syzkaller 源码分析
-
整体架构
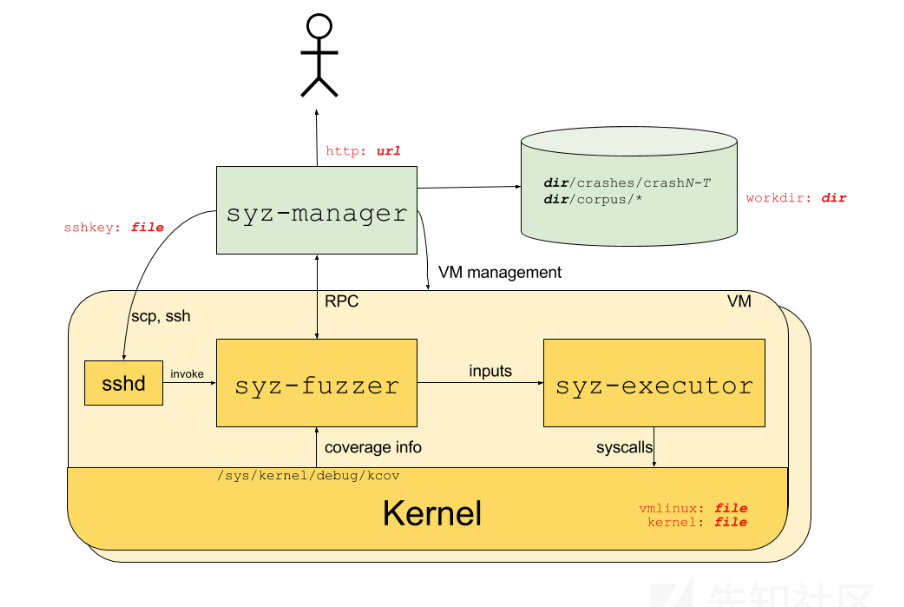
syz-manager 通过 ssh 调用 syz-fuzzer,syz-fuzzer 和 syz-manager 之间通过 RPC 进行通信,syz-fuzzer 将输入传给 syz-executor,syz-executor 执行 syscall(可看作 fuzz 过程中对内核的输入),代码覆盖率等信息由 syz-manager 接收(可看作 fuzz 过程中内核给的反馈)
-
目录结构(部分)
- Godeps:go 的依赖包管理
- dashboard:syzbot 相关(https://syzkaller.appspot.com)
- pkg:配置文件
- ast:解析并格式化 sys 文件
- auth
- bisect:通过二分查找,编译代码测试确定引入含有漏洞代码的 commit 和引入修复的 commit(fuzz 结果后的自动生成 payload 功能?)
- build:包含用于构建内核的辅助函数
- compiler:从文本描述中格式化详细的输出结果
- config:加载配置文件
- cover:提供处理代码覆盖信息的类型
- csource:根据 syzkaller 程序生成等价的 c 程序
- db:存储 syz-manager 和 syz-hub 中的语料库
- debugtracer:增加了新的 debug 接口
- email:解析处理邮件相关功能
- gce:对 Google Compute Engine(GCE) API 的包装
- gcs:对 Google Compute Storage(GCS) API 的包装
- hash:提供 hash 函数
- host:检测 host 是否支持一些特性和特定的系统调用
- html:fuzz 过程中 web 页面的构建
- ifuzz:生成和变异 x86 机器码
- instance:提供用于测试补丁、镜像和二分查找的临时实例的辅助函数
- ipc:用于进程间通信
- kcidb
- kconfig
- kd:windows KD 调试相关
- log:日志功能
- mgrconfig:管理解析配置文件
- osutil:os 和文件操作工具
- report:处理内核输出和检测 / 提取 crash 信息并符号化等
- repro:对 crash 进行复现并进行相关的处理
- rpctype:包含通过系统各部分之间的 net / rpc 连接传递的消息类型
- runtest:syzkaller 端到端测试的驱动程序
- serializer:序列化处理
- signal:提供用于处理发聩信号的类型
- stats
- symbolizer:处理符号相关信息
- testutil
- tool
- tools
- vcs:各种库的辅助函数
- prog:目标系统相关信息以及需要执行的系统调用
- sys:系统调用描述,这里涉及到 syskaller 用自己的声明式语言来描述系统调用的模板。处理过程需要经过两个步骤:
- 用 syz-extract 从 linux 源码中提取符号常量的值,并存到对应的 .const 文件中
- 用 syz-sysgen 生成 syzkaller 用的 go 代码
- syz-cl:持续运行 syzkaller 的系统
- syz-fuzzer:三大组件之一
- syz-hub:将多个 syz-manager 连接在一起并运行它们交换程序
- syz-manager:三大组件之一
- syz-runner
- syz-verifier
- tools:封装 pkg 中的接口,包括 fuzz 过程中的一些辅助工具
- vendor:依赖包
- vm:提供 vm 接口
-
syz-manager
首先是对配置文件的解析,相关代码在 config.go 中,
http:显示正在运行的syz-manager进程信息的URL
email_addrs:第一次出现bug时接收通知的电子邮件地址
workdir:syz-manager进程的工作目录的位置,产生的文件包括:
- crashes:crash 输出文件
- corpus.db:一些程序的语料库
- instance-x:每个 VM 实例临时文件
syzkaller:syzkalle r的位置,syz-manager 将在 bin 子目录中查找二进制文件
kernel_obj:包含目标文件的目录,例如 linux 中的 vmlinuxprocs:每个 VM 中的并行测试进程数,一般是 4 或 8
image:qemu 实例的磁盘镜像文件的位置
sshkey:用于与虚拟机通信的 SSH 密钥的位置
sandbox:沙盒模式,支持以下模式:
- none:默认设置,不做任何特殊的事情
- setuid:冒充用户nobody(65534)
- namespace:使用命名空间删除权限(内核需要使用 CONFIG_NAMESPACES,CONFIG_UTS_NS,CONFIG_USER_NS,CONFIG_PID_NS 和 CONFIG_NET_NS 构建)
enable_syscalls:测试的系统调用列表
disable_syscalls:禁用的系统调用列表
suppressions:已知错误的正则表达式列表
type:要使用的虚拟机类型,例如 qemu
vm:特定 VM 类型相关的参数(对于 qemu 来说就是 qemu 的启动参数)
除此之外还有一些方便显示的参数(位于 manager.go)
var ( flagConfig = flag.String("config", "", "configuration file") flagDebug = flag.Bool("debug", false, "dump all VM output to console") flagBench = flag.String("bench", "", "write execution statistics into this file periodically") )然后看 main 函数的执行部分:
func main() { if prog.GitRevision == "" { log.Fatalf("bad syz-manager build: build with make, run bin/syz-manager") } flag.Parse() log.EnableLogCaching(1000, 1<<20) // 开启日志缓存 cfg, err := mgrconfig.LoadFile(*flagConfig) // 加载 config 文件 if err != nil { log.Fatalf("%v", err) } RunManager(cfg) }config 文件继续在 RunManager 中被解析:
func RunManager(cfg *mgrconfig.Config) { var vmPool *vm.Pool if cfg.Type != "none" { // type 为 none,需要手动启动 VM var err error vmPool, err = vm.Create(cfg, *flagDebug) // 创建 vmPool if err != nil { log.Fatalf("%v", err) } } crashdir := filepath.Join(cfg.Workdir, "crashes") osutil.MkdirAll(crashdir) reporter, err := report.NewReporter(cfg) if err != nil { log.Fatalf("%v", err) } mgr := &Manager{ ... } mgr.preloadCorpus() mgr.initStats() // Initializes prometheus variables. mgr.initHTTP() // Creates HTTP server. mgr.collectUsedFiles() // Create RPC server for fuzzers. mgr.serv, err = startRPCServer(mgr) if err != nil { log.Fatalf("failed to create rpc server: %v", err) } if cfg.DashboardAddr != "" { ... } go func() { // 作为 fuzz 的 manager,在这里新开线程记录 VM 状态和 crash 等信息 for lastTime := time.Now(); ; { time.Sleep(10 * time.Second) now := time.Now() diff := now.Sub(lastTime) lastTime = now mgr.mu.Lock() if mgr.firstConnect.IsZero() { mgr.mu.Unlock() continue } mgr.fuzzingTime += diff * time.Duration(atomic.LoadUint32(&mgr.numFuzzing)) executed := mgr.stats.execTotal.get() crashes := mgr.stats.crashes.get() corpusCover := mgr.stats.corpusCover.get() corpusSignal := mgr.stats.corpusSignal.get() maxSignal := mgr.stats.maxSignal.get() mgr.mu.Unlock() numReproducing := atomic.LoadUint32(&mgr.numReproducing) numFuzzing := atomic.LoadUint32(&mgr.numFuzzing) log.Logf(0, "VMs %v, executed %v, cover %v, signal %v/%v, crashes %v, repro %v", numFuzzing, executed, corpusCover, corpusSignal, maxSignal, crashes, numReproducing) } }() if *flagBench != "" { // 如果设置了 bench 参数,还要在它指定的文件中记录一些信息 f, err := os.OpenFile(*flagBench, os.O_WRONLY|os.O_CREATE|os.O_EXCL, osutil.DefaultFilePerm) if err != nil { log.Fatalf("failed to open bench file: %v", err) } go func() { for { time.Sleep(time.Minute) vals := mgr.stats.all() mgr.mu.Lock() if mgr.firstConnect.IsZero() { mgr.mu.Unlock() continue } mgr.minimizeCorpus() vals["corpus"] = uint64(len(mgr.corpus)) vals["uptime"] = uint64(time.Since(mgr.firstConnect)) / 1e9 vals["fuzzing"] = uint64(mgr.fuzzingTime) / 1e9 mgr.mu.Unlock() data, err := json.MarshalIndent(vals, "", " ") if err != nil { log.Fatalf("failed to serialize bench data") } if _, err := f.Write(append(data, '\n')); err != nil { log.Fatalf("failed to write bench data") } } }() } if mgr.dash != nil { go mgr.dashboardReporter() } osutil.HandleInterrupts(vm.Shutdown) if mgr.vmPool == nil { log.Logf(0, "no VMs started (type=none)") log.Logf(0, "you are supposed to start syz-fuzzer manually as:") log.Logf(0, "syz-fuzzer -manager=manager.ip:%v [other flags as necessary]", mgr.serv.port) <-vm.Shutdown return } mgr.vmLoop() // 调用 vmLoop,进入总体架构的下一层 }vmLoop 将 VM 实例分为两部分,一部分用于 crash 的复现,另一部分用于 fuzz。用 reproQueue 保存 crash,instances 优先用于复现 crash
