第六周作业23-31题
23. 实现mysql主从复制,主主复制,半同步复制,过滤复制。
MySQL主从复制是指将一个MySQL服务器的数据复制到另一个MySQL服务器上,从而实现数据的备份、负载均衡等功能。下面是实现MySQL主从复制的基本操作步骤和配置文件示例。
配置主服务器(Master)
修改主服务器(Master)的my.cnf配置文件,开启二进制日志,并设置唯一的服务ID(server-id)。具体配置如下:
[mysqld]
server-id=1
log-bin=mysql-bin
binlog-do-db=<需要复制的数据库名>
其中,server-id为唯一的服务ID号,log-bin用于开启二进制日志功能,binlog-do-db指定需要复制的数据库名。
配置从服务器(Slave)
修改从服务器(Slave)的my.cnf配置文件,设置唯一的服务ID(server-id),并启用slave服务。具体配置如下:
[mysqld]
server-id=2
log-bin=mysql-bin
relay-log=mysql-relay-bin
read-only=1
其中,server-id为唯一的服务ID号,log-bin用于开启二进制日志功能,relay-log用于开启中继日志功能,read-only表示只读模式。
创建复制用户账户
在主服务器上创建一个只有REPLICATION SLAVE权限的账户,并记录该账户的用户名和密码,以供从服务器进行连接和访问。
CREATE USER '<复制用户账户>'@'<从服务器的IP地址>' IDENTIFIED BY '<复制用户账户的密码>';
GRANT REPLICATION SLAVE ON *.* TO '<复制用户账户>'@'<从服务器的IP地址>';
FLUSH PRIVILEGES;
其中,<复制用户账户>是自定义的复制用户账户名,<从服务器的IP地址>是从服务器的IP地址。
启动从服务器复制服务
在从服务器上使用以下命令连接主服务器,并设置需要获取复制数据的二进制日志文件名和位置信息,以及连接主服务器所需的账户名和密码:
CHANGE MASTER TO
MASTER_HOST='<主服务器的IP地址>',
MASTER_USER='<复制用户账户>',
MASTER_PASSWORD='<复制用户账户的密码>',
MASTER_LOG_FILE='<主服务器的二进制日志文件名>',
MASTER_LOG_POS=<主服务器的二进制日志位置>,
MASTER_CONNECT_RETRY=10;
其中,<主服务器的IP地址>是主服务器的IP地址,<复制用户账户>是刚才创建的复制用户账户,<主服务器的二进制日志文件名>和<主服务器的二进制日志位置>是使用SHOW MASTER STATUS命令获取的信息。最后,执行START SLAVE命令启动从服务器的复制服务。
START SLAVE;
[mysqld]
server-id=2
log-bin=mysql-bin
relay-log=mysql-relay-bin
read-only=1
以上就是实现MySQL主从复制的基本操作步骤和配置文件示例。
MySQL主主复制(Master-Master Replication)是指在两个或多个MySQL服务器之间建立双向复制关系,每个服务器既可以作为主服务器,也可以作为从服务器,实现双向数据同步。下面是实现MySQL主主复制的基本操作步骤。
1.配置数据库服务器:在两台或多台MySQL服务器上,分别修改my.cnf文件,设置唯一的服务ID(server-id),并开启二进制日志。
2创建复制用户账户:在所有服务器上创建一个只有REPLICATION SLAVE权限的账户,并记录该账户的用户名和密码,以供其他服务器进行连接和访问。
3.配置主服务器1:在主服务器1上使用以下命令设置从服务器1的相关信息:
CHANGE MASTER TO
MASTER_HOST='<主服务器2的IP地址>',
MASTER_USER='<复制用户账户>',
MASTER_PASSWORD='<复制用户账户的密码>',
MASTER_LOG_FILE='<主服务器2的二进制日志文件名>',
MASTER_LOG_POS=<主服务器2的二进制日志位置>,
MASTER_CONNECT_RETRY=10;
4.配置主服务器2:在主服务器2上使用以下命令设置从服务器2的相关信息:
CHANGE MASTER TO
MASTER_HOST='<主服务器1的IP地址>',
MASTER_USER='<复制用户账户>',
