


映 射
基本映射操作
Java类库为映射提供了两个通用的实现:HashMap和TreeMap。这两个类都实现了 Map接口。
散列映射对键进行散列, 树映射用键的整体顺序对元素进行排序, 并将其组织成搜索 树。散列或比较函数只能作用于键。与键关联的值不能进行散列或比较。
应该选择散列映射还是树映射呢? 与集一样, 散列稍微快一些, 如果不需要按照排列顺 序访问键, 就最好选择散列。
下列代码将为存储的员工信息建立一个散列映射:
Map<String, Employee> staff = new HashMap<>( );// HashMap implements Map Employee harry = new Employee("Harry Hacker"); staff.put("987-98-9996", harry); ...
每当往映射中添加对象时, 必须同时提供一个键。在这里,键是一个字符串,对应的值 是 Employee 对象。 要想检索一个对象, 必须使用(因而,必须记住)一个键。
String id = "987-98-9996"; e = staff,get(id);// gets harry
如果在映射中没有与给定键对应的信息,get 将返回 null。
键必须是唯一的。不能对同一个键存放两个值。如果对同一个键两次调用 put方法, 第二个值就会取代第一个值。实际上,put 将返回用这个键参数存储的上一个值。
remove 方法用于从映射中删除给定键对应的元素。size 方法用于返回映射中的元素数。 要迭代处理映射的键和值, 最容易的方法是使用 forEach 方法。可以提供一个接收键和 值的 lambda 表达式。映射中的每一项会依序调用这个表达式。
scores.forEach((k, v) -> System.out.println("key=" + k + ", value: " + v));
程序清单 9-6 显示了映射的操作过程。首先将键 / 值对添加到映射中。然后,从映射中 删除一个键, 同时与之对应的值也被删除了。接下来, 修改与某一个键对应的值, 并调用 get 方法查看这个值。最后, 迭代处理条目集。
//程序清单9-6 map/MapTest.java package map; import java.util.*; /** * This program demonstrates the use of a map with key type String and value type Employee. * @version 1.11 2012-01-26 * @author Cay Horstmann */ public class MapTest { public static void main(String[] args) { Map<String, Employee> staff = new HashMap<>(); staff.put("144-25-5464", new Employee("Amy Lee")); staff.put("567-24-2546", new Employee("Harry Hacker")); staff.put("157-62-7935", new Employee("Gary Cooper")); staff.put("456-62-5527", new Employee("Francesca Cruz")); // print all entries System.out.println(staff); // remove an entry staff.remove("567-24-2546"); // replace an entry staff.put("456-62-5527", new Employee("Francesca Miller")); // look up a value System.out.println(staff.get("157-62-7935")); // iterate through all entries for (Map.Entry<String, Employee> entry : staff.entrySet()) { String key = entry.getKey(); Employee value = entry.getValue(); System.out.println("key=" + key + ", value=" + value); } } }
更新映射项
处理映射时的一个难点就是更新映射项。正常情况下,可以得到与一个键关联的原值, 完成更新, 再放回更新后的值。不过,必须考虑一个特殊情况, 即键第一次出现。下面来看 一个例子,使用一个映射统计一个单词在文件中出现的频度。看到一个单词(word) 时,我 们将计数器增 1,如下所示:
counts.put(word, counts.get(word)+ 1) ;
这是可以的, 不过有一种情况除外:就是第一次看到 word时。在这种情况下,get 会返 回 null, 因此会出现一个 NullPointerException 异常。
