


通配符概念
通配符类型中, 允许类型参数变化。 例如, 通配符类型
Pair<? extends Employee>
表示任何泛型 Pair 类型, 它的类型参数是 Employee 的子类, 如 Pair<Manager>, 但不是 Pair<String>。
假设要编写一个打印雇员对的方法, 像这样:
public static void printBuddies(Pair <Employee> p) { Employee first = p.getFirst(); Employee second = p.getSecondO; Systefn.out.println(first.getName() + " and " + second.getNameQ + " are buddies."); }
正如前面讲到的,不能将 Pair<Manager> 传递给这个方法,这一点很受限制。解决的方 法很简单:使用通配符类型:
public static void printBuddies(Pair<? extends Eiployee> p)
类型 Pair<Manager> 是 Pair<? extends Employee> 的子类型。
通配符的超类型限定
通配符限定与类型变量限定十分类似,但是,还有一个附加的能力,即可以指定一个超 类型限定(supertypebound), 如下所亦:
? super Manager
这个通配符限制为 Manager 的所有超类型。(已有的 super关键字十分准确地描述了这种 联系, 这一点令人感到非常欣慰。
证返回对象的类型。只能把它赋给一个 Object。 下面是一个典型的示例。有一个经理的数组,并且想把奖金最高和最低的经理放在一个 Pair 对象中。Pair 的类型是什么? 在这里,Pair<Employee> 是合理的, Pair<Object> 也是合 理的,下面的方法将可以接受任何适当的 Pair:
public static void minmaxBonus(Manager[] a, Pair<? super Manager> result) { if (a.length == 0) return; Manager rain = a[0]; Manager max = a[0]; for (int i *1 ; i < a.length; i++) { if (min.getBonusO > a[i].getBonus()) rain = a[i]; if (max.getBonusO < a[i].getBonus()) max = a[i]; } result.setFirst(min); result.setSecond(max); }
直观地讲,带有超类型限定的通配符可以向泛型对象写人,带有子类型限定的通配符可 以从泛型对象读取。
子类型限定的另一个常见的用法是作为一个函数式接口的参数类型。 例如、Collection接口有一个方法:
default boolean reniovelf(Predicated super E> filter)
这个方法会删除所有满足给定谓词条件的元素。例如, 如果你不喜欢有奇怪散列码 的员工,就可以如下将他们删除:
ArrayList<Employee> staff = . . .; Predicate<Object> oddHashCode = obj -> obj.hashCodeO %2 U 0; staff.removelf(oddHashCode);
你希望传入一个 Predicate<Object>, 而不只是 Predicate<Employee>。Super 通配符可 以使这个愿望成真。
无限定通配符
可以使用无限定的通配符, 例如,Pair<?>。初看起来,这好像与原始的 Pair 类型一样。 实际上,有很大的不同。类型 Pair<?> 有以下方法:
? getFirst()
void setFirst(?)