func (mgr *Manager) vmLoop() { ... canRepro := func() bool { // 判断当前是否有可复现的 crash return phase >= phaseTriagedHub && len(reproQueue) != 0 && (int(atomic.LoadUint32(&mgr.numReproducing))+1)*instancesPerRepro <= maxReproVMs } if shutdown != nil { for canRepro() { // 优先复现 crash vmIndexes := instances.Take(instancesPerRepro) if vmIndexes == nil { break } last := len(reproQueue) - 1 crash := reproQueue[last] reproQueue[last] = nil reproQueue = reproQueue[:last] atomic.AddUint32(&mgr.numReproducing, 1) log.Logf(1, "loop: starting repro of '%v' on instances %+v", crash.Title, vmIndexes) go func() { reproDone <- mgr.runRepro(crash, vmIndexes, instances.Put) }() } for !canRepro() { // 没有的话就继续 fuzz idx := instances.TakeOne() if idx == nil { break } log.Logf(1, "loop: starting instance %v", *idx) go func() { // 启动 fuzz,监控信息并返回 Report 对象 crash, err := mgr.runInstance(*idx) runDone <- &RunResult{*idx, crash, err} }() } } ... }跟进 crash 的复现过程,调用链为:
mgr.runRepro -> repro.Run -> ctx.repro重点看 repro 函数(位于 pkg/repro/repro.go),主要函数包括:
- ctx.extractProg() 提取出触发 crash 的程序
- ctx.minimizeProg() 若成功复现则简化调用和参数
- ctx.extractC() 生成 c 代码并编译,执行并检查是否 crash
- ctx.simplifyProg() 用定义好的简化规则进一步简化,如果简化后还能触发 crash,则再调用 extractC 尝试提取 C repro
- ctx.simplifyC() 对提取处的 C 程序进一步简化
接着分析启动 fuzz 的具体过程,调用链为:
vmLoop() -> mgr.runInstance() -> mgr.runInstanceInner()关键部分位于 syz-manager/manager.go#runInstanceInner 中
-
inst.Copy(mgr.cfg.FuzzerBin) 将 syz-fuzzer 复制到 VM 中
-
inst.Copy(mgr.cfg.ExecutorBin) 将 syz-fuzzer 复制到 VM 中
-
instance.FuzzerCmd() 构造好命令,通过 ssh 执行 syz-fuzzer
# fuzz命令示例 /syz-fuzzer -executor=/syz-executor -name=vm-0 -arch=amd64 -manager=10.0.2.10:33185 -procs=1 -leak=false -cover=true -sandbox=none -debug=true -v=100 -
inst.MonitorExecution() 监控内核信息
-
syz-fuzzer
根据文件系统中的 /sys/kernel/debug/kcov 获取内核代码覆盖率,生成新的变异数据并传给 syz-executor。
首先看 fuzzer.go#main
func main() { debug.SetGCPercent(50) // 解析 syz-manager 传入的参数 var ( flagName = flag.String("name", "test", "unique name for manager") flagOS = flag.String("os", runtime.GOOS, "target OS") flagArch = flag.String("arch", runtime.GOARCH, "target arch") flagManager = flag.String("manager", "", "manager rpc address") flagProcs = flag.Int("procs", 1, "number of parallel test processes") flagOutput = flag.String("output", "stdout", "write programs to none/stdout/dmesg/file") flagTest = flag.Bool("test", false, "enable image testing mode") // used by syz-ci flagRunTest = flag.Bool("runtest", false, "enable program testing mode") // used by pkg/runtest flagRawCover = flag.Bool("raw_cover", false, "fetch raw coverage") ) ... manager, err := rpctype.NewRPCClient(*flagManager, timeouts.Scale) // 初始化 RPC 协议,后面就通过 RPC 远程调用 rpc.go 中的接口 if err != nil { log.Fatalf("failed to connect to manager: %v ", err) } ... if err := manager.Call("Manager.Connect", a, r); err != nil { // 连接 RPC log.Fatalf("failed to connect to manager: %v ", err) } ... if err := manager.Call("Manager.Check", r.CheckResult, nil); err != nil { // 调用链 rpc.go#Check() -> serv.mgr.machineChecked() -> mgr.loadCorpus() 将 db 中所有的语料库加载到 mgr.candidates log.Fatalf("Manager.Check call failed: %v", err) } ... for needCandidates, more := true, true; more; needCandidates = false { more = fuzzer.poll(needCandidates, nil) // 在 poll 中更新 fuzzer.corpus 语料库以及 fuzzer.workQueue 队列 // This loop lead to "no output" in qemu emulation, tell manager we are not dead. log.Logf(0, "fetching corpus: %v, signal %v/%v (executing program)", len(fuzzer.corpus), len(fuzzer.corpusSignal), len(fuzzer.maxSignal)) } ... fuzzer.choiceTable = target.BuildChoiceTable(fuzzer.corpus, calls) // 生成 prios[X][Y] 优先级,预测在包含系统调用 X 的程序中添加系统调用 Y 是否能得到新的覆盖(syzkaller 的核心思想) ... log.Logf(0, "starting %v fuzzer processes", *flagProcs) for pid := 0; pid < *flagProcs; pid++ { // flagProcs -- 表示每个 VM 中的并行测试进程数(由 config 文件中的参数决定) proc, err := newProc(fuzzer, pid) if err != nil { log.Fatalf("failed to create proc: %v", err) } fuzzer.procs = append(fuzzer.procs, proc) go proc.loop() // fuzz 的核心变异部分,如果由剩余的 Procs,就开启新的线程执行此函数 } fuzzer.pollLoop() // 循环等待,如果程序需要新的语料库,就调用 poll() 生成新的数据 }poll:
func (fuzzer *Fuzzer) poll(needCandidates bool, stats map[string]uint64) bool { a := &rpctype.PollArgs{ Name: fuzzer.name, NeedCandidates: needCandidates, MaxSignal: fuzzer.grabNewSignal().Serialize(), Stats: stats, } r := &rpctype.PollRes{} if err := fuzzer.manager.Call("Manager.Poll", a, r); err != nil { // RPC 远程调用,获取 mgr.candidates 并存入 r.Candidates log.Fatalf("Manager.Poll call failed: %v", err) } maxSignal := r.MaxSignal.Deserialize() // 获得最大信号量 log.Logf(1, "poll: candidates=%v inputs=%v signal=%v", len(r.Candidates), len(r.NewInputs), maxSignal.Len()) fuzzer.addMaxSignal(maxSignal) // 对已经存在的 sign 比较优先级,对没有的 sign 直接添加 for _, inp := range r.NewInputs { // 更新 corpusSognal 和 maxSignal fuzzer.addInputFromAnotherFuzzer(inp) // 更新 fuzzer.corpus } for _, candidate := range r.Candidates { fuzzer.addCandidateInput(candidate) // 从 r.Candidates 提取出程序,并加入到 fuzzer.workQueue } if needCandidates && len(r.Candidates) == 0 && atomic.LoadUint32(&fuzzer.triagedCandidates) == 0 { atomic.StoreUint32(&fuzzer.triagedCandidates, 1) } return len(r.NewInputs) != 0 || len(r.Candidates) != 0 || maxSignal.Len() != 0 }然后会调用 BuildChoiceTable 计算优先级,其中的 prios[X][Y] 是对在包含系统调用 X 的程序中添加系统调用 Y 是否可能得到新的覆盖的猜测。