MASTER_PASSWORD='<复制用户账户的密码>',
MASTER_LOG_FILE='<主服务器1的二进制日志文件名>',
MASTER_LOG_POS=<主服务器1的二进制日志位置>,
MASTER_CONNECT_RETRY=10;
5.启动复制服务:在主服务器1和主服务器2上分别执行START SLAVE命令,启动复制服务。
6.测试:在任意一个主服务器上进行数据修改操作,然后在另外一个主服务器上使用SELECT语句检查是否同步成功。
以上就是实现MySQL主主复制的基本操作步骤。需要注意的是,在这种情况下,主服务器之间相互复制的数据可能会出现冲突,因此我们需要采取一些措施,例如设置自增ID,或者使用额外的应用程序实现数据同步冲突的解决。
24. 总结GTID复制原理,并完成GTID复制集群。
GTID(Global Transaction ID)全局事务标识,是从MySQL5.6引入的一种用来标识唯一事务的方式,其原理在于每个事务都有一个唯一的、全局唯一的ID,可以通过这个ID来确定哪些事务已经复制到了从库并且哪些没有。
GTID复制原理很简单,主库在生成新的事务时为其分配一个全局唯一的ID,并将该事务及其ID记录到binlog中。从库在读取主库的binlog时会将其中的GTID信息记录到自己的relay log中,并在执行该事务时将该事务的GTID标记为已经复制完成。之后如果有新的事务产生,从库会通过比较主库和从库的GTID信息来确定哪些事务需要进行复制。
要完成一个GTID复制集群,我们需要按照以下步骤操作:
首先需要在主库和从库上都启用GTID模式。可以在my.cnf文件中设置gtid_mode=ON。
配置主库和从库之间的复制关系,可以使用CHANGE MASTER TO命令或者在my.cnf中指定replication参数。
在主库上创建一个用于从库连接的复制用户,并授予REPLICATION SLAVE权限。
启动从库,并使其连接到主库。
确认主从同步成功。可以通过SHOW SLAVE STATUS命令查看同步状态。
如果需要添加更多的从库,可以重复2-5步骤。在新的从库上启动时需要指定CHANGE MASTER TO语句。
完成以上步骤后,我们就成功搭建了一个GTID复制集群。在该集群中,所有的事务都会被唯一地标识,从而避免了因为复制冲突而导致的数据不一致问题。
25.总结主从复制不一致的原因,如何解决不一致,如何避免不一致
主从复制不一致的原因可以分为以下几种情况:
1.主库和从库之间的网络延迟导致从库无法及时收到更新。这种情况可以通过优化网络环境来解决,例如加速网络带宽或者使用高速网络设备。
2.主库和从库之间的时钟不同步。这种情况可以通过使用时间同步服务来同步主从库之间的时间。
3.在进行主从复制时,可能会出现意外故障,例如主库崩溃或者复制线程异常终止等。这种情况可以通过对主从库进行监控和预警,以便及时发现和解决异常。
4.在主库中进行DDL操作时,由于从库复制的是基于语句的复制方式,可能会导致从库与主库的表结构不一致,从而无法同步数据。这种情况可以使用基于行的复制方式(row-based replication)或者禁止在主库中进行DDL操作来解决。
5.如果主从库所使用的字符集和校对规则不一致,也可能导致数据不一致的情况。这种情况可以通过在主从库之间使用相同的字符集和校对规则来避免。
为了解决主从复制不一致的问题,可以采取以下几种措施:
1.配置主从复制的监控和报警机制,对主从库的状态和数据同步情况进行实时监控。
2.定期备份主库中的数据,并在从库上进行数据恢复验证,确保数据的一致性。
3.避免在主库中进行DDL操作,或者采用基于行的复制方式,以减少不一致的可能性。
4.在主从库之间使用相同的字符集和校对规则,避免由字符集不一致导致的数据不一致情况。
为了避免主从复制不一致的问题,可以采取以下几种措施:
1.使用高速网络设备,提高主从库之间的通信带宽和稳定性。
2.采用基于行的复制方式,避免由语句不一致导致的数据不一致情况。
3.配置主从库的时钟同步服务,确保主从库之间的时间一致。
4.配置监控和报警机制,对主从库的状态和数据同步情况进行实时监控。及时处理异常情况。
26.总结数据库水平拆分和垂直拆分
数据库拆分是指将一个大型的数据库拆成多个小型数据库,以提高数据库性能和可扩展性的一种方法。数据库拆分包括水平拆分和垂直拆分两种方式。
水平拆分:
水平拆分是指把一个表中的数据根据某一规则分散到不同的服务器或节点上,使单个节点的负载得到均衡,也方便水平扩展。通常是按照某个字段的值范围来进行划分,比如按照用户ID、地理位置等,将不同的数据段存储在不同的服务器或节点上,这样可以使查询时只需要操作部分表数据,从而提高查询效率。