作为一个简单的补救, 可以使用 getOrDefault方法:
counts.put(word, counts.getOrDefault(word, 0)+ 1) ;
另一种方法是首先调用 putlfAbsent 方法。只有当键原先存在时才会放入一个值。
counts.putlfAbsent(word, 0) ;
counts.put(word, counts.get(word)+ 1) ;// Now we know that get will succeed
不过还可以做得更好。merge方法可以简化这个常见的操作。如果键原先不存在,下面 的调用:
counts.merge(word, 1, Integer::sum) ;
将把 word 与 1 关联,否则使用 Integer::sum 函数组合原值和 1 (也就是将原值与 1 求和)。
映射视图
集合框架不认为映射本身是一个集合。(其他数据结构框架认为映射是一个键 / 值对 集合, 或者是由键索引的值集合。 )不过, 可以得到映射的视图(View)— —这是实现了 Collection 接口或某个子接口的对象。
有 3 种视图: 键集、 值集合(不是一个集)以及键 / 值对集。键和键 / 值对可以构成一个 集, 因为映射中一个键只能有一个副本。下面的方法:
Set<K> keySet() Collection<V> values() Set<Map.Entry<K, V>> entrySet()
会分别返回这 3 个视图。(条目集的元素是实现 Map.Entry 接口的类的对象。 )
需要说明的是,keySet 不是 HashSet 或 TreeSet, 而是实现了 Set 接口的另外某个类的对 象。Set 接口扩展了 Collection接口。因此, 可以像使用集合一样使用keySet。
弱散列映射
WeakHashMap 使用弱引用(weak references) 保存键。 WeakReference 对象将引用保存到另外一个对象中,在这里,就是散列键。对于这种类型的 对象,垃圾回收器用一种特有的方式进行处理。通常,如果垃圾回收器发现某个特定的对象 已经没有他人引用了,就将其回收。然而, 如果某个对象只能由 WeakReference 引用, 垃圾 回收器仍然回收它,但要将引用这个对象的弱引用放人队列中。WeakHashMap将周期性地检 查队列, 以便找出新添加的弱引用。一个弱引用进人队列意味着这个键不再被他人使用, 并 且已经被收集起来。于是, WeakHashMap将删除对应的条目。
链接散列集与映射
LinkedHashSet 和 LinkedHashMap类用来记住插人元素项的顺序。这样就可以避免在散歹IJ表 中的项从表面上看是随机排列的。当条目插入到表中时,就会并人到双向链表中(见图 9-11 )。
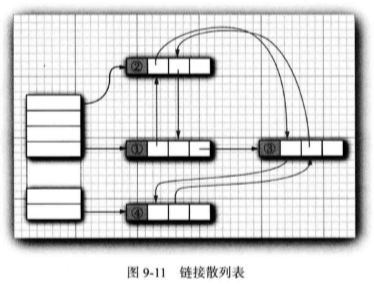
链接散列映射将用访问顺序, 而不是插入顺序, 对映射条目进行迭代。每次调用 get 或 put, 受到影响的条目将从当前的位置删除,并放到条目链表的尾部(只有条目在链表中的位 置会受影响, 而散列表中的桶不会受影响。一个条目总位于与键散列码对应的桶中) 。要项 构造这样一个的散列映射表,请调用
LinkedHashMapcK, V>(initialCapacity, loadFactor, true)
访问顺序对于实现高速缓存的“ 最近最少使用” 原则十分重要。例如, 可能希望将访问 频率高的元素放在内存中, 而访问频率低的元素则从数据库中读取。当在表中找不到元素项 且表又已经满时,可以将迭代器加入到表中, 并将枚举的前几个元素删除掉。这些是近期最 少使用的几个元素。
枚举集与映射
EmimSet 是一个枚举类型元素集的高效实现。由于枚举类型只有有限个实例, 所以 EnumSet 内部用位序列实现。如果对应的值在集中, 则相应的位被置为 1。 EnumSet 类没有公共的构造器。可以使用静态工厂方法构造这个集:
enum Weekday { MONDAY, TUESDAY, WEDNESDAY, THURSDAY, FRIDAY, SATURDAY, SUNDAY }; EnumSet<Weekday> always = EnumSet.allOf(Weekday.class); EnumSet<Weekday> never = EnumSet.noneOf(Weekday.class); EnumSet<Weekday> workday = EnumSet.range(Weekday.MONDAY, Weekday.FRIDAY); EnumSet<Weekday> mwf = EnumSet.of(Weekday.MONDAY, Weekday.WEDNESDAY, Weekday.FRIDAY);
可以使用 Set 接口的常用方法来修改 EnumSet。
标识散列映射