func (target *Target) BuildChoiceTable(corpus []*Prog, enabled map[*Syscall]bool) *ChoiceTable { if enabled == nil { enabled = make(map[*Syscall]bool) for _, c := range target.Syscalls { // 判断这个 syscall 是否是 enabled enabled[c] = true } } for call := range enabled { if call.Attrs.Disabled { // 判断是不是在配置中被 ban 掉了 delete(enabled, call) } } var enabledCalls []*Syscall for c := range enabled { enabledCalls = append(enabledCalls, c) } if len(enabledCalls) == 0 { panic("no syscalls enabled") } sort.Slice(enabledCalls, func(i, j int) bool { return enabledCalls[i].ID < enabledCalls[j].ID // 把可用的 syscall 赋值到 enabledCalls,并按 ID 大小进行排序 }) for _, p := range corpus { for _, call := range p.Calls { if !enabled[call.Meta] { fmt.Printf("corpus contains disabled syscall %v\n", call.Meta.Name) panic("disabled syscall") } } } prios := target.CalculatePriorities(corpus) // 根据剩下的 corpus 计算 prios[X][Y] 优先级 // 下面这一部分式根据之前计算的 prios 和启用的 syscall,计算出 run 表 // 对系统调用 i/j 来说,run[i][j] 的值是之前 run[i][x](x<j)的和加上 prios[i][j],所以对 run[X] 来说就是从小到大排好序的 run := make([][]int32, len(target.Syscalls)) for i := range run { if !enabled[target.Syscalls[i]] { continue } run[i] = make([]int32, len(target.Syscalls)) var sum int32 for j := range run[i] { if enabled[target.Syscalls[j]] { sum += prios[i][j] } run[i][j] = sum } } return &ChoiceTable{target, run, enabledCalls} }预测部分 CalculatePriorities 由静态和动态两个组件构成,
func (target *Target) CalculatePriorities(corpus []*Prog) [][]int32 { static := target.calcStaticPriorities() if len(corpus) != 0 { dynamic := target.calcDynamicPrio(corpus) for i, prios := range dynamic { dst := static[i] for j, p := range prios { dst[j] = dst[j] * p / prioHigh } } } return static }首先看静态组件,如果两个系统调用接受相同的参数,则更可能出现新的覆盖。
func (target *Target) calcStaticPriorities() [][]int32 { uses := target.calcResourceUsage() // 创建 hash 表,key 是 string,表示某种资源;value 也是 hash 表,对应(id,value) // 资源是通过遍历函数参数得到的,每种类型的资源的权重不通,同一种资源的同一个系统调用只会记录最大的值 prios := make([][]int32, len(target.Syscalls)) for i := range prios { prios[i] = make([]int32, len(target.Syscalls)) } for _, weights := range uses { for _, w0 := range weights { for _, w1 := range weights { if w0.call == w1.call { // Self-priority is assigned below. continue } // The static priority is assigned based on the direction of arguments. A higher priority will be // assigned when c0 is a call that produces a resource and c1 a call that uses that resource. // 计算 prios 的值(跳过自身) // 翻译:优先级的值基于参数方向,如果 c0 产生资源而 c1 使用资源,那么 c1 会由更高的优先级 prios[w0.call][w1.call] += w0.inout*w1.in*3/2 + w0.inout*w1.inout } } } normalizePrio(prios) // 对 prios 进行规范化处理,使优先级的值落在区间 [prioLow, prioHigh] 这个区间内(默认 10-1000) // The value assigned for self-priority (call wrt itself) have to be high, but not too high. for c0, pp := range prios { // 把 prios[c0][c0] 这种情况赋予一个较高的优先级 pp[c0] = prioHigh * 9 / 10 } return prios }动态组件,单个程序中两个 syscall 一起出现的频率越高越可能出现新的覆盖(why???)