getFirst 的返回值只能赋给一个 Object。setFirst 方法不能被调用, 甚至不能用 Object 调 用。Pair<?> 和 Pair 本质的不同在于: 可以用任意 Object 对象调用原始 Pair 类的 setObject 方法。
通配符捕获
编写一个交换成对元素的方法:
public static void swap(Pair<?> p)
通配符不是类型变量, 因此, 不能在编写代码中使用“ ?” 作为一种类型。也就是说, 下述 代码是非法的:
? t = p.getFirstO; // Error p.setFirst(p_getSecond()); p.setSecond(t);
这是一个问题, 因为在交换的时候必须临时保存第一个元素。幸运的是, 这个问题有一 个有趣的解决方案。我们可以写一个辅助方法 swapHelper, 如下所示:
public static <T> void swapHelper(Pair<T> p) { T t = p.getFirstO; p.setFirst(p.getSecond()); p.setSecond(t); }
注意, swapHelper 是一个泛型方法, 而 swap不是, 它具有固定的 Pair<?> 类型的参数。
现在可以由 swap 调用 swapHelper: public static void swap(Pair<?> p) { swapHelper(p); }
在这种情况下,swapHelper 方法的参数 T 捕获通配符。它不知道是哪种类型的通配符, 但是, 这是一个明确的类型,并且 <T>swapHelper 的定义只有在 T 指出类型时才有明确的含义。
程序清单 8-3 中的测试程序将前几节讨论的各种方法综合在一起, 读者从中可以看到它 们彼此之间的关联。
//程序清单8-3 pair3/PairTest3.java package pair3; /** * @version 1.01 2012-01-26 * @author Cay Horstmann */ public class PairTest3 { public static void main(String[] args) { Manager ceo = new Manager("Gus Greedy", 800000, 2003, 12, 15); Manager cfo = new Manager("Sid Sneaky", 600000, 2003, 12, 15); Pair<Manager> buddies = new Pair<>(ceo, cfo); printBuddies(buddies); ceo.setBonus(1000000); cfo.setBonus(500000); Manager[] managers = { ceo, cfo }; Pair<Employee> result = new Pair<>(); minmaxBonus(managers, result); System.out.println("first: " + result.getFirst().getName() + ", second: " + result.getSecond().getName()); maxminBonus(managers, result); System.out.println("first: " + result.getFirst().getName() + ", second: " + result.getSecond().getName()); } public static void printBuddies(Pair<? extends Employee> p) { Employee first = p.getFirst(); Employee second = p.getSecond(); System.out.println(first.getName() + " and " + second.getName() + " are buddies."); } public static void minmaxBonus(Manager[] a, Pair<? super Manager> result) { if (a == null || a.length == 0) return; Manager min = a[0]; Manager max = a[0]; for (int i = 1; i < a.length; i++) { if (min.getBonus() > a[i].getBonus()) min = a[i]; if (max.getBonus() < a[i].getBonus()) max = a[i]; } result.setFirst(min); result.setSecond(max); } public static void maxminBonus(Manager[] a, Pair<? super Manager> result) { minmaxBonus(a, result); PairAlg.swapHelper(result); // OK--swapHelper captures wildcard type } } class PairAlg { public static boolean hasNulls(Pair<?> p) { return p.getFirst() == null || p.getSecond() == null; } public static void swap(Pair<?> p) { swapHelper(p); } public static <T> void swapHelper(Pair<T> p) { T t = p.getFirst(); p.setFirst(p.getSecond()); p.setSecond(t); } }
反射和泛型
泛型 Class 类
现在, Class 类是泛型的。例如, String.class 实际上是一个 <: 以8<8出呢> 类的对象(事 实上,是唯一的对象)。