类 IdentityHashMap 有特殊的作用。在这个类中, 键的散列值不是用 hashCode 函数计算 的, 而是用 System.identityHashCode 方法计算的。 这是 Object.hashCode 方法根据对象的内 存地址来计算散列码时所使用的方式。而且, 在对两个对象进行比较时, IdentityHashMap 类 使用 ==, 而不使用 equals。
也就是说, 不同的键对象, 即使内容相同, 也被视为是不同的对象。 在实现对象遍历算 法(如对象串行化)时, 这个类非常有用, 可以用来跟踪每个对象的遍历状况。
视图与包装器
用如此多的接口和抽象类来实现数量并不多的具 体集合类似乎没有太大必要。然而,这两张图并没有展示出全部的情况。通过使用视图 ( views) 可以获得其他的实现了 Collection接口和 Map 接口的对象。映射类的 keySet 方法就 是一个这样的示例。初看起来, 好像这个方法创建了一个新集, 并将映射中的所有键都填进 去,然后返回这个集。但是, 情况并非如此。取而代之的是:keySet方法返回一个实现 Set 接口的类对象, 这个类的方法对原映射进行操作。这种集合称为视图。
轻量级集合包装器
Arrays 类的静态方法 asList 将返回一个包装了普通 Java 数组的 List 包装器。这个方法可 以将数组传递给一个期望得到列表或集合参数的方法。例如:
Card[] cardOeck = new Card[52]; List<Card> cardList = Arrays.asList(cardDeck):
返回的对象不是 ArrayList。它是一个视图对象, 带有访问底层数组的 get 和 set方 法。改变数组大小的所有方法(例如,与迭代器相关的 add 和 remove 方法)都会抛出一个 UnsupportedOperationException 异常。
asList方法可以接收可变数目的参数。例如:
List<String> names = Arrays.asList("A«iy", "Bob", "Carl");
这个方法调用
Col1ections.nCopies(n, anObject)
将返回一个实现了 List 接口的不可修改的对象, 并给人一种包含n个元素, 每个元素都像是 一个 anObject 的错觉。
子范围
可以为很多集合建立子范围(subrange) 视图。例如, 假设有一个列表 staff, 想从中取出 第 10 个 ~ 第 19 个元素。可以使用 subList方法来获得一个列表的子范围视图。
List group2 = staff.subList(10, 20);
第一个索引包含在内, 第二个索引则不包含在内。这与 String类的 substring 操作中的参 数情况相同。
可以将任何操作应用于子范围,并且能够自动地反映整个列表的情况。例如, 可以删除 整个子范围:
group2.clear(); // staff reduction
现在, 元素自动地从 staff 列表中清除了, 并且 group2 为空。
对于有序集和映射, 可以使用排序顺序而不是元素位置建立子范围。SortedSet 接口声明 了 3 个方法:
SortedSet<E> subSet(E from, E to) SortedSet<E> headSet(E to) SortedSet<E> tailSet(E from)
这些方法将返回大于等于 from 且小于 to 的所有元素子集。有序映射也有类似的方法:
SortedMap<K, V> subMap(K from, K to) SortedMap<K, V> headMap(K to) SortedMap<K, V> tailMap(K from)
返回映射视图, 该映射包含键落在指定范围内的所有元素。
不可修改的视图
Collections 还有几个方法, 用于产生集合的不可修改视图 (unmodifiable views)。这些视图对现有集合增加了一个运行时的检查。如果发现视图对集合进行修改, 就抛出一个异常, 同时这个集合将保持未修改的状态。
可以使用下面 8 种方法获得不可修改视图:
Collections.unmodifiableCollection
Collections.unmodifiableList
Collections.unmodifiableSet
Collections.unmodifiableSortedSet
Collections.unmodifiableNavigableSet
Collections.unmodifiableMap
Collections.unmodifiableSortedMap
Collections.unmodifiableNavigableMap
每个方法都定义于一个接口。 例如, Collections.unmodifiableList 与 ArrayList、 LinkedList 或者任何实现了 List 接口的其他类一起协同工作。
例如, 假设想要查看某部分代码, 但又不触及某个集合的内容, 就可以进行下列操作:
List<String> staff = new LinkedListoO;
...