优点:
1.提高了数据库的并发处理能力和吞吐量。
2.加强了数据查询的并行度,降低了单节点的压力。
3.方便集群的动态扩容,提高了系统的可伸缩性。
缺点:
1.业务系统需要对分布式环境进行支持,并且必须兼顾数据一致性和事务处理。
2.不同的节点上的数据可能会相互影响,难以进行数据统计和报表查询。
垂直拆分:
垂直拆分是指将一个大型的表拆分为多个小型的表,每个小型的表只包含相关性较强的字段。通常是按照数据表中的列来进行分割,不同的列存储在不同的表中。它的实现方式可以通过对关系型数据库进行嵌套、继承或者视图等技术手段来进行实现。
优点:
1.使数据库中的冗余数据被消除,提高了查询效率。
2.减少了表或记录级别锁的争用,从而提高了并发处理能力。
3.利于对大量数据的备份和还原操作,实现快速的恢复。
缺点:
1.不同表之间的关联需要通过关联查询来实现,增加了查询的成本和时间。
2.难以解决跨表查询的性能问题。
3.可能会导致应用程序的复杂性增加,需要对应用系统进行一定的改造升级。
27.基于mycat实现读写分离
Mycat是一款开源的分布式数据库中间件,可以实现对 MySQL 分片、读写分离、负载均衡等功能。基于 Mycat 实现读写分离可以让查询请求分发到不同的 MySQL 节点上,从而提高数据库的并发能力和性能。
在 Mycat 的配置文件中,需要定义多个数据节点,每个数据节点对应一个 MySQL 实例,其中一个 dataHost 对应一个写节点,多个 dataHost 对应多个读节点。具体配置如下:
<schema name="mydb" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1" />
<!--定义一个dataNode-->
<dataNode name="dn1" dataHost="localhost1" database="hellodb" />
<!--定义一个dataHost: 读写分离-->
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="1"
writeType="0" dbType="mysql" dbDriver="native"
switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<!-- 读库列表 -->
<readHost host="192.168.0.1" url="192.168.0.1:3306"
user="user" password="password" />
<readHost host="192.168.0.2" url="192.168.0.2:3306"
user="user" password="password" />
<!-- 写库列表 -->
<writeHost host="192.168.0.3" url="192.168.0.3:3306"
user="user" password="password" />
</dataHost>
28. 总结mysql高可用方案及高可用级别,搭建MHA集群和galera cluster,尝试搭建TIDB集群。
MySQL高可用方案是指通过使用多种技术手段,确保MySQL数据库的高可用性、可靠性和稳定性,从而保证业务的连续性和稳定性。以下是常见的MySQL高可用方案和高可用级别:
1.主从复制:主从复制是MySQL最常用的高可用方案之一,通过将数据从主库同步到多个从库上,实现读写分离和容灾备份等功能。
2.MHA集群:MHA(Master High Availability)是一个基于主从复制的高可用解决方案,可以自动检测主库故障,将从库提升为新的主库,并重建从库复制关系,从而实现MySQL数据库的自动故障转移。
3.Galera Cluster:Galera Cluster是一个基于同步复制的MySQL高可用解决方案,通过将多个MySQL节点组成一个集群,实现MySQL的自动容错和故障转移。
4.TiDB集群:TiDB是一个分布式数据库,通过将数据分散到多个节点上,实现MySQL的自动故障转移和分布式事务等功能,从而实现MySQL的高可用性和可伸缩性。
以下是搭建MHA集群和Galera Cluster集群的步骤:
搭建MHA集群:首先需要安装MHA软件,并配置MHA的管理节点和MySQL节点信息。在MySQL节点中,需要开启主从复制,并将MHA的脚本复制到节点上。启动MHA的管理节点后,就可以进行主库故障转移的测试和操作。