类型参数十分有用, 这是因为它允许 ClaSS<T> 方法的返回类型更加具有针对性。下面 Class<T> 中的方法就使用了类型参数:
T newInstance() T cast(Object obj) T[] getEnumConstants() Class<? super T> getSuperclass() Constructors getConstructor( C1ass... parameterTypes) Constructors getDeclaredConstructor(Class... parameterTypes)
newlnstance 方法返回一个实例,这个实例所属的类由默认的构造器获得。它的返回类型 目前被声明为 T, 其类型与 Class<T> 描述的类相同,这样就免除了类型转换。
如果给定的类型确实是 T 的一个子类型,cast 方法就会返回一个现在声明为类型 T 的对 象, 否则,抛出一个 BadCastException 异常。
如果这个类不是 enum 类或类型 T 的枚举值的数组, getEnumConstants方法将返回 null。
最后, getConstructor 与 getdeclaredConstructor方 法 返 回 一 个 Constructor<T> 对象。 Constructor 类也已经变成泛型, 以便 newlnstance 方法有一个正确的返回类型。
使用 Class<T> 参数进行类型匹配
有时, 匹配泛型方法中的 Class<I> 参数的类型变量很有实用价值。下面是一 标准的示例:
public static <T> Pair<T> makePair(Class<T> c) throws InstantiationException, IllegalAccessException { return new Pair<>(c.newInstance(), c.newInstance()); }
如果调用
makePair(Employee.class)
Employee.class 是类型 Class<Employee> 的一个对象。makePair方法的类型参数 T 同 Employee 匹配, 并且编译器可以推断出这个方法将返回一个 Pair<Employee>。
虚拟机中的泛型类型信息
Java 泛型的卓越特性之一是在虚拟机中泛型类型的擦除。令人感到奇怪的是, 擦除的类 仍然保留一些泛型祖先的微弱记忆。例如, 原始的 Pair 类知道源于泛型类 Pair<T>, 即使一 个 Pair 类型的对象无法区分是由 PaiKString> 构造的还是由 PaiKEmployee> 构造的。
类似地,看一下方法
public static Comparable min(Coniparable[] a)
这是一个泛型方法的擦除
public static <T extends Comparable<? super T>>T min(T[] a)
可以使用反射 API 来确定:
•这个泛型方法有一个叫做 T 的类型参数。
•这个类型参数有一个子类型限定, 其自身又是一个泛型类型。
•这个限定类型有一个通配符参数。
•这个通配符参数有一个超类型限定。
•这个泛型方法有一个泛型数组参数。
换句话说,需要重新构造实现者声明的泛型类以及方法中的所有内容。但是,不会知道 对于特定的对象或方法调用,如何解释类型参数。
程序清单 8-4 中使用泛型反射 AI>I 打印出给定类的有关内容。如果用 Pair类运行, 将会 得到下列报告:
class Pair<T> extends java.lang.Object public T getFirst() public T getSecond() public void setFirst(T) public void setSecond(T)
如果使用 PairTest2 目录下的 ArrayAlg运行, 将会得到下列报告:
public static <T extends java.lang.Comparable〉Pair<T> minmax(T[])
//程序清单 8-4 genericReflection/GenericReflectionTest.java package genericReflection; import java.lang.reflect.*; import java.util.*; /** * @version 1.10 2007-05-15 * @author Cay Horstmann */ public class GenericReflectionTest { public static void main(String[] args) { // read class name from command line args or user input String name; if (args.length > 0) name = args[0]; else { Scanner in = new Scanner(System.in); System.out.println("Enter class name (e.g. java.util.Collections): "); name = in.next(); } try { // print generic info for class and public methods Class<?> cl = Class.forName(name); printClass(cl); for (Method m : cl.getDeclaredMethods()) printMethod(m); } catch (ClassNotFoundException e) { e.printStackTrace(); } } public static void printClass(Class<?