lookAt(Collections.unmodifiableList(staff));
Collections-unmodifiableList 方法将返回一个实现 List 接口的类对象。 其访问器方法将从 staff集合中获取值。当然,lookAt 方法可以调用 List 接口中的所有方法,而不只是访问器。但 是所有的更改器方法(例如,add) 已经被重新定义为抛出一个 UnsupportedOperationException 异常,而不是将调用传递给底层集合。
不可修改视图并不是集合本身不可修改。仍然可以通过集合的原始引用(在这里是 staff) 对集合进行修改。并且仍然可以让集合的元素调用更改器方法。
由于视图只是包装了接口而不是实际的集合对象, 所以只能访问接口中定义的方法。例 如, LinkedList 类有一些非常方便的方法,addFirst 和 addLast,它们都不是 List 接口的方法, 不能通过不可修改视图进行访问。
同步视图
如果由多个线程访问集合,就必须确保集不会被意外地破坏。例如, 如果一个线程试图 将元素添加到散列表中,同时另一个线程正在对散列表进行再散列,其结果将是灾难性的。
类库的设计者使用视图机制来确保常规集合的线程安全,而不是实现线程安全的集合 类。例如, Collections 类的静态 synchronizedMap方法可以将任何一个映射表转换成具有同 步访问方法的 Map:
Map<String, Employee〉map = Collections.synchronizedMap(new HashMap<String, Employee>0);
现在,就可以由多线程访问 map对象了。像 get 和 put 这类方法都是同步操作的,即在 另一个线程调用另一个方法之前,刚才的方法调用必须彻底完成。
受查视图
“ 受査” 视图用来对泛型类型发生问题时提供调试支持。实际上将错 误类型的元素混人泛型集合中的问题极有可能发生。例如:
ArrayList<String> strings = new ArrayListoO; ArrayList rawList = strings; // warning only, not an error, for compatibility with legacy code rawList.add(new DateO); // now strings contains a Date object!
这个错误的 add命令在运行时检测不到。相反,只有在稍后的另一部分代码中调用 get方法,并将结果转化为 String 时,这个类才会抛出异常。
受査视图可以探测到这类问题。下面定义了一个安全列表:
List<String> safestrings = Collections.checkedList(strings,String,class);
视图的 add 方法将检测插人的对象是否属于给定的类。如果不属于给定的类,就立即抛 出一个 ClassCastException。这样做的好处是错误可以在正确的位置得以报告:
ArrayList rawList = safestrings;
rawList.add(new DateO);// checked list throws a ClassCastException
算 法
排序与混排
Collections 类中的 sort方法可以对实现了 List 接口的集合进行排序。
List<String> staff = new LinkedListo(); fill collection Collections,sort(staff);
这个方法假定列表元素实现了 Comparable接口。如果想采用其他方式对列表进行排序,可 以使用List接口的 sort方法并传入一个 Comparator对象。可以如下按工资对一个员工列表排序i:
staff_sort(Comparator.comparingDouble(Employee::getSalary));
如果想按照降序对列表进行排序, 可以使用一种非常方便的静态方法 Collections.reverseOrder()。这个方法将返回一个比较器, 比较器则返回 b.compareTo(a)。例如,
staff.sort(Comparator.reverseOrder())
这个方法将根据元素类型的 compareTo方法给定排序顺序, 按照逆序对列表 staff进行排 序。同样,
