

集合
##集合Collection:
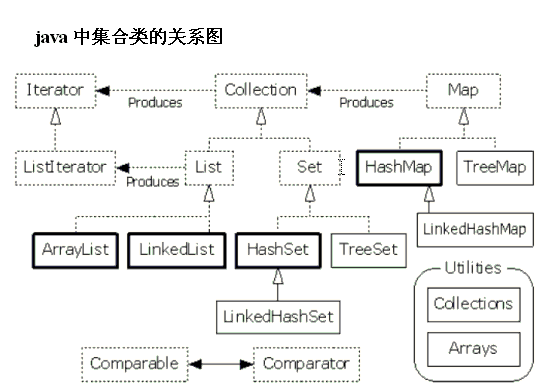
(1):List:有序(元素存入集合的顺序和取出的顺序一致)元素都有索引,元素可以重复,
(2):Set:无序(存入和取出顺序可能不 一致)不可以存储重复元素,必须保证元素唯一性,
1:添加:
A:add:(odject)添加一个元素,
B:addAll(Collection):添加一个集合中的所有元素,
2:删除:
A:clear():将集合中的元素全删除,清空集合,
B:remove():删除集合中指定的对象,注意:删除成功,集合的长度会改变,
removeAll(collection):删除部分元素,部分元素和转入Collection一致,
3:判断:
A:boolean contains(oaj):集合中是否包含指定元素,
B:boolean containsAll(Collection):集合中是否包含指定的多个元素,
C:boolean isEmpty():集合中是否有元素,
4:获取:
A:int size():集合中有几个元素,
B:Object get(index):通过索引获取指定元素,
C:int indexOf(odj):获取指定元素第一出现的索引位,如果该元素不存在返回-1,所以通过-1,可以判断一个元素是否存在,
D:int lastIndexOf(Odject o):返回索引指定元素的位置,
E:List subList(start,end):获取子列表,
5:取交集:
A:boolean retainAll(Collection):对当前集合中保留和指定集合中的相同的元素,如果两个集合元素相同,返回flase;如果retainAll修改了当前集合,返回true,
6:获取集合中所有元素:
A:Iterator iterator():迭代器,
7:将集合变成数组:
A: toArray();
8:修改:
A:Object set(index,element):对指定索引位进行元素的修改,
集合的概念:
(1):java中的集合:是一种工具,就像容器,存储任意数量的具有共同的属性的对象,
(2):A集合的作用:在类的内部,对数据进行组织,
B简单而快速的搜索大数据的条目,
C有的集合接口。提供了一系列有有序的元素,并且可以在序列中快速的插入或删除有关元素,
D有的集合接口,提供了映射关系,可以通过关键字--(key)--去快速的查找对应的唯一对象,而这个关键字可以是任意类型,
(3):数组只能通过下标访问元素,类型固定,而又的集合可以通过任意类型查找所映射的具体对象,
Iterator迭代器遍历:
hasNext:判断集合中是否有下一个元素,
next:直接取出该集合中的元素,
List:
有序(元素存入集合的顺序和取出的顺序一致),元素都有索引,元素可以重复,
A:ArrayList----底层的数据结构师数组,线程不同步,ArrayList替代了Vector,查询元素的速度非常快;
B:LinkedList---底层的数据结构是链表,线程不同步, 增删元素的速度非常快,
C:Vector--- 底层的数据结构就是数组,线程同步的,Vector无论查询和增删都慢,
注意:对于list集合,底层判断是否相同,其实用的是元素自身的equals方法完成的,建议元素都要复写equals方法,元素对自己的比较相同的条件依据,
Set接口:
Set接口中的方法和Collection中的方法一致的,Set接口取出方式只有一种,迭代器,
A:HashSet:1:底层数据结构是哈希表,线程是不同的,(无序,高效),
HashSet集合保证元素唯一性:通过元素的hashCode方法,和equals方法完成的,
B:LinkedHashSet:有序,hashset的子类,
C:TreeSet:对Set集合中的元素的进行指定顺序,不同步,TreeSet底层的数据结构就是二叉树,
D:对于ArrayList集合,判断元素是否存在,或者删元素底层依据都是equals方法,
E:对于HashSet集合,判断元素是否存在,或者删除元素,底层依据的是hashCode方法和equals方法,
TreeSet:
1:如果元素不具备比较性,在运行时会发生异常,所以需要元素**实现Comparable**强行让元素具备比较性,**复写comparaTo方法**,
2:TreeSet方法保证元素唯一性的方式:就是参考比较方法的结果是否为0,如果return 0,视为两个对象重复,就不存,
注意:在进行比较时,如果判断元素不唯一,比如,同名,同年龄,才视为一个人,
在判断时,需要分主要条件和次要条件,当主要条件相同时,在判断次要条件,按照次要条件排序,
