

工程实践系统设计方案
一、 项目简介
本项目是职位搜索引擎的设计与实现,实现从职位数据采集,到数据整理、存储,到提供给用户搜索服务的一套完整流程,并通过数据挖掘、nlp等优化用户的搜索结果,构造更美观和更具有交互性的前端页面来增强用户体验。之前已经完成了项目的需求分析与概念原型设计,接下来将给出系统的详细设计方案。
二、 系统概念原型
1. 分解视图
功能模块划分如下图所示:
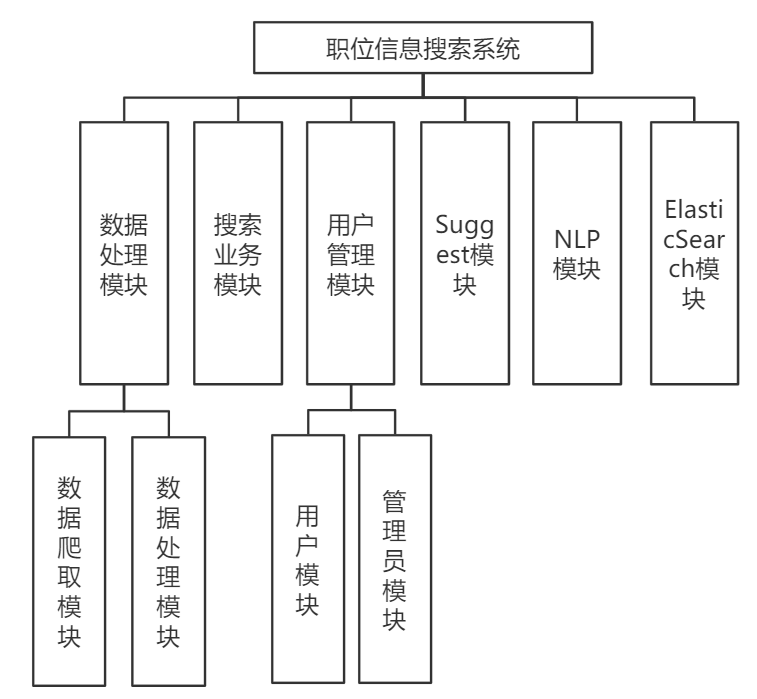
2. 依赖视图
本项目采用传统MVC架构:
- Model(模型)代表一个存取数据的对象及其数据模型
- View(视图)代表模型包含的数据的表达方式,一般表达为可视化的界面接口
- Controller(控制器)作用于模型和视图上,控制数据流向模型对象,并在数据变化时更新视图。控制器可以使视图与模型分离开解耦合
本项目的体系结构如下图所示:
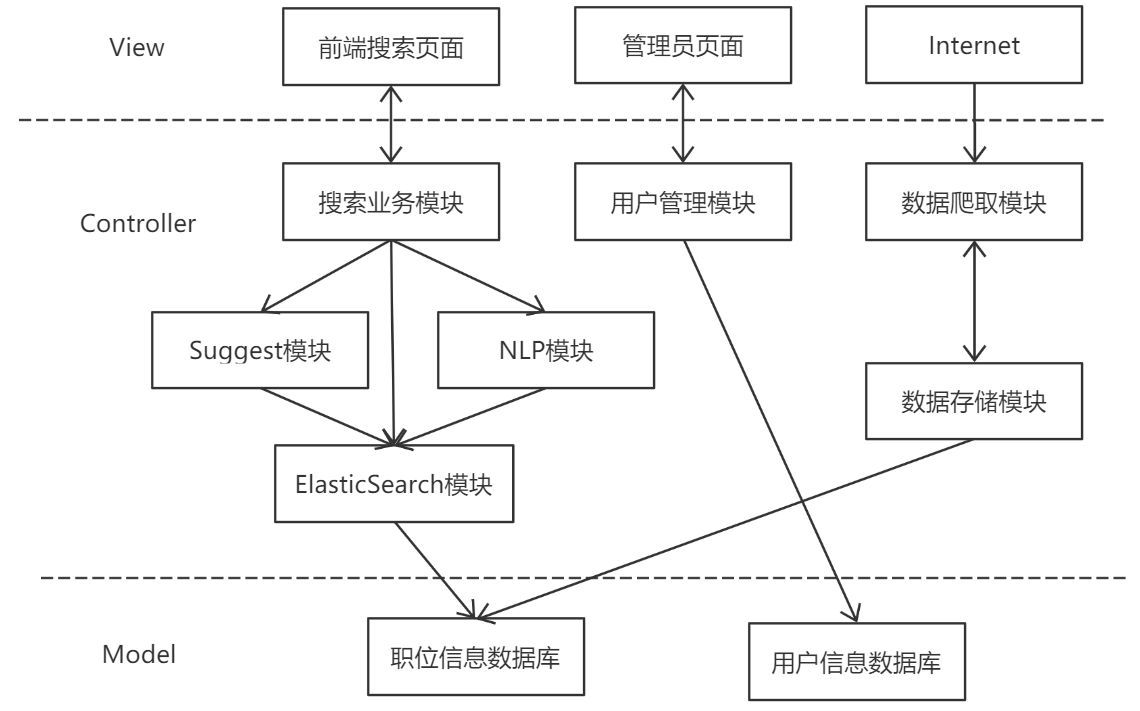
View层与用户直接交互,包括查询搜索以及显示结果,同时,View层依赖Controller提供的数据。
Controller层包含核心搜索功能,完成数据采集、存储以及数据维护,其中,搜索业务模块要使用Suggest模块和NLP模块提供的功能,搜索业务模块也依赖于ElasticSearch模块提供的数据,数据存储模块依赖于数据爬去模块提供的数据。
Model层负责维护数据对象信息。
每层相互独立,通过接口进行数据传递,这样可以使系统耦合性降低,利于系统的维护和扩展。
3. 系统架构
根据对系统需求的分析,将系统功能划分为前端和后端两个部分,后端运行在Tomcat服务器上,为前端的数据检索和其他服务提供数据支持,前端采用B/S模式,用户通过浏览器访问数据,主要架构如下图所示:
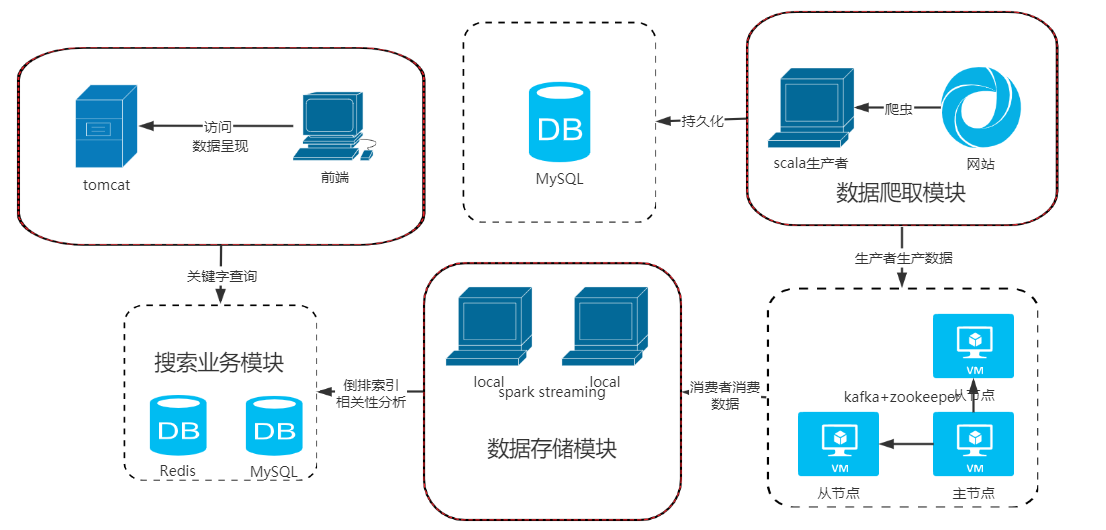
本项目服务端的执行流程为:
- 通过爬虫定期抓取所有招聘网站的最新招聘信息,进行处理后持久化到本地数据库;
- 在持久化到本地的同时,发送数据到kafka集群,这里kafka集群作为异步消息队列来使用