> cl) { System.out.print(cl); printTypes(cl.getTypeParameters(), "<", ", ", ">", true); Type sc = cl.getGenericSuperclass(); if (sc != null) { System.out.print(" extends "); printType(sc, false); } printTypes(cl.getGenericInterfaces(), " implements ", ", ", "", false); System.out.println(); } public static void printMethod(Method m) { String name = m.getName(); System.out.print(Modifier.toString(m.getModifiers())); System.out.print(" "); printTypes(m.getTypeParameters(), "<", ", ", "> ", true); printType(m.getGenericReturnType(), false); System.out.print(" "); System.out.print(name); System.out.print("("); printTypes(m.getGenericParameterTypes(), "", ", ", "", false); System.out.println(")"); } public static void printTypes(Type[] types, String pre, String sep, String suf, boolean isDefinition) { if (pre.equals(" extends ") && Arrays.equals(types, new Type[] { Object.class })) return; if (types.length > 0) System.out.print(pre); for (int i = 0; i < types.length; i++) { if (i > 0) System.out.print(sep); printType(types[i], isDefinition); } if (types.length > 0) System.out.print(suf); } public static void printType(Type type, boolean isDefinition) { if (type instanceof Class) { Class<?> t = (Class<?>) type; System.out.print(t.getName()); } else if (type instanceof TypeVariable) { TypeVariable<?> t = (TypeVariable<?>) type; System.out.print(t.getName()); if (isDefinition) printTypes(t.getBounds(), " extends ", " & ", "", false); } else if (type instanceof WildcardType) { WildcardType t = (WildcardType) type; System.out.print("?"); printTypes(t.getUpperBounds(), " extends ", " & ", "", false); printTypes(t.getLowerBounds(), " super ", " & ", "", false); } else if (type instanceof ParameterizedType) { ParameterizedType t = (ParameterizedType) type; Type owner = t.getOwnerType(); if (owner != null) { printType(owner, false); System.out.print("."); } printType(t.getRawType(), false); printTypes(t.getActualTypeArguments(), "<", ", ", ">", false); } else if (type instanceof GenericArrayType) { GenericArrayType t = (GenericArrayType) type; System.out.print(""); printType(t.getGenericComponentType(), isDefinition); System.out.print("[]"); } } }
第九章 集合
Java 集合框架
将集合的接口与实现分离
与现代的数据结构类库的常见情况一样, Java 集合类库也将接口( interface) 与 实 现 (implementation) 分离。
队列接口指出可以在队列的尾部添加元素, 在队列的头部删除元素,并且可以査找队列 中元素的个数。当需要收集对象, 并按照“ 先进先出” 的规则检索对象时就应该使用队列(见 图 9-1 )。
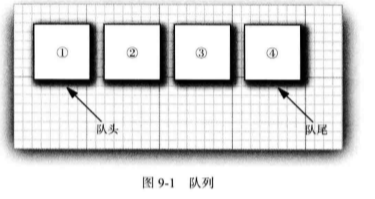
队列接口的最简形式可能类似下面这样:
public interface Queue<E> // a simplified form of the interface in the standard library { void add(E element); E remove(); int size(); }
这个接口并没有说明队列是如何实现的。队列通常有两种实现方式: 一种是使用循环数 组;另一种是使用链表(见图 9-2 )。
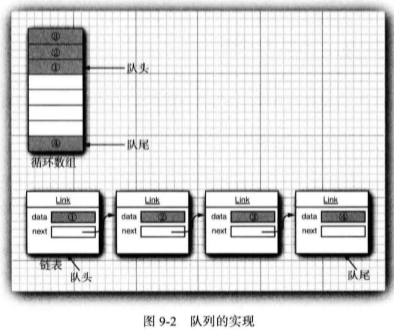
每一个实现都可以通过一个实现了 Queue 接口的类表示。