搭建Galera Cluster集群:首先需要安装Galera Cluster软件,并在所有节点上配置相同的my.cnf文件。在MySQL节点中,需要开启同步复制,并配置Galera Cluster集群的节点信息。在所有节点上启动MySQL服务,就可以组成Galera Cluster集群。
尝试搭建TiDB集群:首先需要安装TiDB软件,并配置TiDB集群的拓扑结构和节点信息。在TiDB集群中,数据分散到多个节点上,每个节点可以同时作为TiDB的组件和MySQL的服务。在所有节点上启动TiDB服务和MySQL服务,就可以组成TiDB集群。
需要注意的是,MySQL高可用方案的选择和搭建需要根据具体的业务需求和数据特点来进行权衡和选择。在搭建集群时,需要注意配置文件的同步、节点的健康检查和容错备份等问题,以确保MySQL的高可用性和可靠性。

29.总结mysql配置最佳实践。
MySQL配置的最佳实践是指通过优化MySQL的配置参数,提高MySQL的性能、可靠性和安全性。以下是MySQL配置的最佳实践:
1.选择合适的存储引擎:MySQL支持多种存储引擎,如InnoDB、MyISAM等,根据实际需求选择合适的存储引擎可以提高MySQL的性能和可靠性。
2.配置缓存和缓冲池:MySQL的缓存和缓冲池可以提高查询的效率和响应速度,需要根据系统的内存和负载情况进行适当的调整和优化。
4.配置日志和复制:MySQL的日志和复制可以提供数据备份和容灾恢复的功能,需要根据业务需求和系统负载进行配置和管理。
5.设置安全参数:MySQL的安全参数可以保护数据库的数据安全和防止黑客攻击,需要设置合适的密码、权限和防火墙等参数。
6.配置优化器和查询缓存:MySQL的优化器和查询缓存可以提高查询的效率和性能,需要根据具体的业务需求和数据特点进行优化和调整。
7.调整线程池和连接池:MySQL的线程池和连接池可以提高系统的并发处理能力和响应速度,需要根据实际负载情况进行调整和优化。
8.监控和诊断工具:MySQL的监控和诊断工具可以实时监测系统的性能和状态,帮助管理员及时发现和解决问题。
需要注意的是,MySQL配置的最佳实践需要根据具体的业务需求和系统特点进行细致的调整和优化,以达到最佳的性能和可靠性。同时,需要定期进行系统的性能测试和评估,及时发现和解决潜在的问题和瓶颈。
30. 总结openvpn原理,并完成1键安装不同版本vpn脚本,可以适配rocky, ubuntu, centos主机。同时支持添加账号,注销账号。
1 2 3 4 5 6 | OpenVPN是一种开源的VPN(虚拟私人网络)解决方案,可以通过使用SSL/TLS协议来保证数据传输的安全性和私密性。以下是OpenVPN的工作原理: OpenVPN使用SSL/TLS协议来建立VPN连接,通过加密传输数据来保护数据的安全性和私密性。 OpenVPN支持多种认证方式,如用户名/密码、证书等,可以根据实际需求进行配置。 OpenVPN通过在本地和远程主机上安装客户端和服务端,实现VPN的建立和数据传输。 OpenVPN可以通过配置文件来定义VPN连接的参数和属性,包括IP地址、端口、加密方式、认证方式等。 OpenVPN可以通过使用桥接或路由模式来连接不同的网络,实现不同网络之间的数据传输。 |
#!/bin/bash
# 安装OpenVPN
if [[ -f /etc/rocky-release ]]; then # 检查Rocky Linux发行版
yum -y install epel-release
yum -y install openvpn
elif [[ -f /etc/centos-release ]]; then # 检查CentOS发行版
yum -y install epel-release
yum -y install openvpn
elif [[ -f /etc/lsb-release ]]; then # 检查Ubuntu发行版
apt-get update
apt-get -y install openvpn
else
echo "不支持的操作系统"
exit 1
fi
# 添加账号
add_user() {
echo "请输入要添加的用户名:"
read username
echo "请输入要添加的密码:"
read password
cd /etc/openvpn/easy-rsa/
. ./vars
./easyrsa build-client-full $username nopass
mkdir -p /etc/openvpn/client-configs/files/$username