func (target *Target) calcDynamicPrio(corpus []*Prog) [][]int32 { prios := make([][]int32, len(target.Syscalls)) for i := range prios { prios[i] = make([]int32, len(target.Syscalls)) } for _, p := range corpus { // 如果语料库中一对系统调用一起出现,则计数 +1 for idx0, c0 := range p.Calls { for _, c1 := range p.Calls[idx0+1:] { prios[c0.Meta.ID][c1.Meta.ID]++ } } } normalizePrio(prios) // 规范化 return prios }loop:fuzz 的核心部分,有空余的线程就可以执行,负责生成新的程序和变异
func (proc *Proc) loop() { generatePeriod := 100 if proc.fuzzer.config.Flags&ipc.FlagSignal == 0 { // If we don't have real coverage signal, generate programs more frequently // because fallback signal is weak. generatePeriod = 2 // 值越小,生成频率越高 } for i := 0; ; i++ { item := proc.fuzzer.workQueue.dequeue() // 遍历 fuzz.workQueue 队列,放到 item 中,对三种不同类型的 item,分别用不同的函数处理 if item != nil { switch item := item.(type) { case *WorkTriage: // 第一次执行时,检查是否产生了新的覆盖,如果有新的覆盖的话则 Minimize 并添加到新的语料库中 proc.triageInput(item) case *WorkCandidate: // 来自 hub 的程序,不知道对当前的 fuzzer 是否有效,proc 处理它们的方式跟本地生成或变异出的程序相同 proc.execute(proc.execOpts, item.p, item.flags, StatCandidate) case *WorkSmash: // 对于刚加入到语料库中的程序,执行 hint 变异、 proc.smashInput(item) default: log.Fatalf("unknown work type: %#v", item) } continue } ct := proc.fuzzer.choiceTable // 存储 prios[X][Y] 优先级 fuzzerSnapshot := proc.fuzzer.snapshot() // 保存快照 if len(fuzzerSnapshot.corpus) == 0 || i%generatePeriod == 0 { // 生成新的 proc // Generate a new prog. p := proc.fuzzer.target.Generate(proc.rnd, prog.RecommendedCalls, ct) // 如果 corpus 为空,就必须要随机生成新的程序 log.Logf(1, "#%v: generated", proc.pid) proc.executeAndCollide(proc.execOpts, p, ProgNormal, StatGenerate) } else { // 不生成新的,对之前的程序进行变异 // Mutate an existing prog. p := fuzzerSnapshot.chooseProgram(proc.rnd).Clone() p.Mutate(proc.rnd, prog.RecommendedCalls, ct, fuzzerSnapshot.corpus) // 对现有的 syscall 进行变异 log.Logf(1, "#%v: mutated", proc.pid) proc.executeAndCollide(proc.execOpts, p, ProgNormal, StatFuzz) } } }triageInput:
func (proc *Proc) triageInput(item *WorkTriage) { log.Logf(1, "#%v: triaging type=%x", proc.pid, item.flags) prio := signalPrio(item.p, &item.info, item.call) inputSignal := signal.FromRaw(item.info.Signal, prio) newSignal := proc.fuzzer.corpusSignalDiff(inputSignal) // 检查是否存在新的 signal,不存在就直接返回 if newSignal.Empty() { return } ... // Compute input coverage and non-flaky signal for minimization. notexecuted := 0 rawCover := []uint32{} for i := 0; i < signalRuns; i++ { info := proc.executeRaw(proc.execOptsCover, item.p, StatTriage) // 获得执行信息的 info if !reexecutionSuccess(info, &item.info, item.call) { // The call was not executed or failed. notexecuted++ if notexecuted > signalRuns/2+1 { return // if happens too often, give up } continue } thisSignal, thisCover := getSignalAndCover(item.p, info, item.call) // 获取信号量信息和覆盖率信息 if len(rawCover) == 0 && proc.fuzzer.fetchRawCover { rawCover = append([]uint32{}, thisCover...) } newSignal = newSignal.Intersection(thisSignal) // Without !minimized check manager starts losing some considerable amount // of coverage after each restart. Mechanics of this are not completely clear. if newSignal.Empty() && item.flags&ProgMinimized == 0 { return } inputCover.Merge(thisCover) } if item.flags&ProgMinimized == 0 { // 对程序和 call 进行 Minimize item.p, item.call = prog.Minimize(item.p, item.call, false, func(p1 *prog.Prog, call1 int) bool { for i := 0; i < minimizeAttempts; i++ { info := proc.execute(proc.execOpts, p1, ProgNormal, StatMinimize) if !reexecutionSuccess(info, &item.info, call1) { // The call was not executed or failed. continue } thisSignal, _ := getSignalAndCover(p1, info, call1) if newSignal.Intersection(thisSignal).Len() == newSignal.Len() { return true } } return false }) } data := item.p.Serialize() // 序列化并生成 hash sig := hash.Hash(data) log.Logf(2, "added new input for %v to corpus:\n%s", logCallName, data) proc.fuzzer.sendInputToManager(rpctype.Input{ // 将新的覆盖、信号等信息发送给 syz-manager Call: callName, CallID: item.call, Prog: data, Signal: inputSignal.Serialize(), Cover: inputCover.Serialize(), RawCover: rawCover, }) proc.fuzzer.addInputToCorpus(item.p, inputSignal, sig) // 保存到语料库中 if item.flags&ProgSmashed == 0 { proc.fuzzer.workQueue.enqueue(&WorkSmash{item.p, item.call}) } }execute,依次调用 proc.execute()
->proc.executeRaw()->proc.env.Exec()->env.cmd.exec(),最后把数据传给 executor 执行func (proc *Proc) execute(execOpts *ipc.ExecOpts, p *prog.Prog, flags ProgTypes, stat Stat) *ipc.ProgInfo { info := proc.executeRaw(execOpts, p, stat) if info == nil { return nil } calls, extra := proc.fuzzer.checkNewSignal(p, info) // 检查有没有新的 call for _, callIndex := range calls { proc.enqueueCallTriage(p, flags, callIndex, info.Calls[callIndex]) // 把新的 call 加入到 fuzzer.workQueue 中 } if extra { proc.enqueueCallTriage(p, flags, -1, info.Extra) } return info }smashInput,处理刚加入到语料库中的程序,采用 syscall 中的比较操作数,来对参数进行变异(hint 策略)
func (proc *Proc) smashInput(item *WorkSmash) { if proc.fuzzer.faultInjectionEnabled && item.call != -1 { proc.failCall(item.p, item.call) // 如果测试过程中注入错误, 再调用 executeRaw 执行 } if proc.fuzzer.comparisonTracingEnabled && item.call != -1 { proc.executeHintSeed(item.p, item.call) // hint 变异的主要实现过程 } fuzzerSnapshot := proc.fuzzer.snapshot() // 保存快照 for i := 0; i < 100; i++ { // 执行 100 次的变异 + 执行 p := item.p.Clone() p.Mutate(proc.rnd, prog.RecommendedCalls, proc.fuzzer.choiceTable, fuzzerSnapshot.corpus) log.Logf(1, "#%v: smash mutated", proc.pid) proc.executeAndCollide(proc.execOpts, p, ProgNormal, StatSmash) } }hint 变异(在 /syz-fuzzer/proc.go: executeHintSeed() 中实现),由一个指向 syscall 的一个参数指针和一个 value 组成,该值要赋给该参数(replacer),实现流程:
- fuzzer 启动一个程序(hint seed)并收集这个程序中每一个 syscall 的比较数据(KCOV_MODE_TRACE_CMP 模式来收集)
- fuzzer 尝试把获得的比较操作数与输入的参数值进行匹配
- 对于每一对匹配成功的值,fuzzer 用保存的值来替换对应的指针,以此达到变异的效果。
- 如果获得的程序有效,就用 fuzzer 启动它,并检查有没有新的覆盖情况
func (proc *Proc) executeHintSeed(p *prog.Prog, call int) { log.Logf(1, "#%v: collecting comparisons", proc.pid) // First execute the original program to dump comparisons from KCOV. info := proc.execute(proc.execOptsComps, p, ProgNormal, StatSeed) // 执行原始程序,收集比较操作数 if info == nil { return } // 再对初始程序的每一个可以匹配成功的系统调用参数和比较操作数进行变异。执行每一次变异后的程序, 检查是否出现新的覆盖 // info.Calls[call].Comps 是每个 syscall 的比较操作数(map[uint64]map[uint64]bool) // 第三个 func 用来执行程序 p.MutateWithHints(call, info.Calls[call].Comps, func(p *prog.Prog) { log.Logf(1, "#%v: executing comparison hint", proc.pid) proc.execute(proc.execOpts, p, ProgNormal, StatHint) }) }比较操作数示例:前面的值为 key,后面的值 + true 为 value
// Example: for comparisons {(op1, op2), (op1, op3), (op1, op4), (op2, op1)} // this map will store the following: // m = { // op1: {map[op2]: true, map[op3]: true, map[op4]: true}, // op2: {map[op1]: true} // }具体的变异部分可参考 hints_test.go#TestHintsCheckConstArg。
Generate 可用于生成有 n 个 syscall 的程序(/prog/generation.go#Generate)
func (target *Target) Generate(rs rand.Source, ncalls int, ct *ChoiceTable) *Prog { p := &Prog{ Target: target, } r := newRand(target, rs) s := newState(target, ct, nil) for len(p.Calls) < ncalls { // 根据基准 syscall 和 run 表随机选择一个 syscall,并生成具体的系统调用和相应参数 // 相应参数的生成是由数据类型对应的 generate 函数决定 calls := r.generateCall(s, p, len(p.Calls)) for _, c := range calls { s.analyze(c) // 对 syscall 进行分析并对相应的类型做相应的处理 p.Calls = append(p.Calls, c) } } // For the last generated call we could get additional calls that create // resources and overflow ncalls. Remove some of these calls. // The resources in the last call will be replaced with the default values, // which is exactly what we want. for len(p.Calls) > ncalls { p.RemoveCall(ncalls - 1) // 超过了就移除多余的 } p.sanitizeFix() // 合法性检测 p.debugValidate() return p }Mutate() 变异过程,不同于 MutateWithHints() 的匹配替换,这里的变异类似 AFL 的随机化变异(/prog/mutation.go)
- squashAny() 压缩参数
- splice() 拼接,随机选择一个语料库外的程序 p0,选一个随机数 i,插入到程序 ctx.p 的第i条指令后面
- insertCall() 随机位置插入一个 syscall
- mutateArg() 对一个随机 syscall 的参数进行变异
- removeCall() 随机移除一个 syscall
-
fuzz-executor
参照 executor/common_linux.h 中的 do_sandbox_no,调用链为:
do_sandbox_none() -> loop() -> execute_one() -> schedule_call() -> thread_create() -> thread_start() -> worker_thread() -> execute_call() -> execute_syscall()最后被执行并获得代码覆盖率等信息。
-
参考文献

 浙公网安备 33010602011771号
浙公网安备 33010602011771号