public class CircularArrayQueue<E> implements Queue<E> // not an actual library class { private int head; private int tail; CircularArrayQueue(int capacity) { .. . } public void add(E element) { . . . } public E remove0 { . .. } public int size() { ... } private E[] elements; } public class LinkedListQueue<E> iipleients Queue<E> // not an actual library class { private Link head; private Link tail; LinkedListQueueO { .. . } public void add(E element) { ...} public E remove() { ... } public int size() { ... } }
当在程序中使用队列时,一旦构建了集合就不需要知道究竟使用了哪种实现。因此, 只 有在构建集合对象时,使用具体的类才有意义。可以使用接口类型存放集合的引用。
Queue<Customer> expresslane = new CircularArrayQueue<>(100): expressLane.add(new Customer("Harry"));、
循环数组是一个有界集合, 即容量有限。如果程序中要收集的对象数量没有上限, 就最 好使用链表来实现。
Collection 接口
在 Java 类库中,集合类的基本接口是 Collection 接口。这个接口有两个基本方法:
public interface Collection<b { boolean add(E element); Iterator<E> iterator(); }
add方法用于向集合中添加元素。如果添加元素确实改变了集合就返回 true, 如果集合 没有发生变化就返回 false。例如, 如果试图向集中添加一个对象, 而这个对象在集中已经存 在,这个添加请求就没有实效,因为集中不允许有重复的对象。
iterator方法用于返回一个实现了 Iterator 接口的对象。可以使用这个迭代器对象依次访 问集合中的元素。
迭代器
Iterator 接口包含 4个方法:
public interface Iterator<E> { E next(); boolean hasNext(); void remove(); default void forEachRemaining(Consumer<? super E> action); }
通过反复调用 next 方法,可以逐个访问集合中的每个元素。但是,如果到达了集合的末 尾,next 方法将抛出一个 NoSuchElementException。 因此,需要在调用next 之前调用 hasNext 方法。如果迭代器对象还有多个供访问的元素, 这个方法就返回 true。如果想要査看集合中的 所有元素,就请求一个迭代器,并在hasNext返回 true 时反复地调用 next方法。例如:
Collection<String> c = . . .; Iterator<String> iter = c.iterator(); while (iter.hasNextO) { String element = iter.next(); dosomethingwith element }
用“ foreach” 循环可以更加简练地表示同样的循环操作:
for (String element : c) { dosomethingwith element }
编译器简单地将“ foreach” 循环翻译为带有迭代器的循环。
泛型实用方法
由于 Collection与 Iterator 都是泛型接口,可以编写操作任何集合类型的实用方法。例 如,下面是一个检测任意集合是否包含指定元素的泛型方法:
public static <E> boolean contains(Collection<E> c, Object obj) { for (E element : c) if (element,equals(obj)) return true; return false; }
Java类库的设计者认为:这些实用方法中的某些方法非常有用,应该将它们提供给用户使 用。这样,类库的使用者就不必自己重新构建这些方法了。contains 就是这样一个实用方法。
集合框架中的接口
Java 集合框架为不同类型的集合定义了大量接口, 如图 9-4 所示。
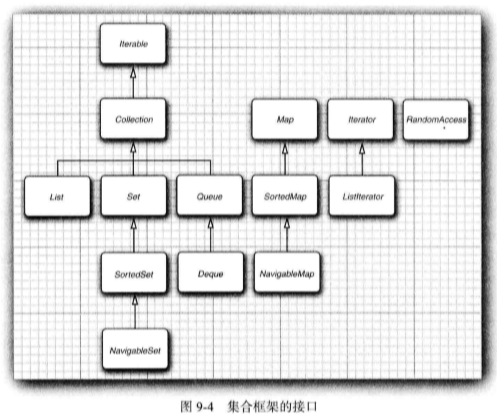
集合有两个基本接口:Collection 和 Map。
List 是一个有序集合(or办 元 素 会 增 加 到 容 器 中 的 特 定 位 置。可 以 采 用 两种方式访问元素:使用迭代器访问, 或者使用一个整数索引来访问。后一种方法称为随机访问(random access), 因为这样可以按任意顺序访问元素。与之不同, 使用迭代器访问时,必须顺序地访问元素。
List 接口定义了多个用于随机访问的方法:Java
void add(int index, E element) void remove(int index) E get(int index) E set(int index, E element)
Listlterator 接口是 Iterator 的一个子接口。它定义了一个方法用于在迭代器位置前面增加 一个元素:
void add(E element)
坦率地讲,集合框架的这个方面设计得很不好。实际中有两种有序集合,其性能开销有 很大差异。由数组支持的有序集合可以快速地随机访问,因此适合使用 List 方法并提供一个 整数索引来访问。与之不同, 链表尽管也是有序的, 但是随机访问很慢,所以最好使用迭代 器来遍历。如果原先提供两个接口就会容易一些了。
具体的集合
链 表
