
实验五:全连接神经网络手写数字识别实验
【实验目的】
理解神经网络原理,掌握神经网络前向推理和后向传播方法;
掌握使用pytorch框架训练和推理全连接神经网络模型的编程实现方法。
【实验内容】
1.使用pytorch框架,设计一个全连接神经网络,实现Mnist手写数字字符集的训练与识别。
【实验报告要求】
修改神经网络结构,改变层数观察层数对训练和检测时间,准确度等参数的影响;
修改神经网络的学习率,观察对训练和检测效果的影响;
修改神经网络结构,增强或减少神经元的数量,观察对训练的检测效果的影响。
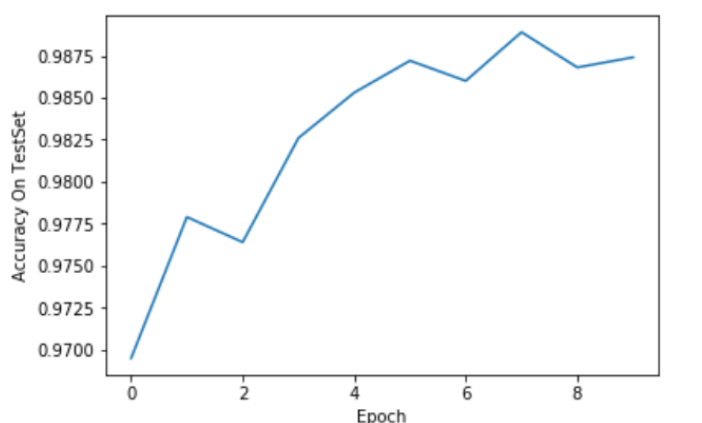
import torch import numpy as np from matplotlib import pyplot as plt from torch.utils.data import DataLoader from torchvision import transforms from torchvision import datasets import torch.nn.functional as F batch_size = 64 learning_rate = 0.01 momentum = 0.5 EPOCH = 10 transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))]) train_dataset = datasets.MNIST(root='./data/mnist', train=True, transform=transform) test_dataset = datasets.MNIST(root='./data/mnist', train=False, transform=transform) train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True) test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False) class Net(torch.nn.Module): def __init__(self): super(Net, self).__init__() self.conv1 = torch.nn.Sequential( torch.nn.Conv2d(1, 10, kernel_size=5), torch.nn.ReLU(), torch.nn.MaxPool2d(kernel_size=2), ) self.conv2 = torch.nn.Sequential( torch.nn.Conv2d(10, 20, kernel_size=5), torch.nn.ReLU(), torch.nn.MaxPool2d(kernel_size=2), ) self.fc = torch.nn.Sequential( torch.nn.Linear(320, 50), torch.nn.Linear(50, 10), ) def forward(self, x): batch_size = x.size(0) x = self.conv1(x) x = self.conv2(x) x = x.view(batch_size, -1) x = self.fc(x) return x model = Net() criterion = torch.nn.CrossEntropyLoss() optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate, momentum=momentum) def train(epoch): running_loss = 0.0 running_total = 0 running_correct = 0 for batch_idx, data in enumerate(train_loader, 0): inputs, target = data optimizer.zero_grad() outputs = model(inputs) loss = criterion(outputs, target) loss.backward() optimizer.step() running_loss += loss.item() _, predicted = torch.max(outputs.data, dim=1) running_total += inputs.shape[0] running_correct += (predicted == target).sum().item() if batch_idx % 300 == 299: print('[%d, %5d]: loss: %.3f , acc: %.2f %%' % (epoch + 1, batch_idx + 1, running_loss / 300, 100 * running_correct / running_total)) running_loss = 0.0 running_total = 0 running_correct = 0 def test(): correct = 0 total = 0 with torch.no_grad(): for data in test_loader: images, labels = data outputs = model(images) _, predicted = torch.max(outputs.data, dim=1) total += labels.size(0) correct += (predicted == labels).sum().item() acc = correct / total print('[%d / %d]: Accuracy on test set: %.1f %% ' % (epoch+1, EPOCH, 100 * acc)) return acc if __name__ == '__main__': acc_list_test = [] for epoch in range(EPOCH): train(epoch) acc_test = test() acc_list_test.append(acc_test)



y_test=acc_list_test plt.plot(y_test) plt.xlabel("Epoch") plt.ylabel("Accuracy On TestSet") plt.show()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号