staff.sort(Comparator.comparingDouble(Employee::getSalary).reversed())
将按工资逆序排序。
程序清单 9-7中的程序用 1 ~ 49 之间的 49 个 Integer 对象填充数组。然后,随机地打乱 列表,并从打乱后的列表中选前 6 个值。最后再将选择的数值进行排序和打印。
//程序澝单 9-7 shuffle/ShuffleTest.java package shuffle; import java.util.*; /** * This program demonstrates the random shuffle and sort algorithms. * @version 1.12 2018-04-10 * @author Cay Horstmann */ public class ShuffleTest { public static void main(String[] args) { var numbers = new ArrayList<Integer>(); for (int i = 1; i <= 49; i++) numbers.add(i); Collections.shuffle(numbers); List<Integer> winningCombination = numbers.subList(0, 6); Collections.sort(winningCombination); System.out.println(winningCombination); } }
二分查找
Collections类的 binarySearch方法实现了这个算法。注意, 集合必须是排好序的, 否则 算法将返回错误的答案。要想查找某个元素,必须提供集合(这个集合要实现 List 接口, 下 面还要更加详细地介绍这个问题)以及要查找的元素。如果集合没有采用 Comparable 接口的 compareTo方法进行排序, 就还要提供一个比较器对象。
i = Collections.binarySearch(c, element);
i = Collections.binarySearch(c, element, comparator);
如果 binarySearch方法返回的数值大于等于 0, 则表示匹配对象的索引。也就是说, c.get(i) 等于在这个比较顺序下的 element。如果返回负值, 则表示没有匹配的兀素。但是, 可以利用返回值计算应该将 element 插人到集合的哪个位置, 以保持集合的有序性。插人的 位置是
insertionPoint = -i -1 ;
这并不是简单的-i ,因为 0值是不确定的。也就是说, 下面这个操作:
if (i < 0)
c.add(-i - 1 , element);
将把元素插人到正确的位置上。
只有采用随机访问,二分査找才有意义。如果必须利用迭代方式一次次地遍历链表的一 半元素来找到中间位置的元素,二分査找就完全失去了优势。因此,如果为 binarySearch 算 法提供一个链表,它将自动地变为线性查找。
简单算法
在 Collections 类中包含了几个简单且很有用的算法。前面介绍的查找集合中最大元素的 示例就在其中。另外还包括:将一个列表中的元素复制到另外一个列表中;用一个常量值填 充容器;逆置一个列表的元素顺序。
批操作
很多操作会“ 成批” 复制或删除元素。以下调用
coll1.removeAll(coll2);
将从 coll1中删除 coll2中出现的所有元素。与之相反,
coll1.retainAll(coll2); 会
从 coll1 中删除所有未在 C0112 中出现的元素。
集合与数组的转换
如果需要把一个数组转换为集合,Arrays.asList 包装器可以达到这个目的。例如:
String[] values = . . .;
HashSet<String> staff = new HashSeto(Arrays.asList(values));
从集合得到数组会更困难一些。当然,可以使用 toArray方法:
Object[] values = staff.toArray();
不过,这样做的结果是一个对象数组。尽管你知道集合中包含一个特定类型的对象,但 不能使用强制类型转换:
String[] values = (String[]) staff.toArray();// Error!