数组和数组列表 都有一个重大的缺陷。这就是从数组的中间位置删除一个元素要付出很大的代价,其原因是 数组中处于被删除元素之后的所有元素都要向数组的前端移动(见图 9-6 )。在数组中间的位 置上插入一个元素也是如此。
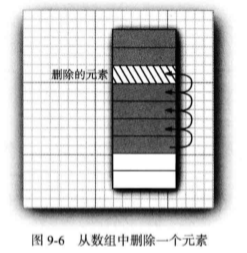
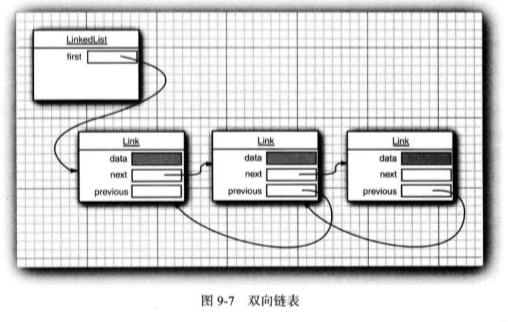
另外一个大家非常熟悉的数据结构一链表(linked list) 解决了这个问题。尽管数组在 连续的存储位置上存放对象引用, 但链表却将每个对象存放在独立的结点中。每个结点还存 放着序列中下一个结点的引用。在 Java 程序设计语言中,所有链表实际上都是双向链接的 (doubly linked)— —即每个结点还存放着指向前驱结点的引用(见图 9-7 )。
从链表中间删除一个元素是一个很轻松的操作, 即需要更新被删除元素附近的链接(见 图 9-8 )。
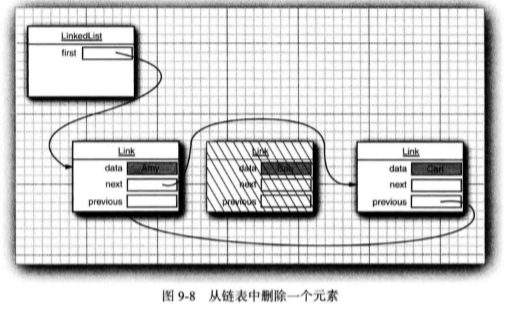
在下面的代码示例中, 先添加 3 个元素, 然后再将第 2 个元素删除:
List<String> staff = new LinkedList<>(); // LinkedList implements List staff.add("Amy"); staff.add(MBobH); staff.add("Carl"); Iterator iter = staff.iterator() ; String first = iter.next();// visit first element String second =iter.next();//visit second element iter.remove(); // remove last visited element
但是, 链表与泛型集合之间有一个重要的区别。链 表 是 一 个 有 序 集 合(ordered collection), 每个对象的位置十分重要。LinkedList.add 方法将对象添加到链表的尾部。但是, 常常需要将元素添加到链表的中间。由于迭代器是描述集合中位置的, 所以这种依赖于位置 的 add 方法将由迭代器负责。只有对自然有序的集合使用迭代器添加元素才有实际意义。例 如, 下一节将要讨论的集(set) 类型,其中的元素完全无序。因此, 在 Iterator 接口中就没有 add 方法。
程序清单 9-1 中的程序使用的就是链表。它简单地创建了两个链表, 将它们合并在一起, 然后从第二个链表中每间隔一个元素删除一个元素, 最后测试 removeAIl 方法。建议跟踪一 下程序流程, 并要特别注意迭代器。
//程序清单 9-1 linkedList/LinkedListTest.java package linkedList; import java.util.*; /** * This program demonstrates operations on linked lists. * @version 1.11 2012-01-26 * @author Cay Horstmann */ public class LinkedListTest { public static void main(String[] args) { List<String> a = new LinkedList<>(); a.add("Amy"); a.add("Carl"); a.add("Erica"); List<String> b = new LinkedList<>(); b.add("Bob"); b.add("Doug"); b.add("Frances"); b.add("Gloria"); // merge the words from b into a ListIterator<String> aIter = a.listIterator(); Iterator<String> bIter = b.iterator(); while (bIter.hasNext()) { if (aIter.hasNext()) aIter.next(); aIter.add(bIter.next()); } System.out.println(a); // remove every second word from b bIter = b.iterator(); while (bIter.hasNext()) { bIter.next(); // skip one element if (bIter.hasNext()) { bIter.next(); // skip next element bIter.remove(); // remove that element } } System.out.println(b); // bulk operation: remove all words in b from a a.removeAll(b); System.out.println(a); } }
数组列表
List 接口用于描述一个有序集合,并且集合中每个元素的位置十分重要。有两种访问元素的协议:一种是用迭代 器, 另一种是用 get 和 set 方法随机地访问每个元素。后者不适用于链表, 但对数组却很有 用。集合类库提供了一种大家熟悉的 ArrayList 类, 这个类也实现了 List 接口。ArrayList 封 装了一个动态再分配的对象数组。
散列集
链表和数组可以按照人们的意愿排列元素的次序。但是,如果想要査看某个指定的元 素, 却又忘记了它的位置, 就需要访问所有元素, 直到找到为止。如果集合中包含的元 素很多, 将会消耗很多时间。如果不在意元素的顺序,可以有几种能够快速査找元素的数 据结构。其缺点是无法控制元素出现的次序。它们将按照有利于其操作目的的原则组织 数据。
有一种众所周知的数据结构, 可以快速地査找所需要的对象, 这就是散列表(hash table)。散列表为每个对象计算一个整数, 称为散列码(hashcode)。散列码是由对象的实例 域产生的一个整数。更准确地说, 具有不同数据域的对象将产生不同的散列码。