- sparkStreaming拉取数据进行处理后存入Redis集群
- 最后,搜索业务模块负责对用户提交的查询进行分析,检索数据库找到匹配的网页返回检索结果,通过排序策略对所有相关的结果进行排序展示给用户。
4. 执行视图
这里以用户搜索的交互情况为例
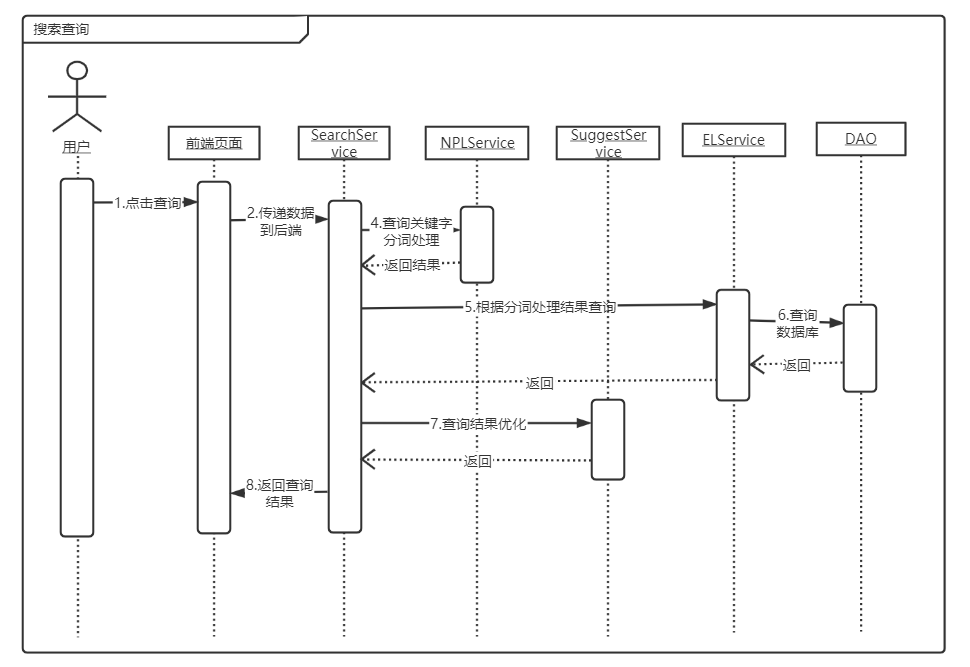
三、 数据库设计
数据库采用的是mysql
本系统主要包括用户信息表、职位信息表、管理员屏蔽字表,职位名称表
1. 用户表
| 字段 | 类型 | 说明 |
|---|---|---|
| uid | int | 自增的用户id,主键 |
| username | char | 用户名 |
| passward | char | 密码 |
| isAdmin | boolean | 是否为管理员 |
| regTime | datetime | 注册时间 |
2. 职位信息表
| 字段 | 类型 | 说明 |
|---|---|---|
| uid | int | 自增的职位id,主键 |
| URL | char | 网页URL |
| name | char | 职位名称 |
| type | char | 工作类型 |
| location | char | 工作地点 |
| degreeRequest | char | 学历要求 |
| salaryLow | int | 薪资下限 |
| salaryHigh | int | 薪资上限 |
| hireNumber | int | 招聘人数 |
| createTime | datetime | 创建时间 |
| expireTime | datetime | 截止时间 |
3. 屏蔽字表
| 字段 | 类型 | 说明 |
|---|---|---|
| uid | int | 自增的id,主键 |
| key | char | 屏蔽的关键字 |
| createTime | datetime | 创建时间 |
| vaild | boolean | 是否有效 |
4. 职位名称表
| 字段 | 类型 | 说明 |
|---|---|---|
| uid | int | 自增的id,主键 |
