盘,inode,端口,系统日志)
游戏业务监控模板(游戏端口,进程,日志输出,游戏在线人数,)
应用上线:
研发测试环境->外网测试环境->准正式服环境(版本高低数据兼容问题)->正式服环境
整个过程自动化重度依赖CMDB,CMDB是运维里开始最麻烦的,其实最主要是理清关系,然后信息关联。在这里简单地分了几类,比如域名库、软件库、资源库、IP库、配置库,这些建立起来 的话,CMDB必须是可维护性的,建立这些模型之初一定要想到它的可维护性,没有可维护性后面的数据会很乱从而自动化就不用谈了。DB管理、安全管理、监 控管理。DB管理分为DB部署、DB监控,里面是关于数据的操作,权限的一些划分。安全管理就是安全规则管理。
运维数据的智能分析
这里运维数据包括:监控、系统日志,业务运行日志
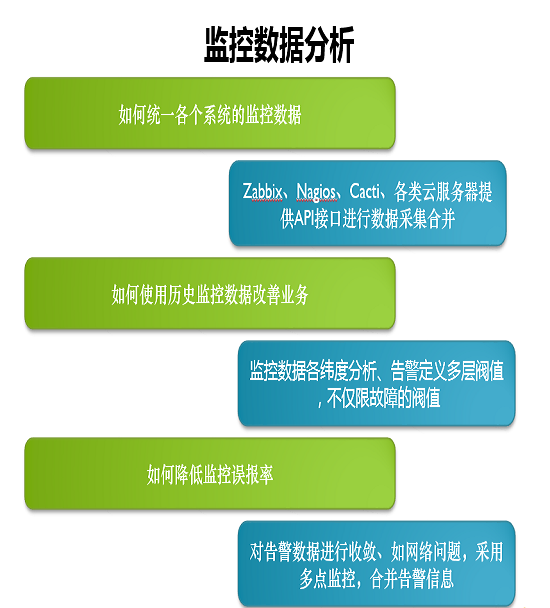

监控数据:
zabbix:通过zabbix的API获取监控数据
cacti+nagios:通过分析配置文件
云平台:云平台API接口
监控的痛点及改善方向
1)监控数据多维度对比分析
2)告警级别分级,多层阈值
3)降低误报率
4)告警方式的多样化(邮件,短信,微信,QQ)
5)监控的批量添加及删除(自动化方向:依靠CMDB应用信息实现监控的自动化)
web日志的应用:

场景就是安全人员需要运维定期的推送一些异常日志,进行XSS注入分析。游戏行业遇到最多的就是被撞库了,每天都在不停的刷账号,刷密码。这个事不光是在游戏行业,在其他行业也会遇到。
制订了一个目标,运维负责相关业务日志统一汇总,需要有标准的API查询接口。现在所有跟跨部门合作,或者同其他人合作都是通过API。安全人员可 以自己定义Web过滤规则,写正则,对异常日志做分析,然后确定攻击类型,采取相应的措施。各平台有日志的实时汇总,如果是集群的话,则服务器是分片的, 只是每一台去统计防护失常,或者PV、UV的东西,很难全局性地去判断。因为经典的架构就是前面ALVS,把它分散到下面的服务器,数据需要先合并,也需 要聚合,肯定要花费很大、很长的时间。
拿到数据可以根据用户的地区,优化服务器区服的配置和用户体验。游戏的区域性是很强的,可以根据IP进行精准定位。
可以选用互联网比较经典的架构ELK。logstash收集日志,队列用redis,放到redis里面,然后logstash再取,放给 ElasticSearch,最后去存储。建立初期可以直接用图形化,用Kibana做图形化视图的分析。中间的redis只是充当一个队列,但是架构是不变的,所以上手是非常之快的。如果有开发运维的话,直接可以从Lsearch里面把日志分析出来。web端用自己的过滤规则。如果有问题就扔到黑名单里面,业务在前端做逻辑控制。
故障自愈
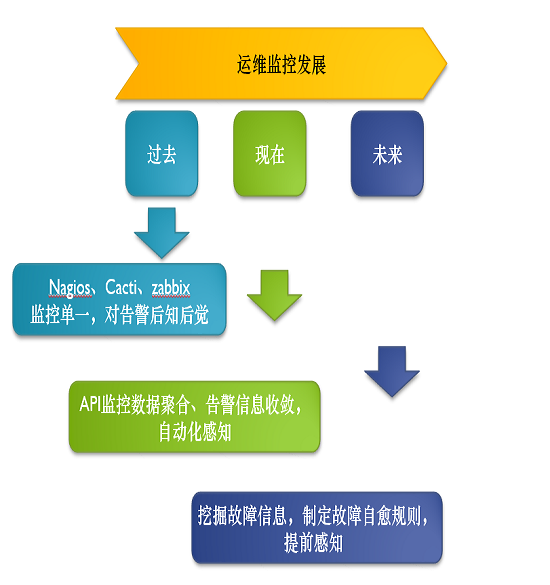




现在大部分中型的企业都有自己的API,监控数据的聚合,告警数据的收敛,很多做自动化。这些做起来并不是很难,关键是在做未来的时候,去挖掘故障信息,去制定自己的故障自愈规则。
其所面临的问题就是系统网络,业务层面自生的逻辑造成的一些异常,监控误报还有监控自身的一些可靠性。还有非自愈业务,因为故障自愈不是万能的,就 像现在的人工智能一样,有些东西是机器代替不了的。比如说复杂的业务场景,可能机器是没办法判断的,可能有些东西是需要人工看,才能知道应该怎么处理。
应用案例:
用自己的Zabbix监控或者somkeping监控甚至第三方监控,获取监控信息。然后把所有的监控信息全部推送,推送到回调队列里面去,然后去分析这个告警信息。

故障自愈能带来什么呢?非工作时间可以处理自己私人的事情,运维第一个要求就是24小时要待命。减少直接对线上的操作,比如出现了故障,直接去操作线上, 很有可能会出现二次故障。所以必须要从故障原因里面分析,锻炼运维人员对工作的积极性,并不是每天都是鼓噪的东西。长远看来,对玩家,对公司利益,以及自 身价值都将有显著的提升。

有很多开源方案是不能直接用的,必须要用到自己的生产环境当中,有自己的一些解决方案。运维工具的设计要很简单,因为要考虑下一个接手你的东西的时候,维 护成本有多高。敲过代码的人都知道,重写会比维护代码好很多。所有的东西都要以业务为核心,一旦脱离了业务,你做的数据其实并没有什么用。最后要说的是, 好的架构是演化来的,不是设计出来的。
总结:一定要在自己的领域有独特的解决方案。
原文地址:http://mobile.51cto.com/hot-511389.htm
视频地址:http://edu.51cto.com/lesson/id-100749.html
出处:http://www.cnblogs.com/madsnotes/
声明:本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接。
 浙公网安备 33010602011771号
浙公网安备 33010602011771号