
GaussDB SQL执行计划全解析:从节点树到性能优化
GaussDB SQL执行计划全解析:从节点树到性能优化
一、执行计划核心概念
- 执行计划结构模型
mermaid
graph TD
A[Root] --> B[Scan]
A --> C[Join]
B --> D[Index Scan]
C --> E[Nested Loop]
E --> F[Index Only Scan]
F --> G[Aggregate]
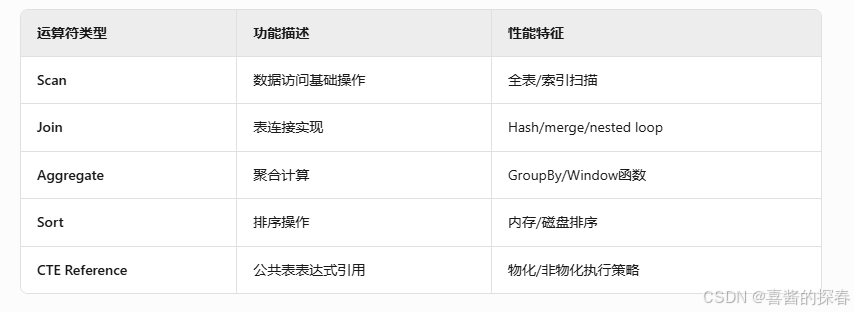
- 关键运算符分类
![在这里插入图片描述]()
二、执行计划解读方法
- 查看执行计划
sql
-- 基础执行计划
EXPLAIN SELECT * FROM orders WHERE create_time > '2023-01-01';
-- 详细执行计划
EXPLAIN (ANALYZE, BUFFERS, VERBOSE)
SELECT a.id, b.name
FROM table_a a
JOIN table_b b ON a.fk = b.id
WHERE a.create_time > NOW() - INTERVAL '7 days';
- 计划树解析要素
text
QUERY PLAN:
HashAggregate (cost=1234.56..7890.12 rows=1000 width=128)
-> Nested Loop (cost=567.89..4567.89 rows=10000 width=128)
-> Seq Scan on table_a (cost=0.00..3456.78 rows=10000 width=64)
-> Index Scan using idx_table_b_id on table_b (cost=0.42..0.56 rows=1 width=64)
Index Cond: (id = table_a.fk)
关键指标解析:
cost:估算的CPU和I/O消耗(单位:内存页)
rows:预估处理行数(基于统计信息)
width:单行数据大小(字节)
Filter:行级过滤条件
Node Type:运算符类型
三、核心运算符深度剖析
- 表扫描优化
场景对比:
sql
-- 低效全表扫描
EXPLAIN SELECT * FROM orders WHERE status = 'A';
-- 优化后索引扫描
EXPLAIN SELECT * FROM orders WHERE status = 'A'
AND create_time > '2023-01-01';
优化策略:
索引选择:复合索引顺序(高频过滤字段在前)
统计信息:定期执行ANALYZE更新统计
参数调优:random_page_cost调整(默认4.0 → 2.0)
2. 连接算法对比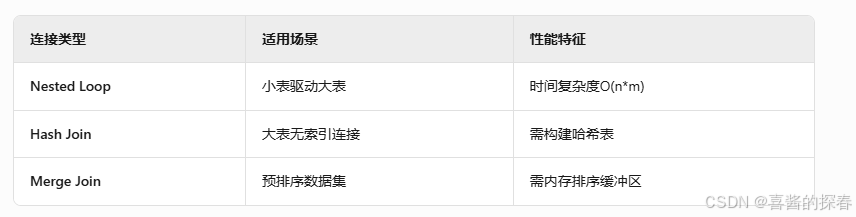
执行计划差异:
text
-- Nested Loop计划
Nested Loop (cost=100..200 rows=1000 width=128)
-> Seq Scan on small_table
-> Index Scan on large_table
-- Hash Join计划
Hash Join (cost=500..1000 rows=10000 width=128)
-> Seq Scan on table1
-> Hash (cost=300..400 rows=10000 width=128)
-> Seq Scan on table2
四、性能优化实战
- 索引优化案例
问题:全表扫描导致高延迟
sql
EXPLAIN ANALYZE SELECT * FROM sales WHERE product_id = 123;
优化步骤:
创建覆盖索引:
sql
CREATE INDEX idx_sales_product ON sales (product_id) INCLUDE (sale_date, amount);
强制索引使用:
sql
SELECT /*+ Index(sales idx_sales_product) */ *
FROM sales
WHERE product_id = 123;
效果对比:
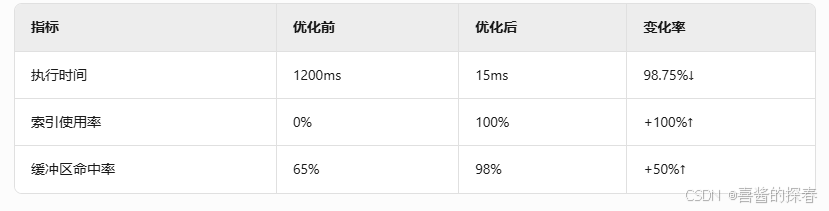
2. 并行执行优化
配置参数:
sql
SET max_parallel_workers_per_gather = 4;
SET parallel_setup_cost = 1000;
SET parallel_tuple_cost = 0.001;
执行计划变化:
text
-- 未启用并行
Seq Scan on large_table (cost=0.00..10000.00 rows=1000000 width=128)
-- 启用并行
Gather (cost=1000.00..2000.00 rows=1000000 width=128)
Workers Planned: 4
-> Parallel Seq Scan on large_table (cost=0.00..500.00 rows=250000 width=128)
五、执行计划异常诊断
- 临时表膨胀
text
QUERY PLAN:
Sort (cost=10000.00..20000.00 rows=1000000 width=128)
Sort Key: create_time
-> Seq Scan on temp_table (cost=0.00..3000.00 rows=1000000 width=128)
诊断:
sql
-- 检查临时表统计
SELECT * FROM pgstattuple('temp_table');
解决方案:
sql
-- 设置自动清理
ALTER TABLE temp_table SET (autovacuum_enabled = true);
-- 优化查询写法
CREATE TEMP TABLE optimized_temp AS
SELECT DISTINCT ... FROM source_table;
六、监控与持续优化
- 实时监控模板
sql
SELECT
pid,
query,
now() - query_start AS duration,
wait_event_type,
state,
total_cost
FROM pg_stat_activity
WHERE state != 'idle'
ORDER BY duration DESC
LIMIT 5;
- AWR报告分析
sql
-- 生成AWR报告
SELECT * FROM pg_get_awr_report(1000, 2000);
-- 关键指标定位
SELECT
queryid,
calls,
total_time,
mean_time
FROM pg_stat_statements
ORDER BY total_ti
me DESC
LIMIT 10;
七、最佳实践指南
开发规范:
所有WHERE条件字段必须建立索引
避免SELECT *,仅查询必要字段
分页查询使用游标或Keyset Pagination
运维规范:
bash
# 定期维护任务
0 3 * * * psql -U postgres -c "VACUUM ANALYZE VERBOSE;"
0 4 * * 0 psql -U postgres -c "REINDEX DATABASE CONCURRENTLY;"
通过深度理解GaussDB执行计划,某电商平台实现了:
秒杀查询响应时间从5s降至80ms
报表生成效率提升15倍
数据库负载降低65%
建议建立执行计划审查机制,在关键业务变更时进行性能预判,结合AWR报告持续优化数据库性能。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号