toArray方法返回的数组是一个 Object[] 数组, 不能改变它的类型。实际上,必须使用 toArray方法的一个变体形式,提供一个所需类型而且长度为 0 的数组。这样一来, 返回的数 组就会创建为相同的数组类型:
String[] values = staff.toArray(new String[]);
如果愿意,可以构造一个指定大小的数组:
staff.toArray(new String[staff.size()]);
在这种情况下,不会创建新数组。
遗留的集合
Hashtable 类
Hashtable 类与 HashMap类的作用一样,实际上,它们拥有相同的接口。与 Vector 类的 方法一样。Hashtable 的方法也是同步的。如果对同步性或与遗留代码的兼容性没有任何要求, 就应该使用 HashMap。如果需要并发访问, 则要使用 ConcurrentHashMap。
枚举
遗留集合使用 Enumeration接口对元素序列进行遍历。Enumeration接口有两个方法, 即 hasMoreElements 和 nextElement。这两个方法与 Iterator 接口的 hasNext 方法和 next 方法十 分类似。 例如,Hashtable 类的 elements 方法将产生一个用于描述表中各个枚举值的对象:
Enuineration<Einployee> e = staff.elements(); whi1e (e.HasMoreElements()) { Eniployee e = e.nextElement(); ... }
有时还会遇到遗留的方法,其参数是枚举类型的。静态方法 Collections.enumeration将产 生一个枚举对象,枚举集合中的元素。例如:
List<InputStream> streams = . . .; Sequencel叩utStream in = new SequencelnputStream(Collections.enumeration(streams)); // the SequencelnputStream constructor expects an enumeration
属性映射
属性映射(property map) 是一个类型非常特殊的映射结构。它有下面 3 个特性:
•键与值都是字符串。
•表可以保存到一个文件中,也可以从文件中加载。
•使用一个默认的辅助表。
实现属性映射的 Java 平台类称为 Properties。
属性映射通常用于程序的特殊配置选项。
栈
从 1.0 版开始,标准类库中就包含了 Stack类,其中有大家熟悉的 push方法和 pop方法。 但是, Stack 类扩展为 Vector 类,从理论角度看,Vector 类并不太令人满意,它可以让栈使 用不属于栈操作的 insert 和 remove方法,即可以在任何地方进行插入或删除操作,而不仅仅 是在栈顶。
位集
java平台的 BitSet类用于存放一个位序列(它不是数学上的集,称为位向量或位数组更 为合适)。如果需要高效地存储位序列(例如,标志)就可以使用位集。由于位集将位包装在 字节里,所以,使用位集要比使用 Boolean对象的 ArrayList 更加高效。
BitSet 类提供了一个便于读取、设置或清除各个位的接口。使用这个接口可以避免屏蔽 和其他麻烦的位操作。如果将这些位存储在 int 或丨ong变量中就必须进行这些繁琐的操作。
例如,对于一个名为 bucketOfBits 的 BitSet,
bucketOfBits.get( i)
如果第 i 位处于“ 开” 状态,就返回 true; 否则返回 false。同样地,
bucketOfBits.set(i)
将第 i 位置为“ 开” 状态。最后,
bucketOfBits.clear(i)
将第 i 位置为“ 关” 状态。
这里并不想深人程序的细节,关键是要遍历一个拥有 200万个位的位集。首先将所有的 位置为“ 开” 状态,然后,将已知素数的倍数所对应的位都置为“ 关” 状态。经过这个操作 保留下来的位对应的就是素数。 程序清单 9-8 是用 Java 程序设计语言实现的这个算法程序, 而程序清单 9-9mmC++ 实现的这个算法程序。
//程序清单 9-8 sieve/Sieve.java package sieve; import java.util.*; /** * This program runs the Sieve of Erathostenes benchmark. It computes all primes up to 2,000,000. * @version 1.21 2004-08-03 * @author Cay Horstmann */ public class Sieve { public static void main(String[] s) { int n = 2000000; long start = System.currentTimeMillis(); BitSet b = new BitSet(n + 1); int count = 0; int i; for (i = 2; i <= n; i++) b.set(i); i = 2; while (i * i <= n) { if (b.get(i)) { count++; int k = 2 * i; while (k <= n) { b.clear(k); k += i; } } i++; } while (i <= n) { if (b.get(i)) count++; i++; } long end = System.currentTimeMillis(); System.out.println(count + " primes"); System.out.println((end - start) + " milliseconds"); } }
//程序清单 9-9 sieve/Sieve.cpp /** @version 1.21 2004-08-03 @author Cay Horstmann */ #include <bitset> #include <iostream> #include <ctime> using namespace std; int main() { const int N = 2000000; clock_t cstart = clock(); bitset<N + 1> b; int count = 0; int i; for (i = 2; i <= N; i++) b.set(i); i = 2; while (i * i <= N) { if (b.test(i)) { count++; int k = 2 * i; while (k <= N) { b.reset(k); k += i; } } i++; } while (i <= N) { if (b.test(i)) count++; i++; } clock_t cend = clock(); double millis = 1000.0 * (cend - cstart) / CLOCKS_PER_SEC; cout << count << " primes\n" << millis << " milliseconds\n"; return 0; }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号