cp /etc/openvpn/easy-rsa/pki/ca.crt /etc/openvpn/easy-rsa/pki/issued/$username.crt /etc/openvpn/easy-rsa/pki/private/$username.key /etc/openvpn/client-configs/files/$username/
cat /etc/openvpn/client-configs/make_config.sh | sed "s/USERNAME/$username/g" > /etc/openvpn/client-configs/files/$username/$username.ovpn
sed -i "s/remote my-server-1 1194/remote yourserverip 1194/g" /etc/openvpn/client-configs/files/$username/$username.ovpn
echo -e "$username\t$password" >> /etc/openvpn/creds
echo "已添加用户:$username"
}
# 删除账号
del_user() {
echo "请输入要删除的用户名:"
read username
cd /etc/openvpn/easy-rsa/
. ./vars
./easyrsa --batch revoke $username
./easyrsa gen-crl
rm -f /etc/openvpn/client-configs/files/$username/*
rm -f /etc/openvpn/creds
touch /etc/openvpn/creds
sed -i "/^$username\t/d" /etc/openvpn/creds
echo "已删除用户:$username"
}
# 主菜单
menu() {
echo "请选择操作:"
echo "1. 添加账号"
echo "2. 删除账号"
echo "3. 退出"
read choice
case $choice in
1) add_user;;
2) del_user;;
3) exit;;
*) echo "无效的选择";;
esac
}
# 运行主菜单
while true; do
menu
done

31. 配置LAMP要求 域名使用主从dns, dns解析到2个apache节点,apache和php在同一个节点, mariadb使用mycat读写分离并且要求后端为MHA集群。 架构规划图及解析一次请求和响应的流程和实践过程。
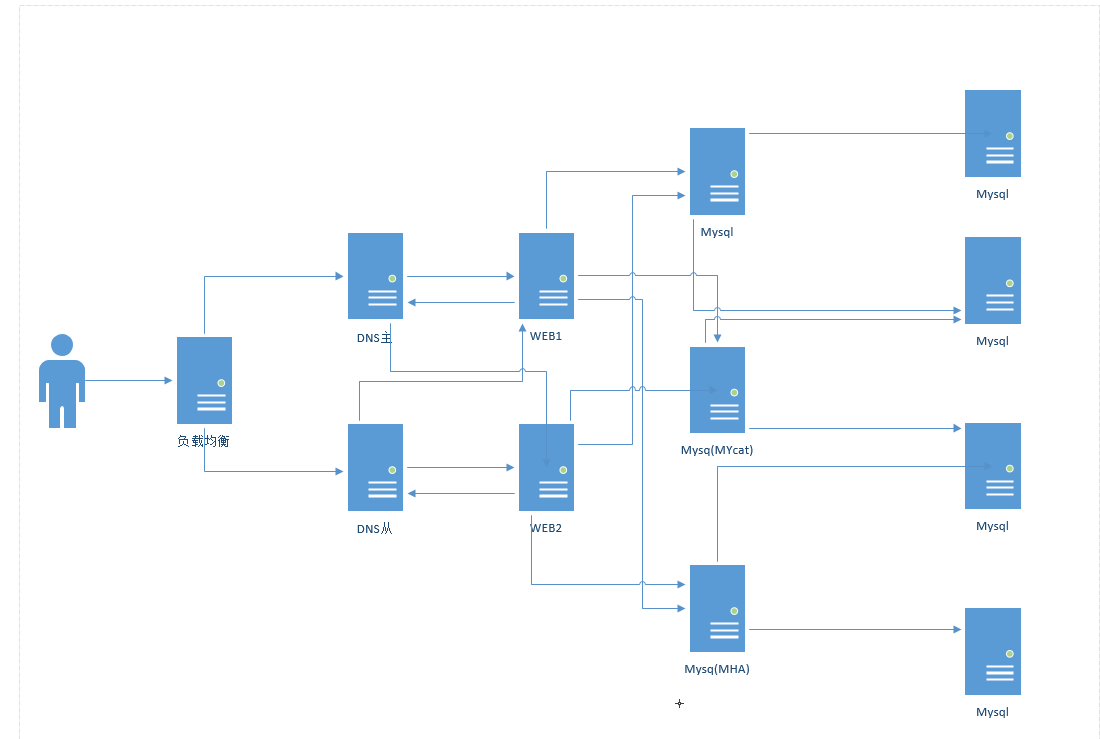
在这个架构中,系统运行了一个LAMP服务器,其中LAMP代表Linux操作系统,Apache web服务器,MySQL/MariaDB数据库和PHP编程语言。域名通过主从DNS服务器进行解析,并且解析到两个Apache web服务器上。Apache和PHP运行在同一个节点上,而MariaDB则使用了MyCat进行读写分离,并且MyCat后端连接到MHA集群。MHA集群由多个MySQL数据库节点组成。
下面是一次请求和响应的流程:
客户端通过域名访问web服务器,发出HTTP请求。
DNS服务器解析域名并返回IP地址。
客户端向web服务器发送HTTP请求。
Apache web服务器接收到请求并将请求转发到后端的MyCat服务器。
MyCat服务器进行读写分离,将读请求转发到MHA集群中的一个MySQL数据库节点进行处理,将写请求转发到主节点上。
MySQL节点接收到读请求并执行查询操作,将查询结果返回到MyCat服务器。
MyCat服务器将查询结果返回给Apache web服务器。
Apache web服务器使用PHP进行动态页面生成,并将结果返回给客户端。
客户端收到HTTP响应并显示结果。
实践过程需要按照以下步骤进行:
安装CentOS 7.9操作系统并进行基本的系统配置。
安装Apache web服务器,PHP编程语言以及MariaDB数据库。
配置MyCat进行读写分离,并将其后端连接到MHA集群。
配置Apache web服务器和PHP运行环境,并将其与MariaDB和MyCat进行集成。
配置主从DNS服务器,并将域名解析到两个Apache web服务器。
对整个系统进行测试和优化,确保其能够正常工作并具有良好的性能。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号