在 Java中,散列表用链表数组实现。每个列表 被称为桶(bucket) (参看图 9-10 )。要想査找表中对 象的位置, 就要先计算它的散列码, 然后与桶的总 数取余, 所得到的结果就是保存这个元素的桶的索 引。。例如, 如果某个对象的散列码为 76268, 并且 有 128 个桶, 对象应该保存在第 108号桶中(76268 除以 128余 108 )。
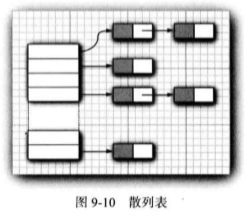
散列集迭代器将依次访问所有的桶。 由于散列将元素分散在表的各个位置上,所以访问 它们的顺序几乎是随机的。只有不关心集合中元素的顺序时才应该使用 HashSet。
本节末尾的示例程序(程序清单 9-2 ) 将从 System.ii 读取单词,然后将它们添加到集 中,最 后, 再 打 印 出 集 中 的 所 有 单 词。例 如,可 以 将 (可 以 从 http://www. gutenberg.org 找到)的文本输人到这个程序中,并从命令行 shell 运行:
java SetTest < alice30.txt
这个程序将读取输人的所有单词, 并且将它们添加到散列集中。然后遍历散列集中的不 同单词,最后打印出单词的数量 (Alice in Wonderland共有 5909 个不同的单词,包括开头的 版权声明) 。单词以随机的顺序出现。
//程序清单 9-2 set/SetTest.java package set; import java.util.*; /** * This program uses a set to print all unique words in System.in. * @version 1.11 2012-01-26 * @author Cay Horstmann */ public class SetTest { public static void main(String[] args) { Set<String> words = new HashSet<>(); // HashSet implements Set long totalTime = 0; Scanner in = new Scanner(System.in); while (in.hasNext()) { String word = in.next(); long callTime = System.currentTimeMillis(); words.add(word); callTime = System.currentTimeMillis() - callTime; totalTime += callTime; } Iterator<String> iter = words.iterator(); for (int i = 1; i <= 20 && iter.hasNext(); i++) System.out.println(iter.next()); System.out.println(". . ."); System.out.println(words.size() + " distinct words. " + totalTime + " milliseconds."); } }
树集
TreeSet类与散列集十分类似, 不过, 它比散列集有所改进。树集是一个有序集合 ( sorted collection)o 可以以任意顺序将元素插入到集合中。在对集合进行遍历时,每个值将 自动地按照排序后的顺序呈现。例如,假设插入 3 个字符串,然后访问添加的所有元素。
SortedSet<String> sorter = new TreeSetoO; // TreeSet implements SortedSet sorter.add("Bob"); sorter.add("Any"); sorter.add("Carl"); for (String s : sorter) System.println(s);
在程序清单 9-3 的程序中创建了两个 Item 对象的树集。第一个按照部件编号排序, 这是 Item 对象的默认顺序。第二个通过使用一个定制的比较器来按照描述信息排序。
//程序清单 9-3 treeSet/TreeSetTest.java package treeSet; /** @version 1.12 2012-01-26 @author Cay Horstmann */ import java.util.*; /** This program sorts a set of item by comparing their descriptions. */ public class TreeSetTest { public static void main(String[] args) { SortedSet<Item> parts = new TreeSet<>(); parts.add(new Item("Toaster", 1234)); parts.add(new Item("Widget", 4562)); parts.add(new Item("Modem", 9912)); System.out.println(parts); SortedSet<Item> sortByDescription = new TreeSet<>(new Comparator<Item>() { public int compare(Item a, Item b) { String descrA = a.getDescription(); String descrB = b.getDescription(); return descrA.compareTo(descrB); } }); sortByDescription.addAll(parts); System.out.println(sortByDescription); } }