| jobID | char | 职位编号 |
| name | char | 职位名称 |
四、 实现视图
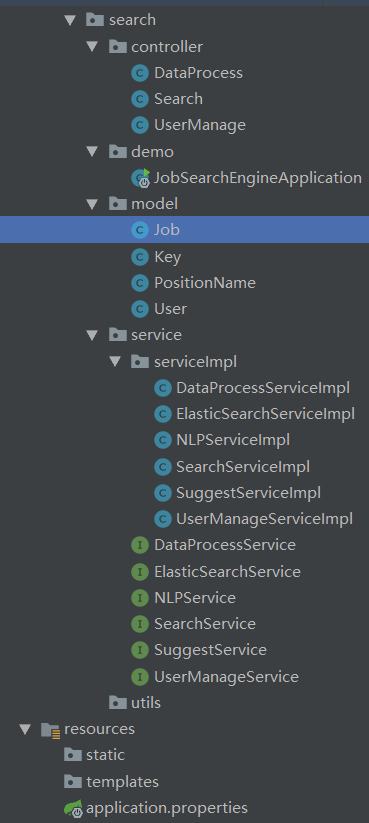
本项目实现视图如下所示:
五、 软件系统运行环境
- 操作系统:win10
- 开发工具:Pycharm+IDEA
- 开发框架:SpringBoot+vue
- 项目管理工具:Maven
- 编程语言:python+java
- 部署:阿里云服务器
六、 技术选型
在做本项目的技术选型时,主要基于以下几个方面去考虑:
- 实现当前的需求,主要用到哪种技术;
- 该技术的成熟度如何,是否被广泛使用;
- 该技术目前由谁支持,是否持续更新或者权威性如何;
- 该技术的优势和劣势,以及存在的风险;
- 技术的复杂性如何,当前团队对该技术的熟悉程度和可能需要的时间;
例如前端框架技术的选择,当前三大主流前端框架:
- Angular.js:出来最早的前端框架,学习曲线比较陡,NG1学起来比较麻烦,NG2开始,进行了一系列的改革,也开始启用组件化了;在NG中,也支持使用TS(TypeScript)进行编程;
- Vue.js:最火的一门前端框架,它是中国人开发的,对我们来说,文档要友好一些;
- React.js:最流行的一门框架,因为它的设计很优秀;
在对比了他们的优缺点以及与本项目的契合程度(主要是考虑的是组内成员学习成本),我们采用了Vue.js
七、 系统概念原型的核心工作机制
- 概念是人对能代表某种事物或发展过程的特点及意义所形成的思维结论
- 概念原型是一种虚拟的、理想化的软件产品形式。
- 概念原型 = 用例 + 数据模型
本项目的概念原型:涉及到的用例较为简单,角色包括管理员和用户两个部分
工作过程:
- 管理员登录系统,可以查看该搜索系统的所有屏蔽词列表,通过点击某个屏蔽词,可对其进行删除、修改,或是点击新增一个屏蔽词
- 用户可以不登录直接使用,通过在搜索框输入关键字进行查询,系统向用户反馈搜索结果,用户也可以选择注册登录,登陆后,每次查询都会记录,用户可以查看历史搜索记录

 浙公网安备 33010602011771号
浙公网安备 33010602011771号