TreeSet集合排序有两种方式,Comparable和Comparator区别:
1:让元素自身具备比较性,需要元素对象实现Comparable接口,覆盖comparaTo方法,
2:让集合自身具备比较性,需要定义一个实现了Comparator接口的比较器,并覆盖compara方法,并将该对象作为实际参照数传递给TreeSet集合的构造函数,
Map集合:
1:Hashtable:底层是哈希表数据结构,是线程同步的,不可以存储null键,null值,
2:HashMap:底层是哈希表数据结构,是线程不同步的,可以存储null键,null值,替代了Hashtable,
3:TreeMap:底层是二叉树结构,可以对map集合中的键进行指定顺序的排序,
Map和Collection的区别:
1;Map集合存储和Collection有着很大不同,
2:Collection是一次存一个元素,Map是一次存一个元素,
3:Collection是单列集合, Map是双列集合,
4:Map中的存储的一对元素:是一个键,一个值,键与值之间有对应(映射)关系,
1:添加:
A:put(key,value):当存储的键相同时,新的值会替换老的值,并将老值返回,如果键没有重复,返回null,
B: putAll(Map);
2:删除:
A: clear():清空
B:remove(key):删除指定的键,
3:判断:
A:boolean isEmpty():是否有元素,
B:boolean containsKey(key):是否包含key
C:boolean containsValue(Value):是否包含value
4:取出:
A:int size():返回长度
B:value get(key):通过指定键获取对应的值,如果返回null,可以判断该键不存在,当然有特殊情况,就是在hashmap集合中,是可以存储null键null值的,
C: Collection values():获取ma'p集合中的所有的值,
5:想要获取map中的所有元素的值:
A:原理:map中是没有迭代器的,collection具备迭代器,只要将map集合转成Set集合,可以使用迭代器了,之所以转成Set,是因为map集合具备着键的唯一性,其实Set集合就来自于Map,Set集合底层其实用的就是Map的方法,
把Map集合转成Set的方法:
Set keySet();
Set entrySet; 取的是键和值的映射关系,
Entry就是Map接口的内部类接口;
取出Map集合中所有的元素的方式一:keySet方法:**
可以将Map集合中的键都取出存放到Set集合中,对Set集合进行迭代,迭代完成,在通过get方法对获取的键进行值的获取,
Set keySet=map.KeySet();
Iterator it=keySet.iterator();
whlie(it.hasNext()){
Object key=it.next();
Object value=map.get(key);
System.out.println(key+" "+value);
}
取出Map集合中所有元素的方式二:entrySet()方法,
Set entrySet =map.entrySet();
Iterator it=entrySet.iterator();
whlie(it.hasNext()){``
Map.Entry me =(Map.Entry)it.next();
System.out.println(me.getKey+""+me.getValue);
}
使用集合的技巧:
看到Array就是数组结构,有角标致,查询速度很快,
看到link就是链表结构:增删速度快,而且有特有的方法,addFirst; addLast; removeFirst(); removeLast(); getFirst(); getLast();
看到hash就是哈希表,就是想要到唯一性,就要像到存入到该结构中的元素必须覆盖hashCode,equals方法,
看到tree就是二叉树,就要想到排序,就想要用到比较,
比较的两种方式:
1:一个是Comparable:覆盖:comparaTo方法,
2:一个是Comparator :覆盖comparable方法,
LinkedHashSet,LinkedHashMap:这两个集合可以保证哈希表有序存入顺序和取出顺序一致,保证哈希表有序,
但存储的是一个元素时,就用Collection,当存储对象之间在着映射时,就使用Map集合,
保证唯一,就用Set,不保证唯一就用List,

 浙公网安备 33010602011771号
浙公网安备 33010602011771号