//程序清单 9-4 treeSet/Item.java package treeSet; import java.util.*; /** * An item with a description and a part number. */ public class Item implements Comparable<Item> { private String description; private int partNumber; /** * Constructs an item. * @param aDescription the item's description * @param aPartNumber the item's part number */ public Item(String aDescription, int aPartNumber) { description = aDescription; partNumber = aPartNumber; } /** * Gets the description of this item. * @return the description */ public String getDescription() { return description; } public String toString() { return "[description=" + description + ", partNumber=" + partNumber + "]"; } public boolean equals(Object otherObject) { if (this == otherObject) return true; if (otherObject == null) return false; if (getClass() != otherObject.getClass()) return false; var other = (Item) otherObject; return Objects.equals(description, other.description) && partNumber == other.partNumber; } public int hashCode() { return Objects.hash(description, partNumber); } public int compareTo(Item other) { int diff = Integer.compare(partNumber, other.partNumber); return diff != 0 ? diff : description.compareTo(other.description); } }
队列与双端队列
队列可以让人们有效地在尾部添加一个元素, 在头部删除一个元 素。有两个端头的队列, 即双端队列,可以让人们有效地在头部和尾部同时添加或删除元 素。不支持在队列中间添加元素。在 Java SE 6中引人了 Deque 接口,并由 ArrayDeque 和 LinkedList 类实现。这两个类都提供了双端队列,而且在必要时可以增加队列的长度。
优先级队列
优先级队列(priorityqueue) 中的元素可以按照任意的顺序插人,却总是按照排序的顺序 进行检索。也就是说,无论何时调用 remove方法,总会获得当前优先级队列中最小的元素。 然而,优先级队列并没有对所有的元素进行排序。如果用迭代的方式处理这些元素,并不需 要对它们进行排序。优先级队列使用了一个优雅且高效的数据结构,称为堆(heap)。堆是一 个可以自我调整的二叉树,对树执行添加(add) 和删除(remore) 操作, 可以让最小的元素 移动到根,而不必花费时间对元素进行排序。
与 TreeSet—样,一个优先级队列既可以保存实现了 Comparable 接口的类对象, 也可以 保存在构造器中提供的 Comparator 对象。 使用优先级队列的典型示例是任务调度。
每一个任务有一个优先级,任务以随机顺序添 加到队列中。每当启动一个新的任务时,都将优先级最高的任务从队列中删除。
//程序清单 9-5 priorityQueue/PriorityQueueTest.java package priorityQueue; import java.util.*; /** * This program demonstrates the use of a priority queue. * @version 1.01 2012-01-26 * @author Cay Horstmann */ public class PriorityQueueTest { public static void main(String[] args) { PriorityQueue<GregorianCalendar> pq = new PriorityQueue<>(); pq.add(new GregorianCalendar(1906, Calendar.DECEMBER, 9)); // G. Hopper pq.add(new GregorianCalendar(1815, Calendar.DECEMBER, 10)); // A. Lovelace pq.add(new GregorianCalendar(1903, Calendar.DECEMBER, 3)); // J. von Neumann pq.add(new GregorianCalendar(1910, Calendar.JUNE, 22)); // K. Zuse System.out.println("Iterating over elements..."); for (GregorianCalendar date : pq) System.out.println(date.get(Calendar.YEAR)); System.out.println("Removing elements..."); while (!pq.isEmpty()) System.out.println(pq.remove().get(Calendar.YEAR)); } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号